
Unite Shanghai 2024 团结引擎专场 | 团结引擎小游戏开发指南
首先,我们分享两个实际案例的测试数据,看看团结针对小游戏的优化效果。接下来,针对小游戏开发过程中的各个阶段,逐个分析。首先会看小游戏平台适配有哪些需要注意的地方:新开发的小游戏或者原生app转的小游戏,都会遇到这个问题。接下来是启动加载的优化,小游戏即点即玩,玩家期望游戏拉起的越快越好,启动越快玩家的首屏留存率越高。然后是游戏内容的边下边玩。游戏内容越来越丰富,资产体积越来越大。这些资产不可能都在
在 Unite Shanghai 2024 团结引擎专场演讲中, Unity中国引擎底层架构技术主管兼小游戏技术负责人赵亮、Unity 中国技术经理傅有成带来演讲《团结引擎小游戏开发指南》,介绍了如何使用团结引擎高效地开发、加载更迅速、内容更丰富、画面更精致、运行更流畅的小游戏。
赵亮:大家好,我是赵亮,欢迎大家来到 Unite 大会,今天由我和我的同事傅有成一起跟大家分享:如何使用团结引擎开发内容更丰富、画质更精美的微信小游戏。

开发者对使用 Unity 开发微信小游戏已经越来越熟悉了,已有超过 3000 款 Unity 游戏在微信小游戏平台发布。其中不乏很多优秀的作品,例如:《无尽冬日》、《向僵尸开炮》、《诛仙手游》小游戏、《最强祖师》、《巨兽战场》等等。小游戏正在从 2D、轻度、超休闲,逐步向 3D、中重度、高画质发展。
团结在 Unity 的基础上,与微信深度合作,将小游戏作为一个专门的平台进行深入优化,不断开发新的功能,致力于提升小游戏品质的天花板。刚刚提到的《无尽冬日》、《诛仙手游》小游戏、《最强祖师》都使用了团结的优化。相信随着我们和开发者的共同努力,未来会打造出更多高品质的小游戏。
下面介绍一下今天的 agenda:
首先,我们分享两个实际案例的测试数据,看看团结针对小游戏的优化效果。
接下来,针对小游戏开发过程中的各个阶段,逐个分析。
-
首先会看小游戏平台适配有哪些需要注意的地方:新开发的小游戏或者原生app转的小游戏,都会遇到这个问题。
-
接下来是启动加载的优化,小游戏即点即玩,玩家期望游戏拉起的越快越好,启动越快玩家的首屏留存率越高。
-
然后是游戏内容的边下边玩。游戏内容越来越丰富,资产体积越来越大。这些资产不可能都在游戏启动前下载完毕,需要伴随游戏的进程边下边玩、按需下载。这里会介绍相关的工具,以及注意的事项。
-
然后是内存。小游戏品质越来越高,内容更加丰富/画质更加精美,对内存的需求也越来越大。引擎需要对内存的使用,进行更极致的优化,从而让出更多内存给到游戏内容。
-
然后是运行性能。由于小游戏目前还是单线程 且 WASM运行效率比原生App低。因此需要着重优化,才能保持游戏的流畅度,避免卡顿、发热、降频等。
-
接下来会介绍开发效率相关的内容。小游戏节奏快,开发时间短,提升开发效率非常重要。我们会介绍相关工具以及引擎的优化。
最后,向大家介绍一下我们目前正在开发的功能以及未来的 roadmap。
游戏案例
首先向大家介绍两个 MMO 的案例,游戏内容都比较重度。一个是完美世界的《诛仙手游》小游戏,另一个游戏名称尚未公开。

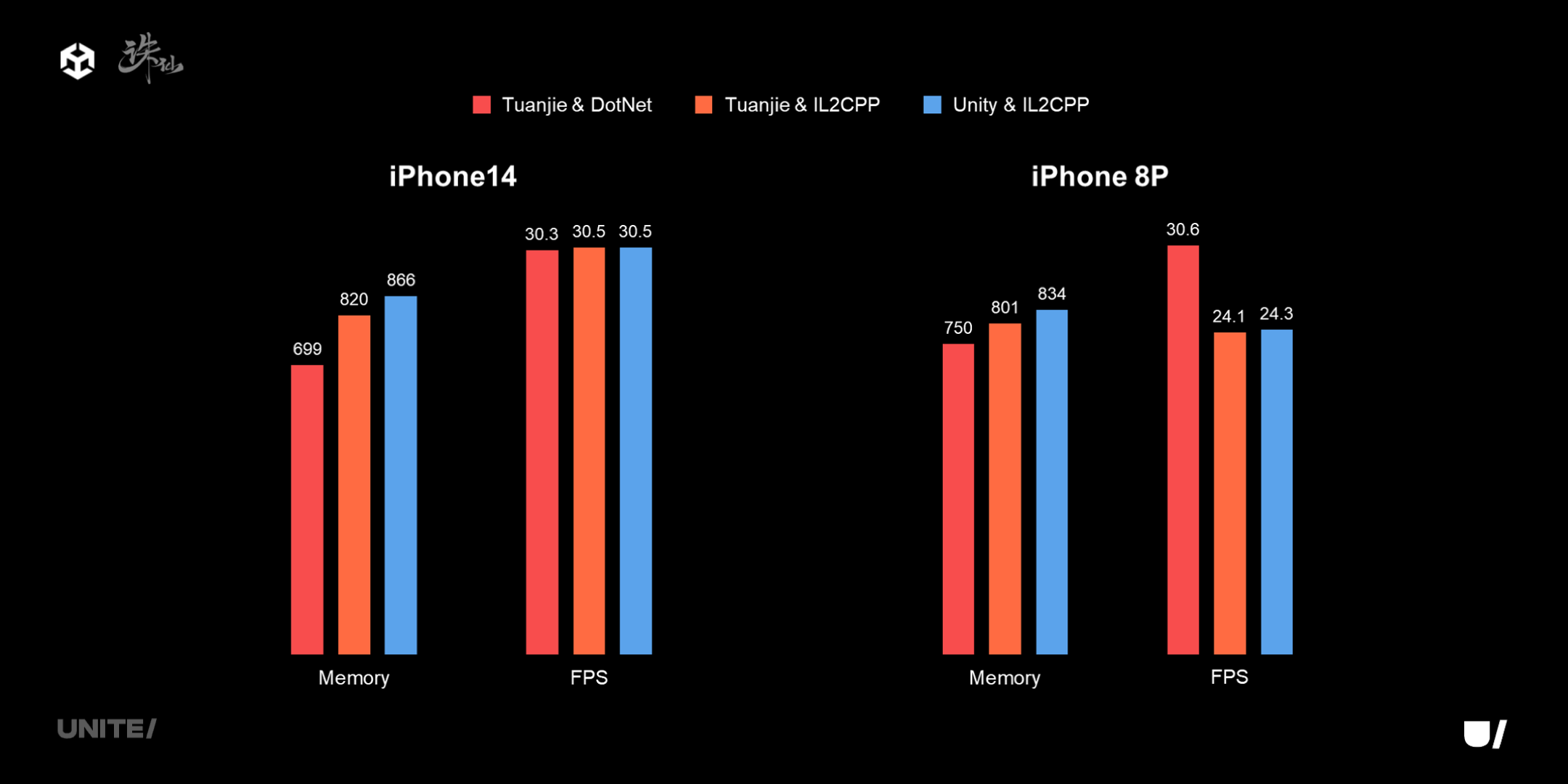
《诛仙手游》小游戏是从手游版本移植过来的,上图左侧展示的是 App 效果,还有小游戏的录屏对比。可以看到《诛仙手游》小游戏版本的画质与 App 相比差别已经很小。《诛仙手游》小游戏版本在 iPhone 8 Plus 可以稳定在 30 帧,连续打两个小时副本也不会 oom。
下图是《诛仙手游》小游戏在主城里进行的多角色压力测试的结果。从数据可以看出,团结在内存和 FPS 上都有了显著提升。
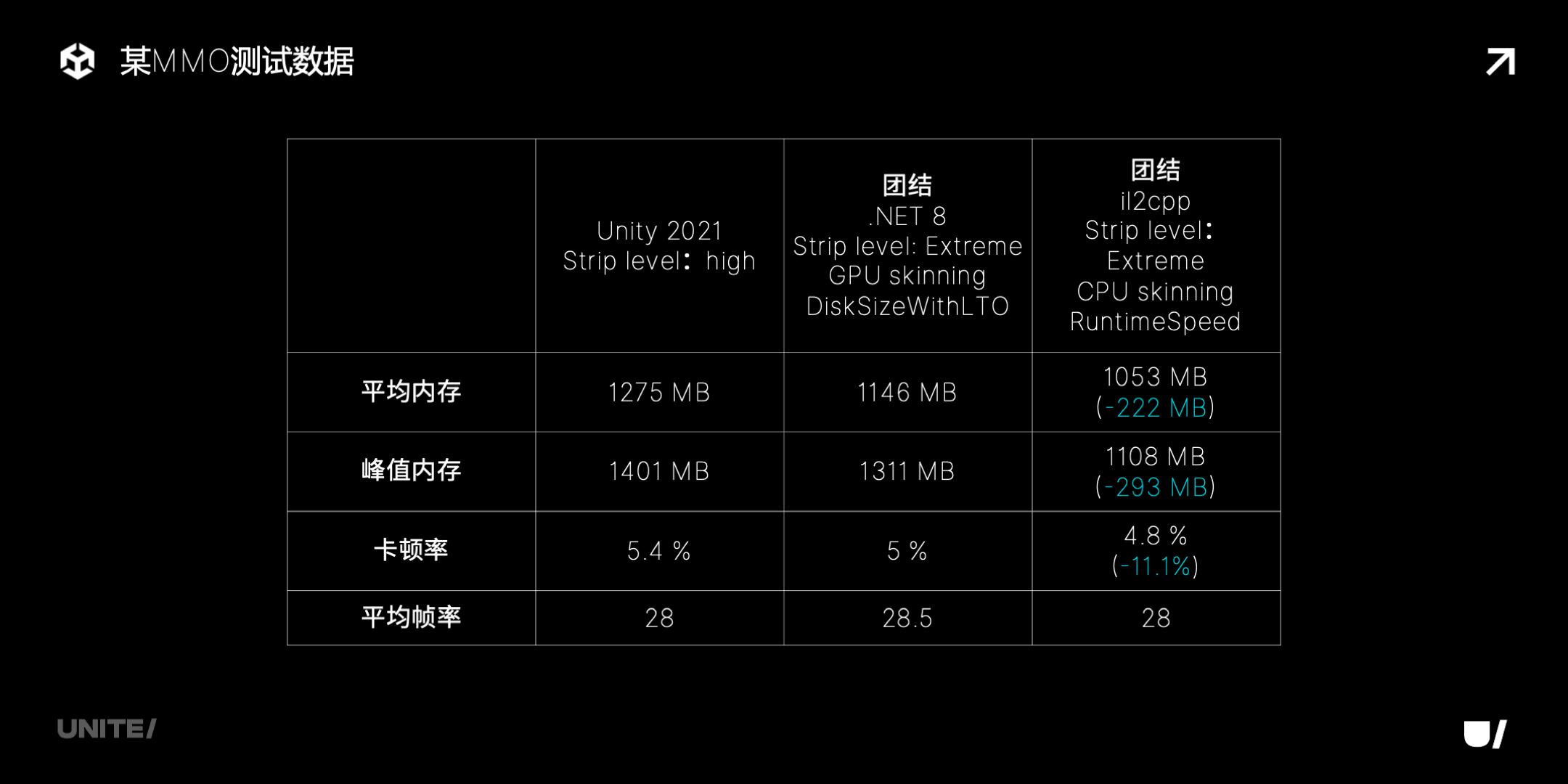
下面是另一款游戏的测试数据,从 Unity 2021 升级到团结引擎后,在帧率保持不变的前提下:平均内存下降了 222MB,峰值内存下降了 293MB,游戏卡顿率下降了 11%。
下面请傅有成为大家介绍,开发小游戏各个阶段需要关注的技术点。
平台适配

傅有成:大家好!先聊一下平台适配。
首先看一下诛仙从手游移植微信小游戏的时间线,给大家做个参考。
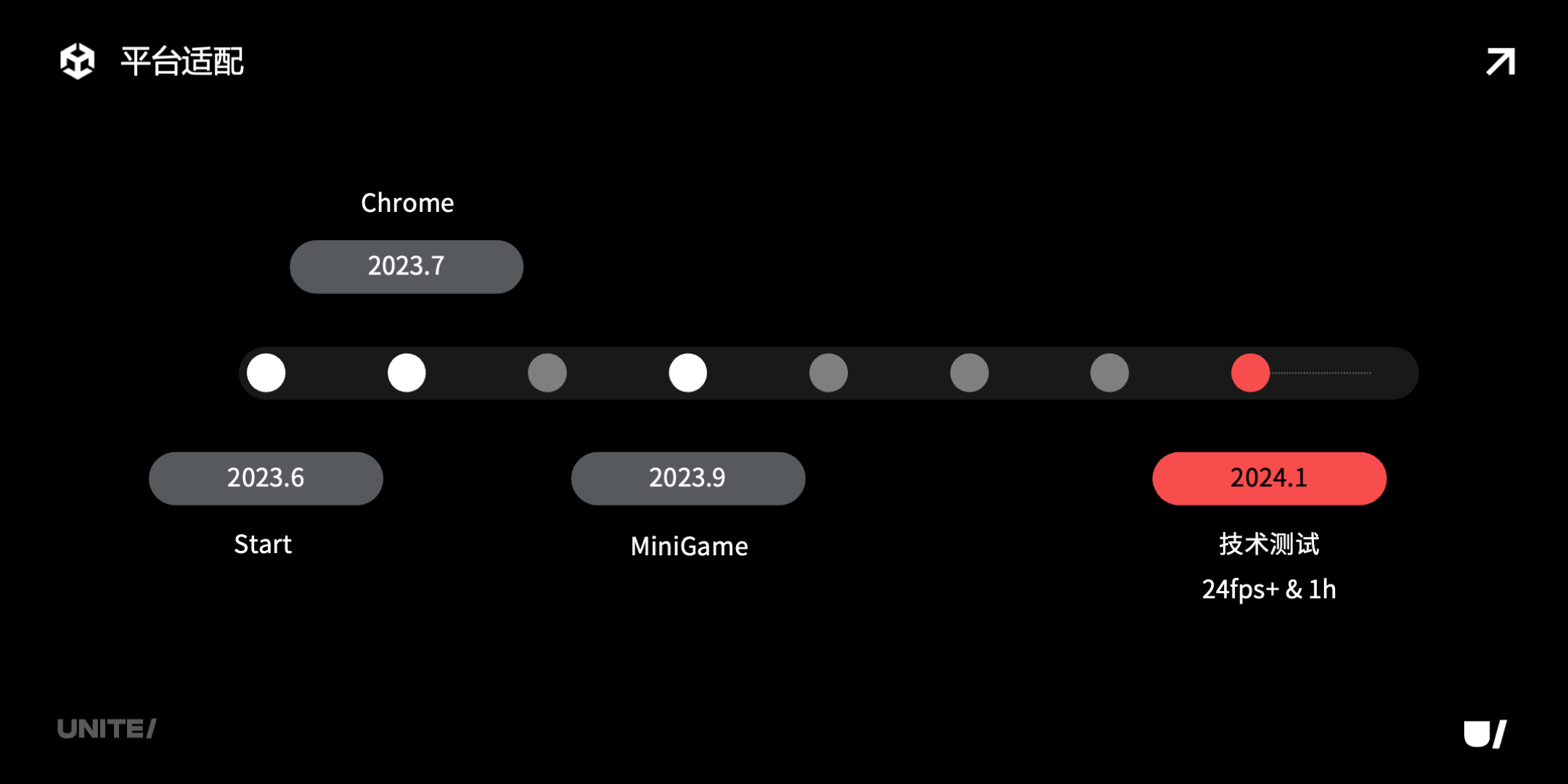
2023 年 6 月项目启动,7 月在 Chrome 浏览器上跑起来,9 月在微信小游戏上跑起来,2024 年 1 月优化到 iPhone 8P、晓龙 765 能稳定 24 帧以上。诛仙的时间线其实不快,因为它是一款重度 MMO,也是项目组第一次接触微信小游戏,而且也是相对早期在微信上发布重度 MMO,踩的坑偏多。现在 1 年多过去,随着大量开发者摸索实践,还有引擎的优化,再做微信小游戏移植,效率会高很多。
接下来具体看一下平台适配需要的工作和注意点。

首先需要注意,小游戏平台目前有一些能力限制:
-
暂时不支持多线程;
-
不支持 socket,可以替换为 WebSocket 或者微信小游戏提供的 API;
-
目前微信小游戏支持 WebGL1 和 WebGL2,compute shader 是不支持的,如果游戏里用到需要修改;
-
H5 沙盒环境不支持常规的文件访问能力
(1)需要使用 UnityWebRequestAssetBundle 来加载 AB;
(2)另外微信提供了专门的接口可以访问本地文件。
关于插件还有两点需要注意:
-
因为微信小游戏是一个新的平台,插件的支持平台里需要勾选上
-
很多插件在微信小游戏平台是不需要的,要尽量移除,不然会白白撑大 WASM,浪费内存。
然后需要注意的是一些工程配置:

-
选用合适的 Graphics API;
-
合适的纹理压缩格式;
-
合适的 Scripting backend,团结新增了 .Net 8,有助于精简 WASM,不过 .Net 8 也有一些限制,酌情选用;
-
接下来两个选项 IL2CPP Code Generation,Code Optimization 和 WASM 代码运行性能关系比较密切, 后面会详细讨论一下;
-
还有就是 UnityHeap 预留内存,这个很重要:
(1)建议设置为游戏运行时的 dynamic memory 峰值再加 50-100MB;
(2)超休闲游戏推荐大于 256MB、中度大约 500MB、重度大约 768MB;
(3)要特别注意避免游戏运行过程中出现扩容,否则会产生一个内存峰值,容易引发 OOM。
另外还有一些其他的注意事项:
-
要避免内存峰值,包括 Mono 和 Native,因为 WebGL/小游戏平台上的内存管理特点,heap 是只增不减的,并且 Mono 和 Native 相互独立;
-
避免自动生成 C# 代码,可能会有很多冗余,撑大 WASM;
-
要注意缓存空间的使用量,小游戏本地缓存默认只有 200MB,再高需要在微信后台申请。
更详细的信息可以参见团结或者微信的文档。
启动加载
这是小游戏的启动时序,可以分成三个阶段:
-
代码下载和编译加载,首包资源下载;
-
引擎初始化、首场景加载、首帧绘制;
-
游戏自定义加载场景。
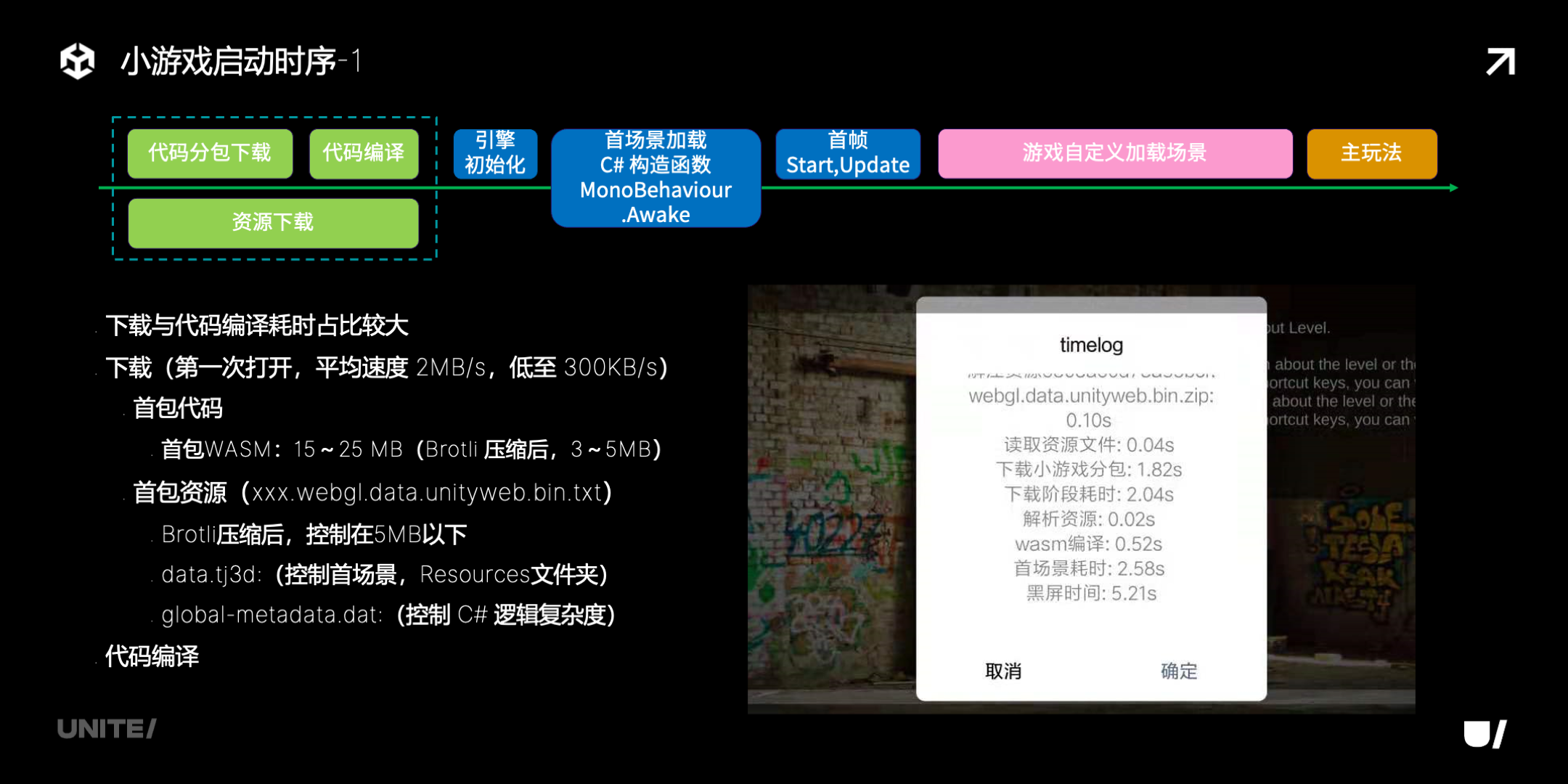
微信小游戏可以提供启动耗时的详细统计,这是一个例子。
整个过程里,第一部分下载与代码编译耗时是占得比较大的,这里有一些信息和建议:
下载方面,
-
首次打开游戏需要下载,会慢一些,微信分享玩家平均网络下载速度约 2MB,但也有不少低到只有 300KB;
-
之后有了缓存,速度会有提升;
-
首包代码的大小,建议控制在 15-25MB,Brotli 压缩后 3-5MB;
-
首包资源的大小建议控制在 5MB 以下,其中 data 是资源,可以通过控制首场景、Resources 文件夹来控制大小,global-metadata 是 C# 代码的元数据,需要控制 C# 代码的复杂度。
编译方面,耗时和代码体积正相关,主要就是控制好代码体积。
这里是一些具体的优化手段:

代码方面,
-
移除多余的 package 和插件;
-
避免自动生成大量 C# 代码的情况。往往会有很多冗余,比如 protobuf,同一个接口,接收和发送的代码都会生成,但实际端上一般只需要其中一种;
3.提高 Managed Code Stripping Level,剔除更多无用代码;
4.使用 WASM 代码分包工具。
资源方面,
-
可以使用微信系统字体,或者首包可以用其他精简字体,甚至图片;
-
首包的场景要少而精简;
-
避免使用 Resources 文件夹,手游上可能习惯全放在 Resources 里然后同步加载,小游戏要避免这样;
-
使用 AutoStreaming 或者 TextureManager,把重度资源自动移出首包,这个后面会具体介绍;
-
还有使用 br 压缩。
接下来看一下启动的第二个阶段。这是一个例子,可以看到引擎初始化很快,不到 200ms,首场景控制得好的话,首场景加载也只用几百 ms。

再具体看一下 callmain,下图是 callmain 的耗时细分:
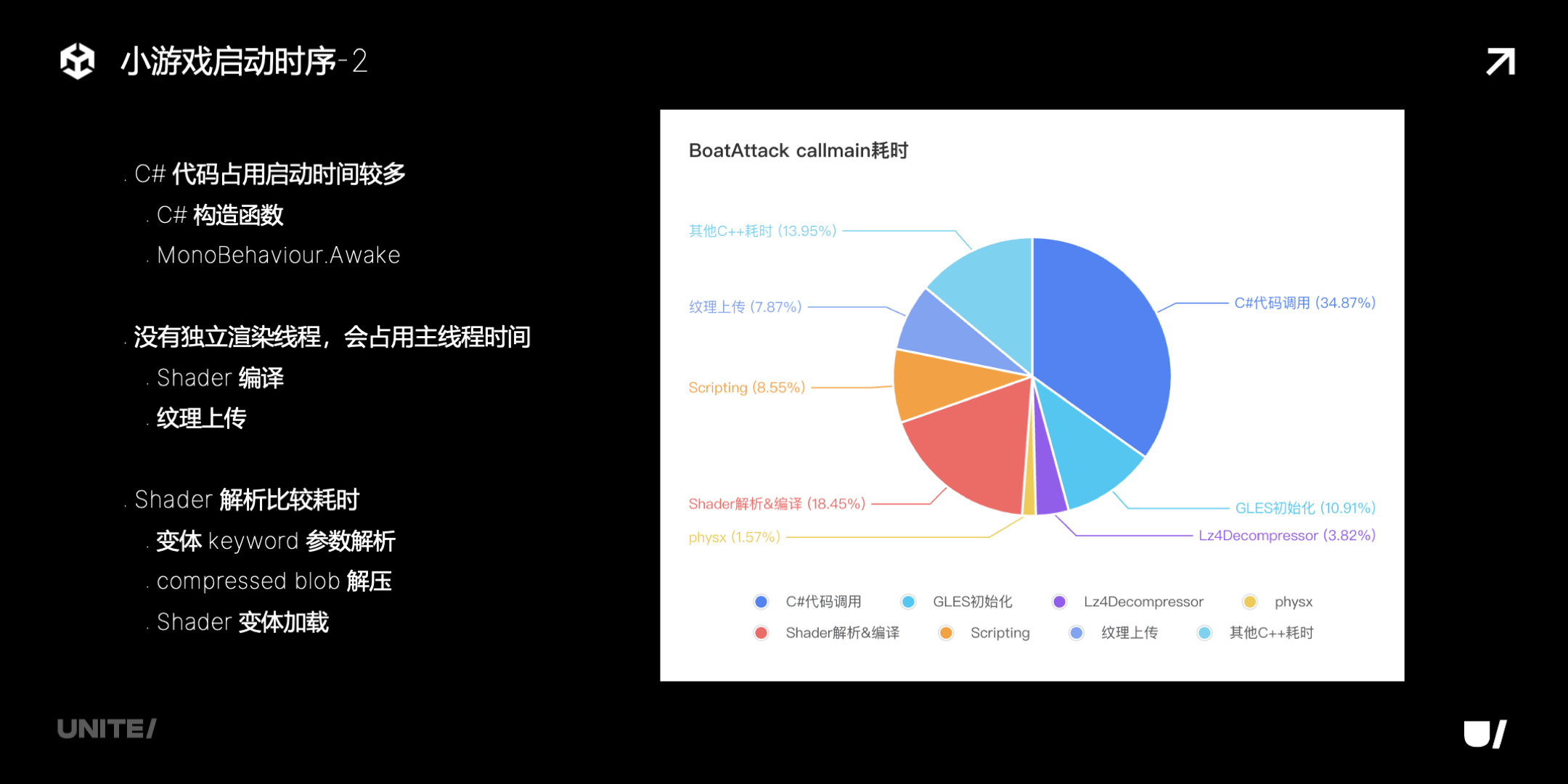
其中:
-
C# 代码占用时间比较多,主要是构造函数、Awake;
-
因为没有独立渲染线程,所以 shader 编译、纹理上传,这些都会占用主线程的时间;
-
还有 shader 解析也是比较耗时的,主要是解压,以及解析加载。
这是一些具体的优化方法:

-
C# 代码调用
(1)简化首帧的 awake、start;
(2)也不要在其中有一些阻塞操作;
(3)简化 C# 构造函数。
-
shader 方面
(1)不要用 Auto Graphics API;
(2)少用 always include shader;
(3)减少 shader 变体数量。
-
纹理和音频方面
(1)使用合适的压缩格式,避免解压,减少带宽占用。
引擎这侧,我们也做了很多优化,包括代码、资源、元数据的精简,很多的延迟、按需加载等等。其中很多对内存、性能也有优化效果,后面会再提到。

这里具体介绍一下托管代码精简。
这个精简是通过 UnityLinker 完成,从 DLL 里剔除没有用到的代码。原有的最高级别是 High,但仍然偏保守,保留了很多东西,我们新增了 Extreme Level,用了更激进的剔除规则,只保留用到的方法和一些必要的 Event Functions 比如 Awake、Update。
精简的一个问题是可能剔除一些必要的代码,之前需要用户自己调试,逐个发现,逐个添加到 link.xml,效率很低。我们现在新增了 Dryrun 模式,这种模式下不会真的剔除代码,而是插一条 log,用户可以一次运行就批量收集到误剔除的方法,效率高了很多。
另外对于 .Net 8,Strip Level 用 low 或者 minimal 就可以了,因为 .Net 8 下 C# 代码不会进入 WASM,不影响 WASM 体积,托管 DLL 本身对体积不敏感。

还有 IL2CPP 元数据。元数据是 C# 的类型、方法信息,IL2CPP 运行时需要依赖它。默认的元数据结构可以支持 21 亿个类型或方法,这是出于通用性的角度,但对小游戏来说,通常也就是万的级别。所以我们会在打包小游戏时,根据方法数量自动选择合适的元数据结构,这样可以让 global-metadata 缩减约 15%。

下图是引擎侧团结在 Unity 的基础上各项优化的实际效果。

边下边玩
在边下边玩方面。目前常用的方法是 AssetBundle 和 AddressableAssets,这里需要注意几点:
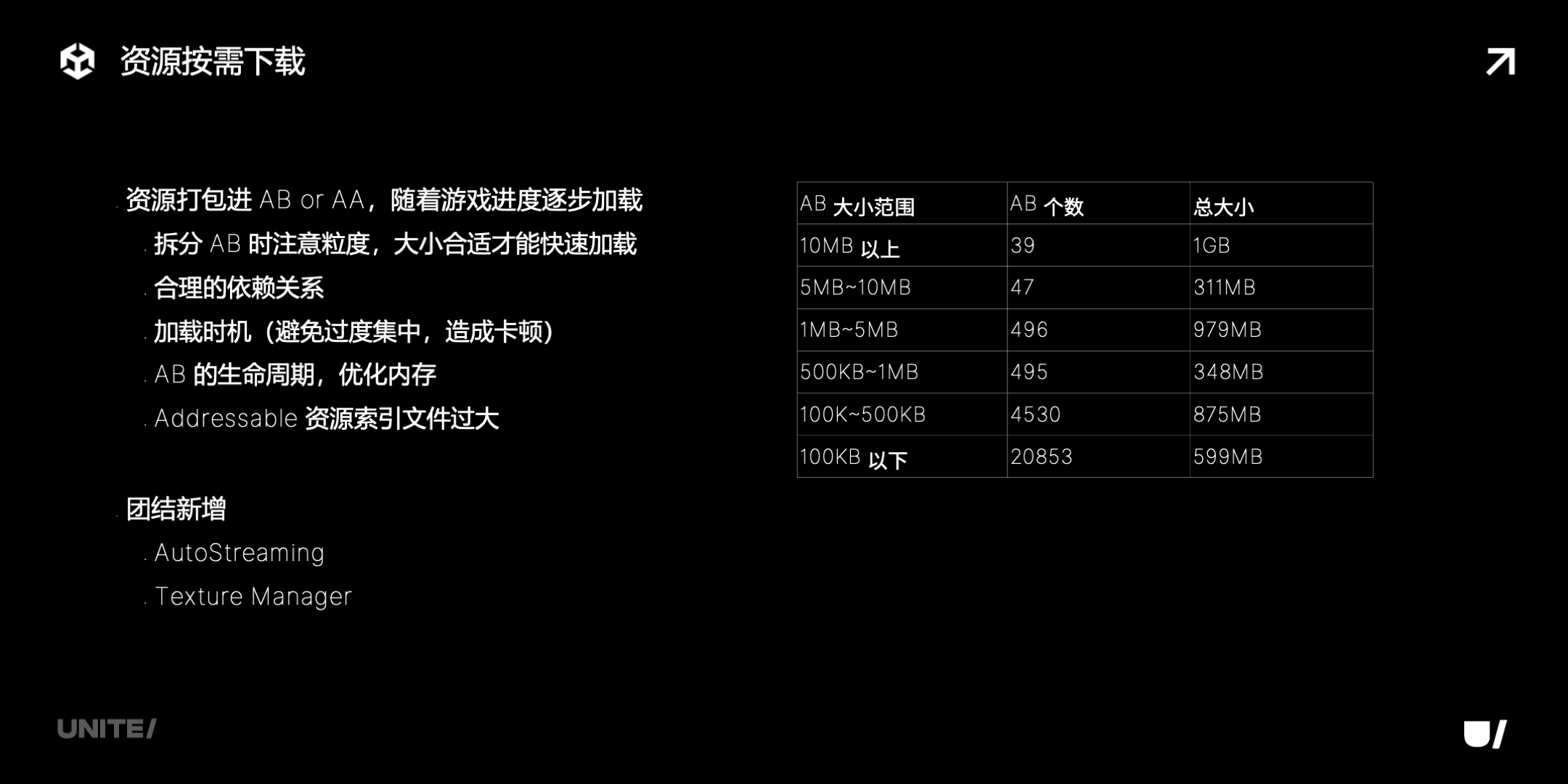
-
拆分 AB 时候粒度很重要,要选用合适的大小、合理的依赖关系,这里有一个实际游戏的例子;
-
然后要注意加载时机,做好分帧,避免集中;
-
还要很仔细地管理 AB 的生命周期;
-
大型游戏不建议用 Addressable,因为资源索引文件可能会很大。
团结新增了两种辅助工具,AutoStreaming 和 TextureManager,对于使用了 AB 或者 AA 的工程,可以帮助控制 AB 粒度、更好地处理依赖。没有用 AB 的工程,也可以直接使用它们来完成资源按需加载的改造。
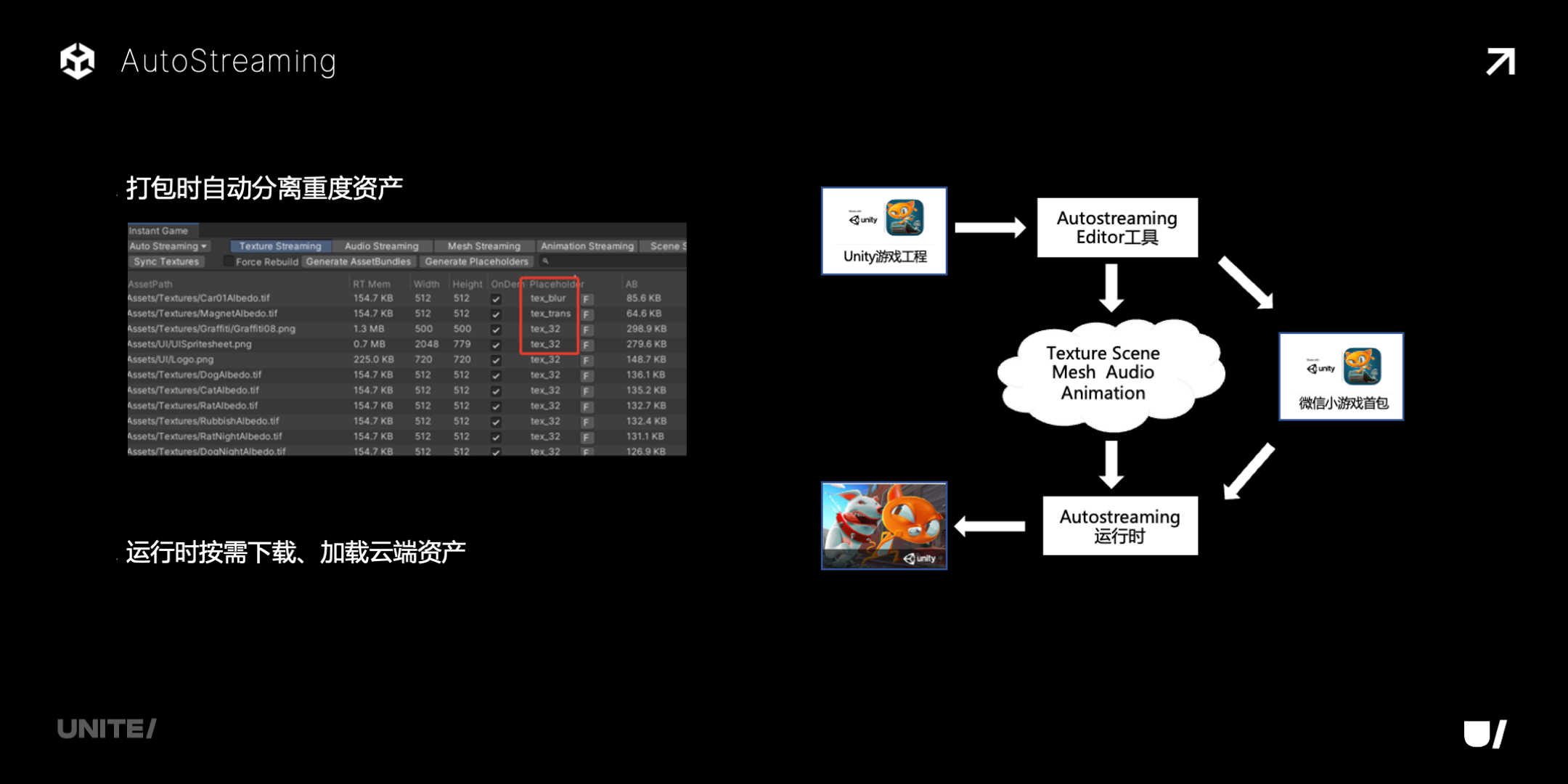
AutoStreaming 就是自动流式加载。在 Editor 里提供了工具,打包时自动分离重度资源,包括 Texture、Mesh、Audio、Animation、Font,部署到云上,首包和 AB 就会大大减小。游戏运行时,引擎会按需从云上下载资源然后加载,开发者不用修改游戏逻辑,都是引擎自动完成的。所以 AutoStreaming 的特点就是,游戏工程的改动比较少,可以快速在小游戏平台跑起来。
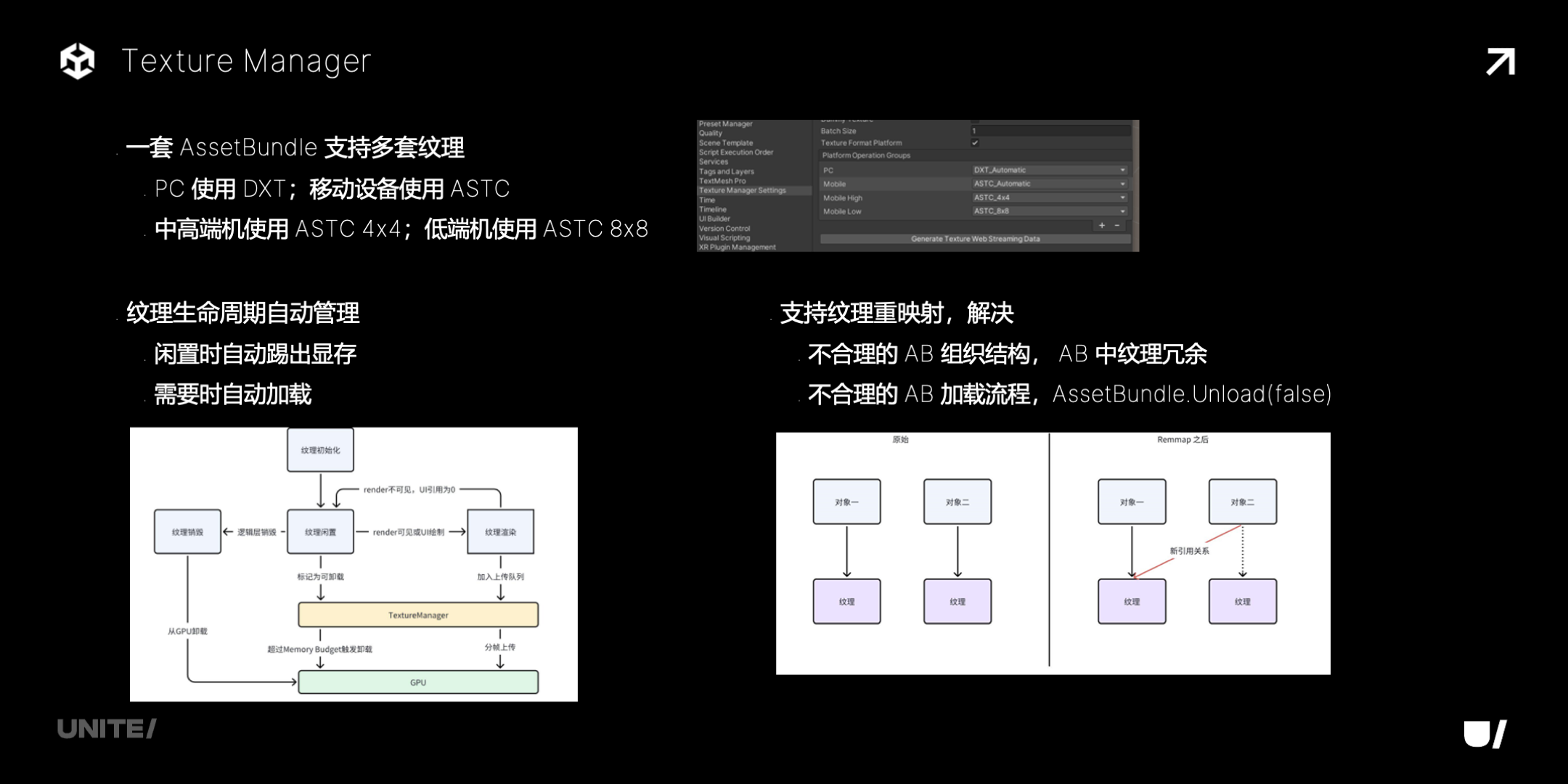
Texture Manager 主要解决两个问题:
-
更好地支持多压缩格式,可以一套 AB 支持多套纹理,用在不同的平台和设备上,提高资产打包发布的效率;
-
用各种方式降低纹理的显存占用,包括更精细的生命周期管理,还有纹理重映射,来消除冗余,解决一些不合理的加载流程带来的问题。
内存优化
在内存优化方面,先看一下小游戏的内存分布:
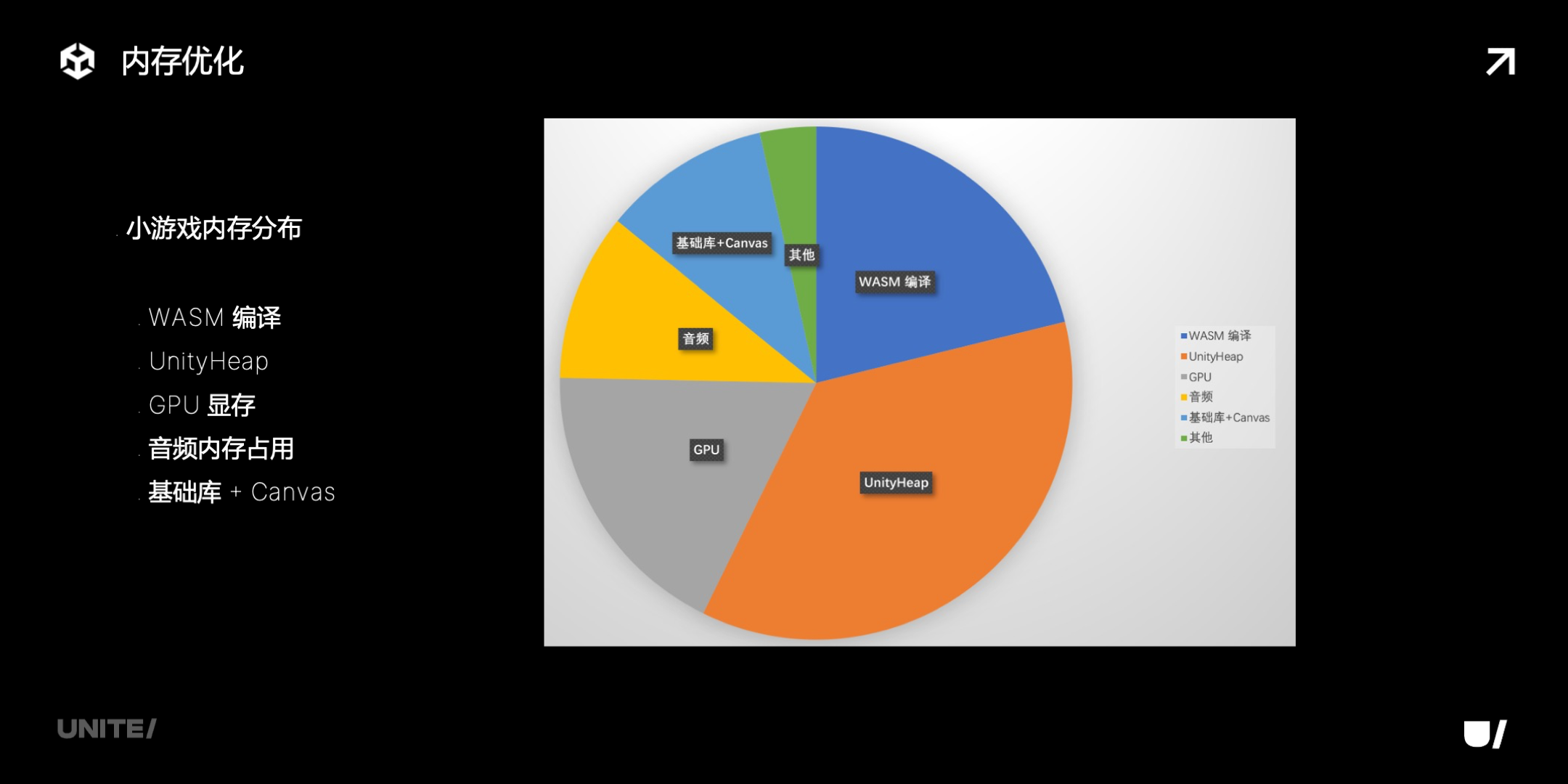
-
WASM 编译,这是代码编译和运行时指令优化产生的内存,和 WASM 体积相关,可能会很大。比如在 iOS 上,可能会多到 WASM 体积的 10 倍。
-
UnityHeap,包括:
(1)引擎 native 堆:引擎内部的 native 对象、IL2CPP 运行时;
(2)托管堆:C# 对象;
(3)插件 native 内存:插件(比如 lua)直接调用 new、malloc 产生。
-
GPU 显存
-
音频
-
微信基础库和 Canvas
这是具体的注意事项,开发者需要关注的部分,除了常规的那些以外,还有:

-
WASM 瘦身,这个等下会具体说;
-
UnityHeap:
(1)主要是合理的预设值,避免扩容;
(2)避免内存峰值,前面说了heap是只增不减的,要避免诸如单个场景或者AB过大、单帧内分配过多对象之类的情况。
-
AB 方面,注意合理地使用,精细管理,另外还可以使用微信提供的 WxAssetBundle。
-
注意文件方面的操作。
-
注意纹理和音频的各种设置,还有字体尽量精简。
-
在 iOS 平台可以使用微信 Performance+ 方案。
引擎侧我们也做了很多优化,其中重点的部分后面会具体介绍。
这里有一个 WASM 瘦身的案例,从最初的 90M,用以下方法,逐步优化到了 14.6M:
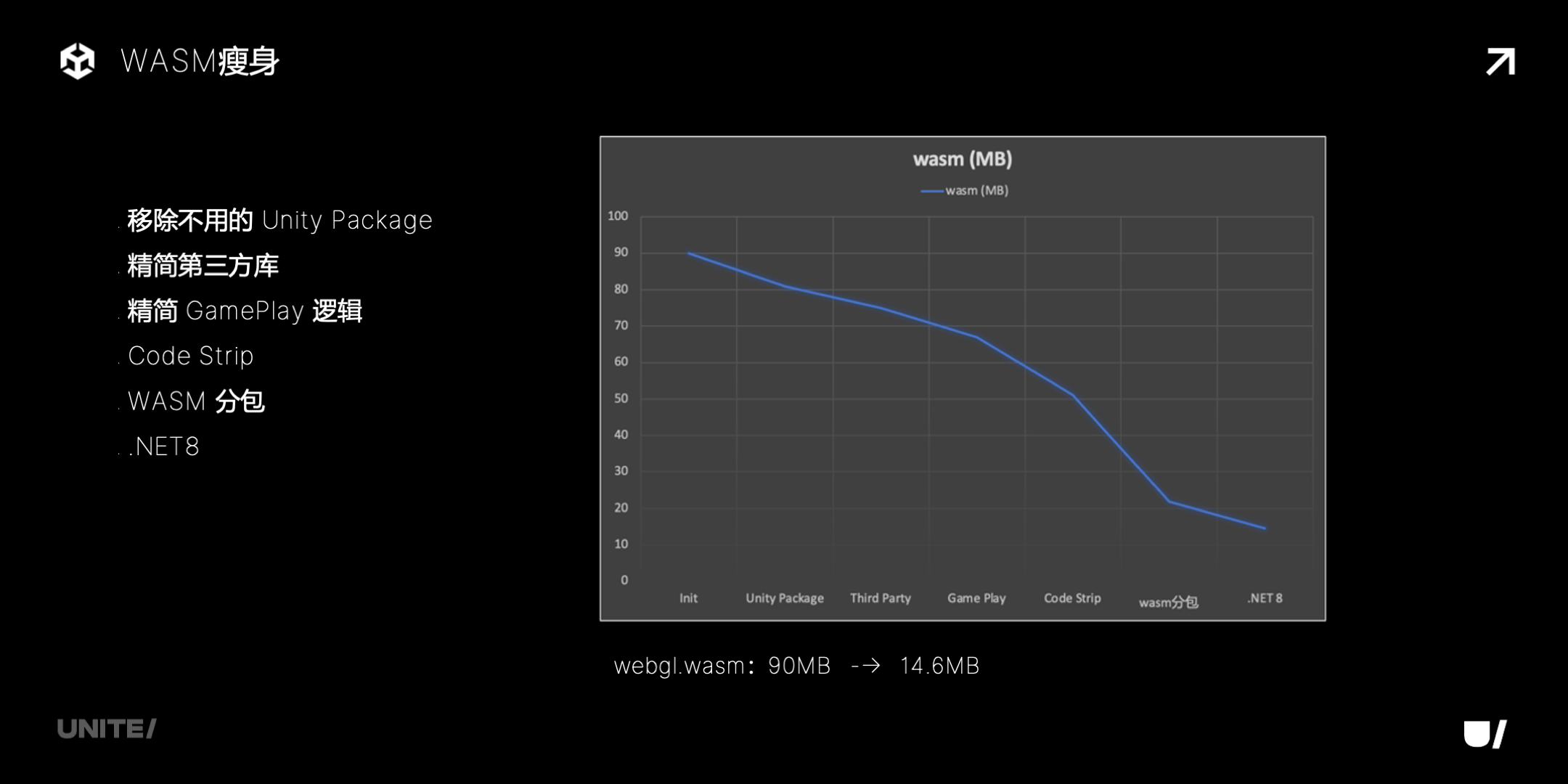
(1)首先移除不用的 Unity Package;
(2)然后精简掉小游戏平台不需要的插件,以及去掉重复的库,比如 json;
(3)精简游戏逻辑,去掉小游戏平台用不到的部分,比如多线程,以及前面提到过的 protobuf 的优化;
(4)提高 Code Strip Level,到 High 或者 Extreme,可以用前面提到 Dryrun 功能,提高效率;
(5)使用 WASM 分包,首包大约是原始 WASM 的 30%—50%;
(6)使用 .Net 8 方案,C# 代码直接不进入 WASM。
接下来介绍一下团结新增的 .Net 8 方案。IL2CPP 的一大痛点就是 WASM 过大带来的内存问题,IL 转换成 C++,编译链接进一个大的 WASM,通常会有好几十 MB。我们通过代码剔除、分包、优化代码生成等方式来减小 WASM 体积。
另一个优化方向就是解释执行,就是这个新的 Scripting backend,.Net 8。.Net 8是微软 2023 年发布的,可以稳定支持 WebAssembly,它解释执行 IL,所以可以把 DLL 从 WASM 里分离出来,减小 WASM 体积,进而降低内存。同时我们还可以享受到 .Net 生态的各种新技术,以及未来持续的性能提升。

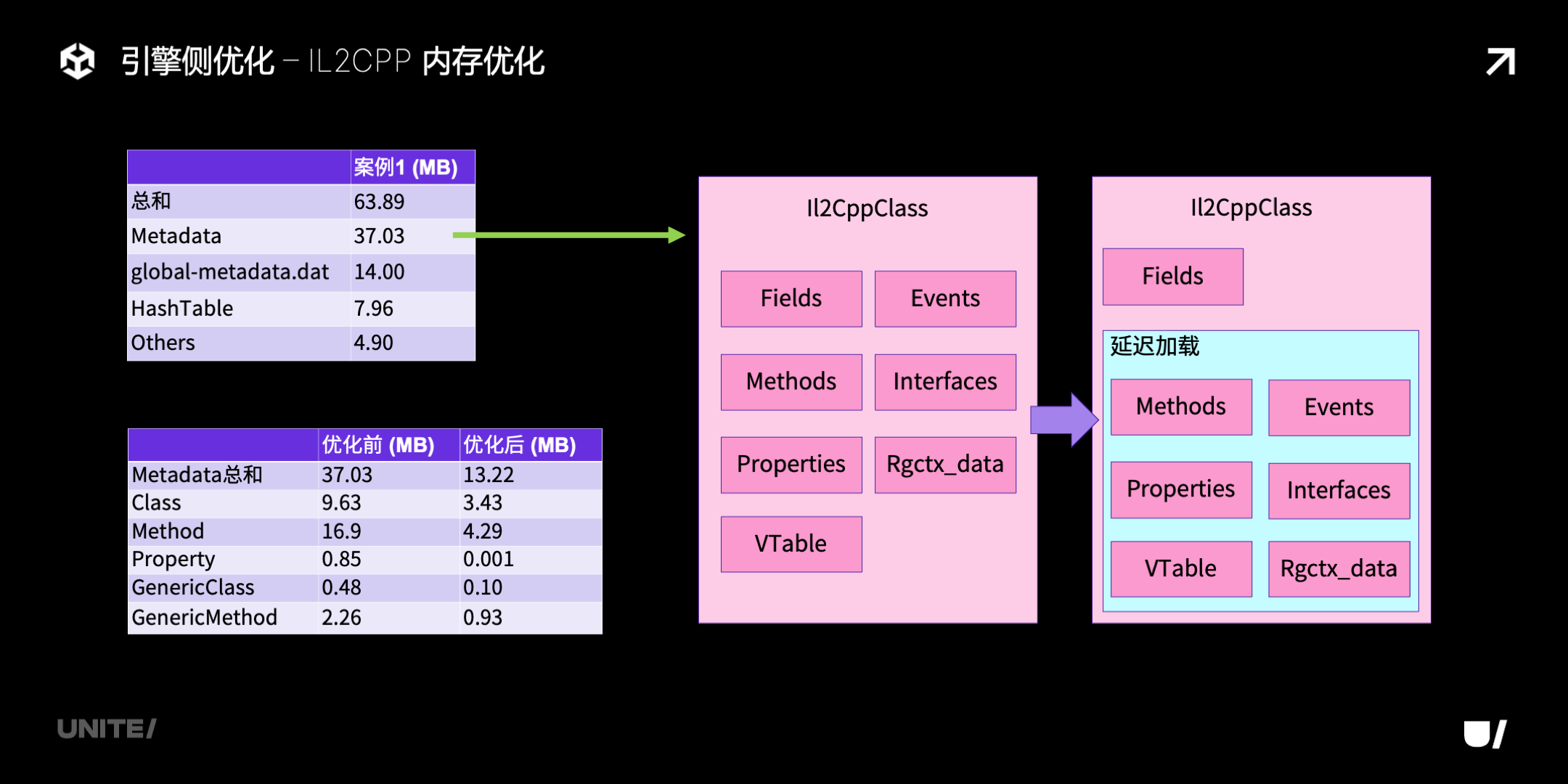
IL2CPP 内存优化方面,首先分析一下 IL2CPP 运行时的内存开销,其中比较大的部分是 Metadata,这是运行时构建的元数据,我们的优化主要就针对它。之前的实现里,用到某个类型时,会初始化这个类型的完整的元数据,但其中只有很少一部分会实际用到,现在我们对这些元数据进行了延迟加载,其中大部分信息都是可以做延迟加载的,而且粒度可以精确到每个方法。此外我们还裁剪掉了一些平台不支持的特性的字段。下图是一个优化效果的示例:
Shader 内存方面,主要是针对变体相关的优化,思路也是延迟加载。引擎原本会解压所有 blob 数据和加载所有 shader 变体,我们都改为了按需加载,同时及时释放解压后的 blob 数据。实际测试中,BoatAttack 减少了 34.6M,另外一款 MMO 游戏,降幅也可以达到 70%。

引擎底层的内存分配器,存在一定的 overhead,即使在 release 版上也是有的。虽然单个很小,但是架不住次数多,我们把这部分也去除了,同时调整了 alignment。实测下来,在一款中重度的 MMO 游戏上,也可以得到 10M 以上的收益。

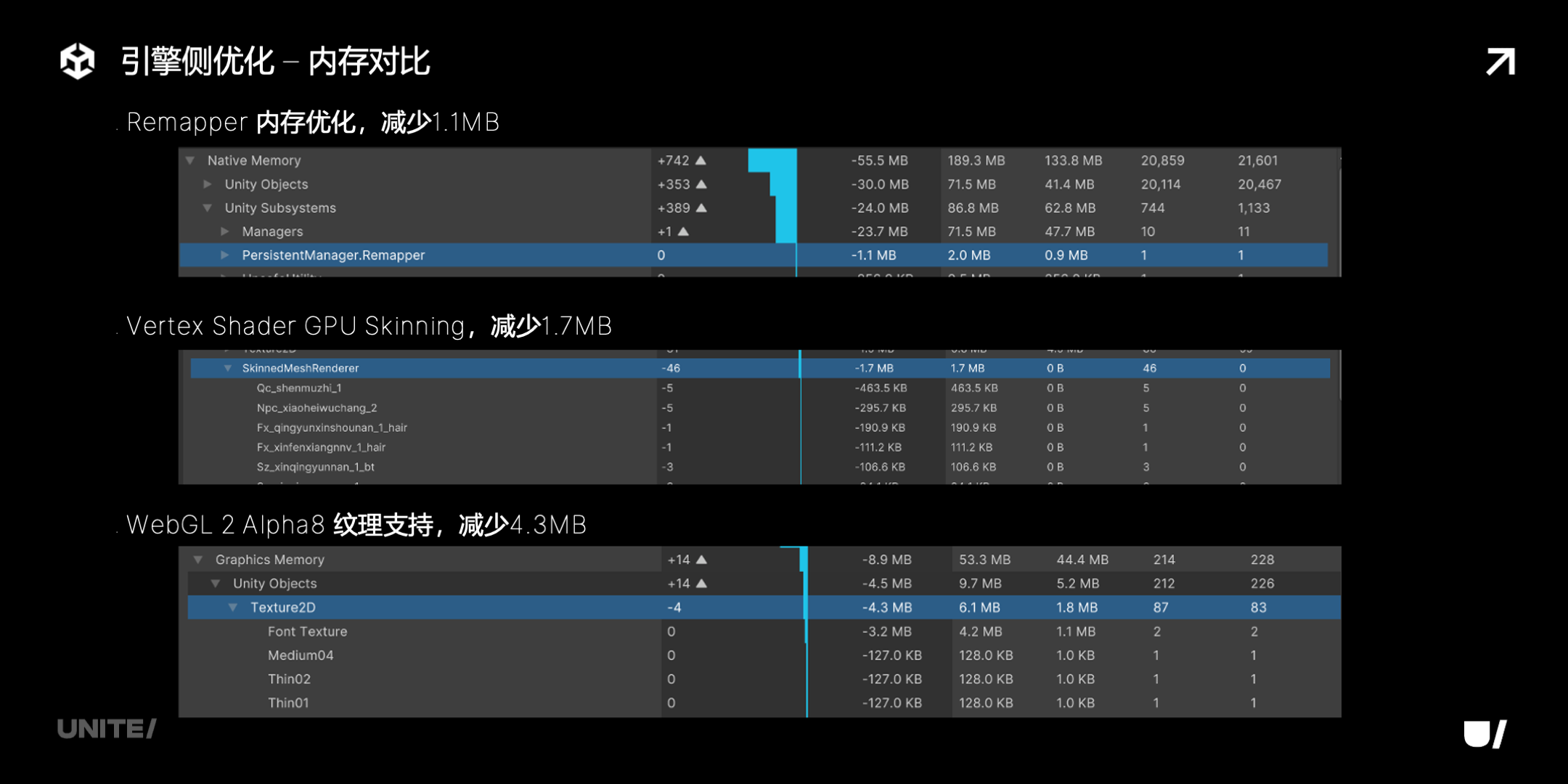
Remapper,这是对象序列化位置和 InstanceID 之间的双向映射关系的数据结构。之前是用的 map,加载资源非常多时,map 会很大,但它是稀疏的,浪费比较多,而且不复用 InstanceID,内存增长也比较粗暴。我们现在优化为数组的结构,加上复用策略,更加紧凑,内存增长更合理。这个优化目前只在微信小游戏平台启用,之后会逐步开放到其他平台。

这里展示的是团结 IL2CPP 的优化收益数据,诛仙的案例。WebKit.WebContent 进程内存从 806M 下降到了 755M,减少了 51MB,右边是具体的 breadkdown。

下面是各项优化的详细的数据。
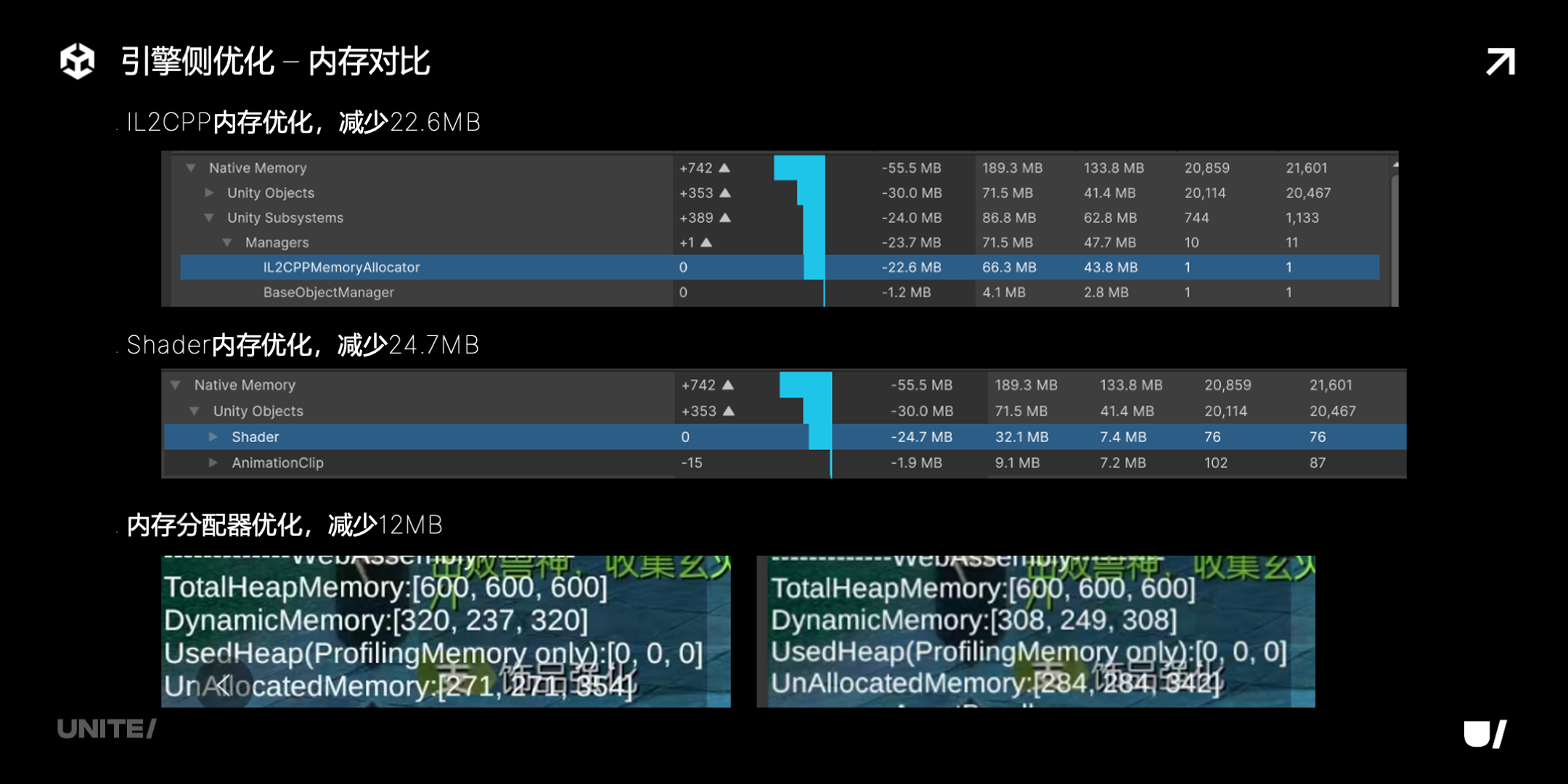
可以看到,团结引擎对小游戏的优化是各个模块一点一滴累积起来的,小到 1、2M,多到几十M,都不放过。
切换到 .Net 8 之后,我们还可以获得更多的内存收益,主要来源于这些方面。在这个例子上,实测内存下降可以达到 163M。

性能优化
在性能优化方面,首先介绍一下小游戏平台的性能特征。
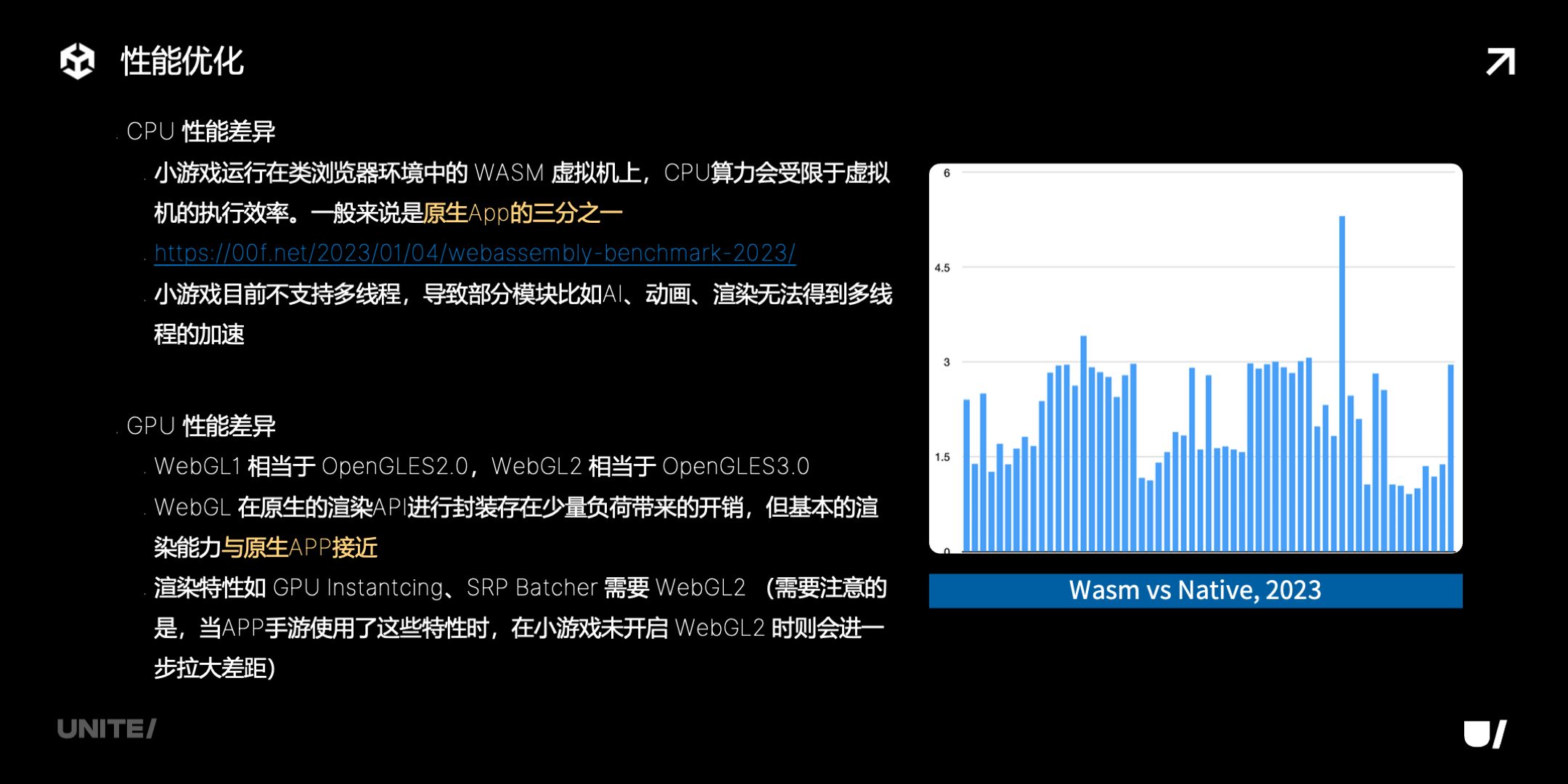
CPU 方面,因为运行在类浏览器环境的 WASM 虚拟机上,算力受限比较多,一般来说是原始 app 的三分之一。同时小游戏目前还不支持多线程,所以部分模块无法得到这方面的加速。GPU 方面,支持 WebGL1 和 WebGL2,相当于 OpenGLES 2.0 和 3.0,基本的渲染能力和原生 App 接近,游戏可以根据自己的情况来选择是不是用 WebGL2,主要是看有没有用到 GPU Instancing、SRP Batcher 这些渲染特性。
具体的性能优化方式,首先看开发者需要关注的点。除了常规的性能优化手段外,小游戏平台有一些特别的点:
-
不要用 xml、json 解析大文件,解析时候的字符串操作会大量消耗 CPU 算力和引发 gc;
-
避免用 lua 做重度运算;
-
IL2CPP code generation 和 code optimization,实测对性能影响很大,后面会具体介绍。
引擎侧我们也做了大量的优化,包括 GPU skinning、SIMD,还有很多 shader 相关的优化,稍后会具体介绍。

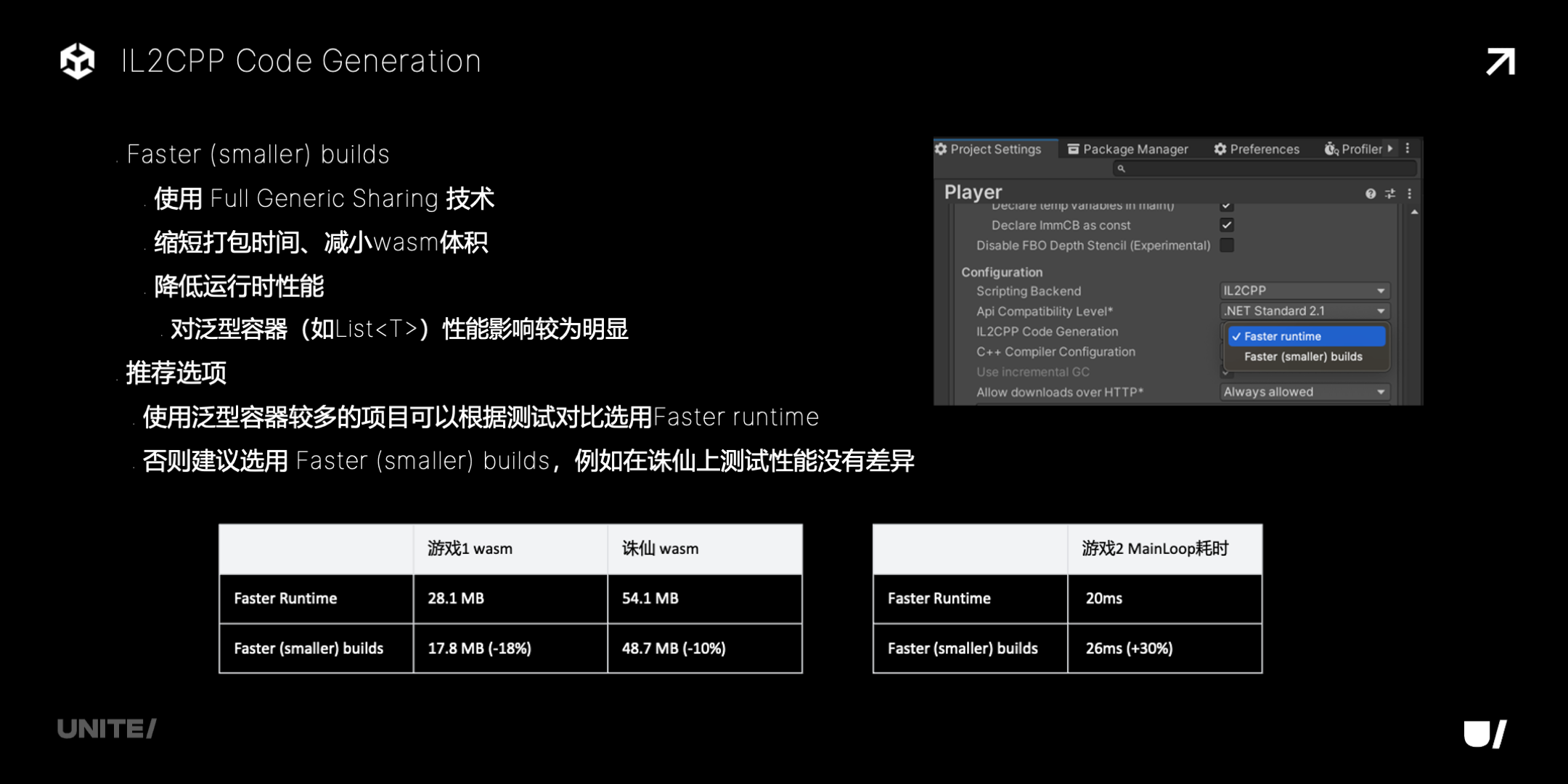
IL2CPP Code Generation 有两个选项,其中 Faster (smaller) builds,用了 Full Generic Sharing 技术,可以缩短打包时间,减小 WASM 体积,经验数据看能减少约 15%。但是可能会对运行时性能有影响,尤其是对泛型容器。
这里有一些具体例子,WASM 体积都有减小,性能方面要看具体游戏,比如诛仙就没什么影响,但是游戏 2 这个案例受影响就比较明显,所以需要根据项目实际情况来选用。
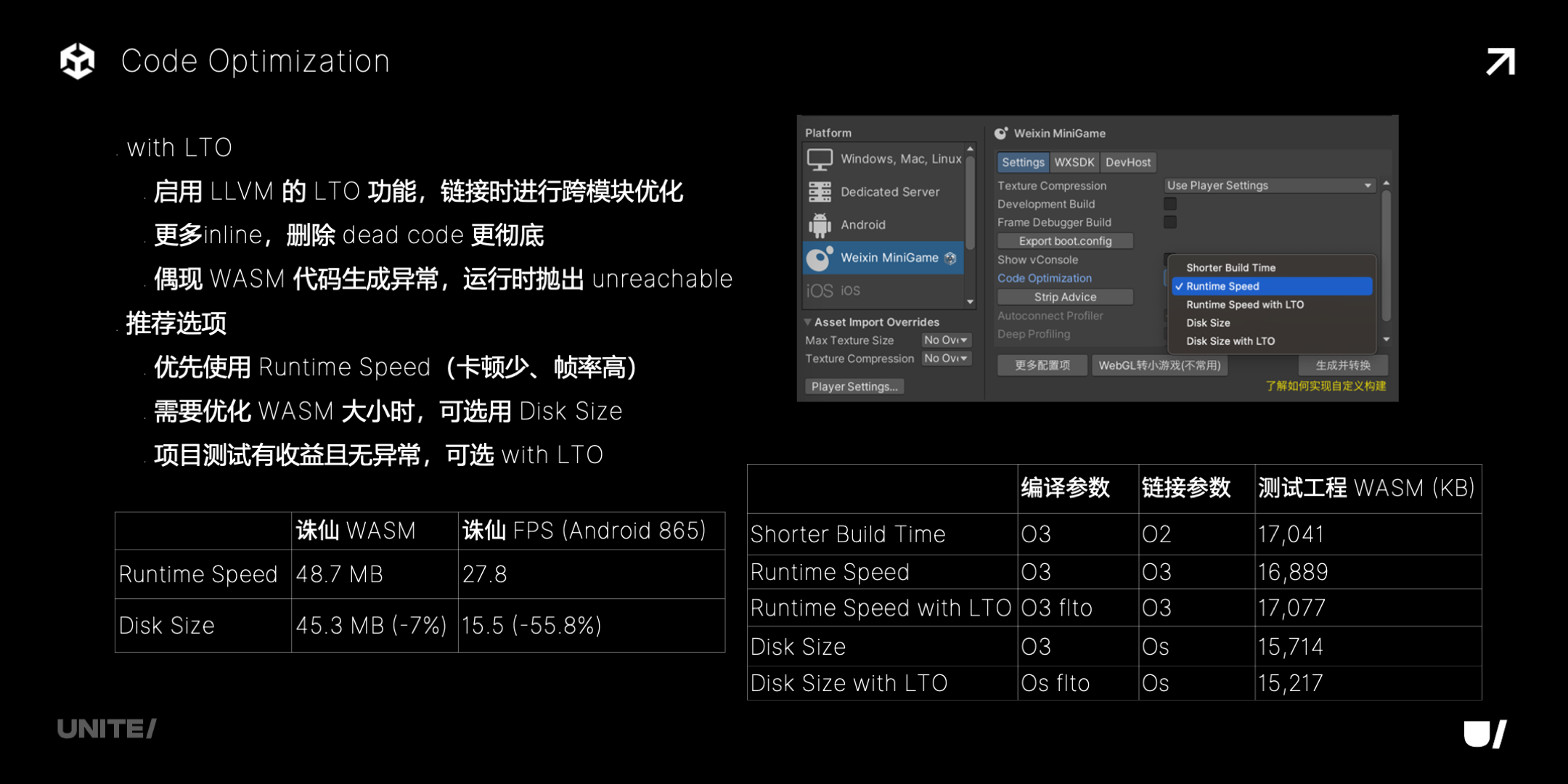
Code Optimization 选项比较多,它们对应着不同的编译链接选项。需要说明一下的是带 with LTO 的选项,是启用了 LLVM 的 LTO 功能,链接时会跨模块优化,有更多 inline,删除 dead code 更彻底,不过也偶尔遇到过生成的代码异常的情况。推荐的选项是,优先使用 Runtime Speed,需要优化 WASM 大小时可以选 Disk Size,with LTO 的如果项目测试有收益并且也没有异常,就可以用。
接下来看一下引擎侧的优化,首先是 GPU skinning。
下面是 vertex shader GPU skinning 的优化效果,108 个角色的场景,CPU skinning fps 基本在 10 以下,GPU skinning 能达到 30,这样小游戏平台上的 MMO 类型游戏,就能真正做到多人同时在线了。
具体看一下各种 skinning 方案的对比。纯 CPU 最慢,启用了 SIMD,速度会有提升,微信分包近期也支持了 SIMD。GPU 方面,传统基于 compute shader 的方式在小游戏平台不支持,我们之前尝试过一个基于 transform feedback buffer 的方案,它对某些场景是有优化效果的,但是对角色数量多每个角色顶点少的情况可能效果不佳甚至是负优化。
最终我们采用了 vertex shader 计算、通过 uniform 更新骨骼矩阵的方案,前面展示的就是这个方案。使用起来也很方便,只要在 shader 代码里添加这样一行就可以,shader compiler 会在编译 shader 时候自动注入相关逻辑,避免用户逐个手工修改了。下面是一个自动修改前后的代码对比。
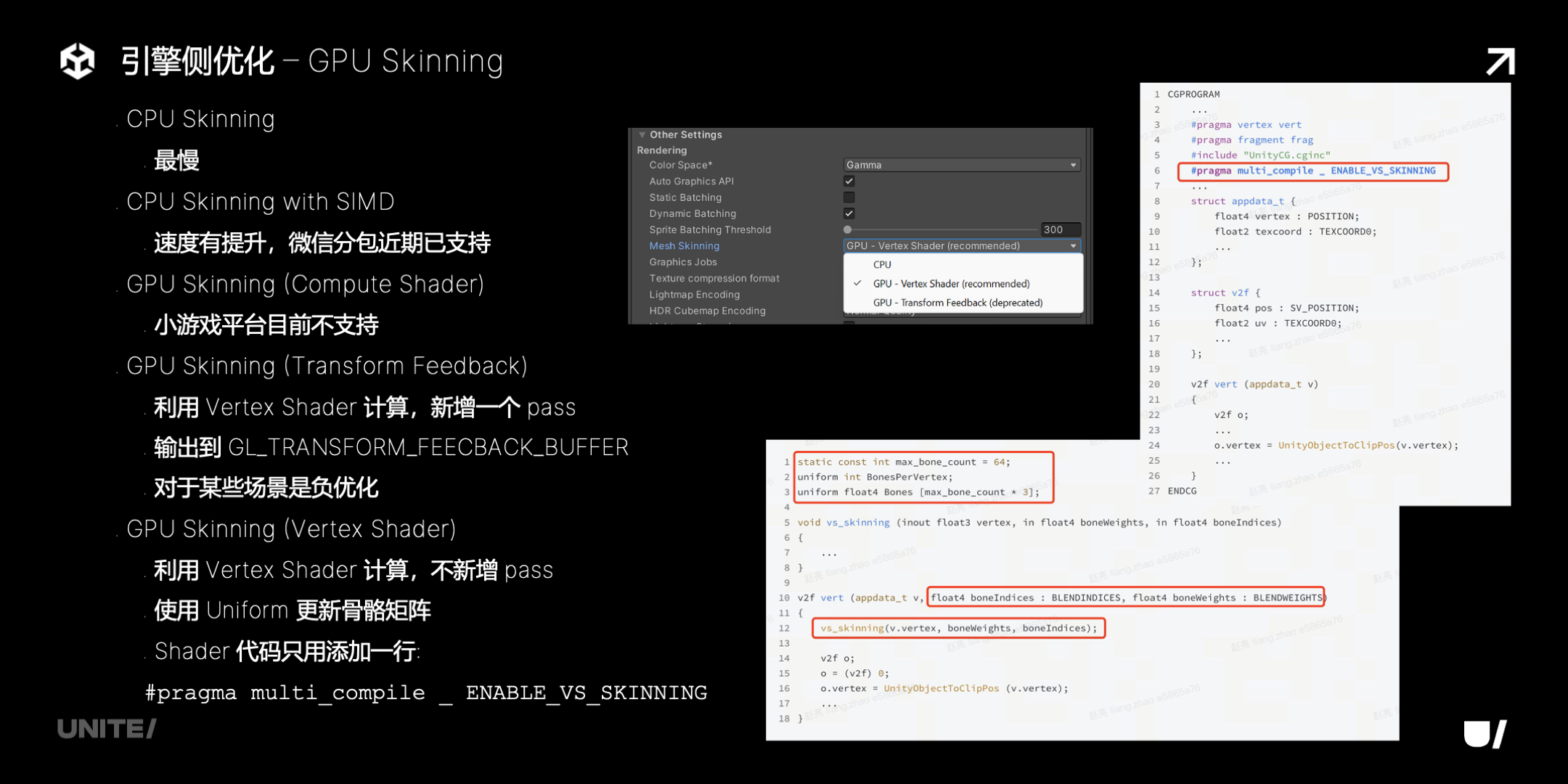
这个方案还有一些注意事项,大家可以记一下,使用的时候注意就好了:

接下来是 Shader 并行编译。Shader 编译比较耗时,是一直以来都存在的问题。WebGL 不支持 binary shader,单个 shader 编译时间可能需要几十 ms,之前已经有 warmup 功能,但它也不是异步的,只是调整了编译的时机,仍然可能引起卡顿。受益于微信平台的支持,我们利用 WebGL 的这个并行编译的扩展,实现了更理想的 warmup,真正异步起来。一个实测案例下,79 个 shader 变体,总的阻塞时间从 4 秒多降低到了 125ms。

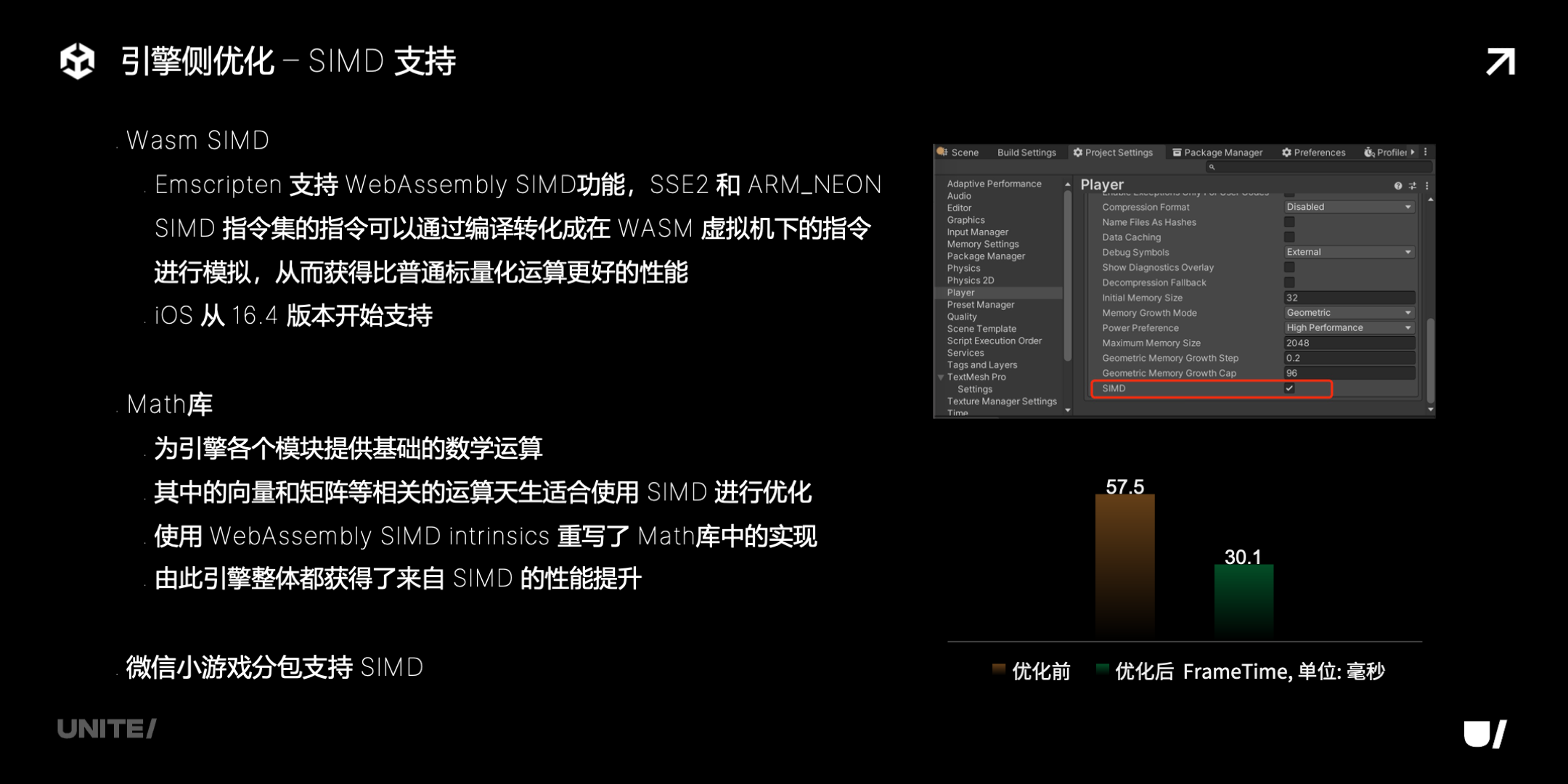
最后是 SIMD 支持。WebAssembly SIMD 提供了和 sse、neon 类似的向量运算能力,iOS 从 16.4 开始支持,团结和微信也很快都支持了。引擎底层的 math 库,天生适合 SIMD 优化,我们重写了它的实现。引擎整体都获得了来自 SIMD 的性能提升,下面是一个 skinning 的例子,耗时下降明显。微信小游戏分包最近也已经支持了 SIMD。
开发提效
在开发提效方面,
-
前面介绍过 AutoStreaming 和 TextureManager;
-
团结引擎深度集成了微信小游戏 sdk,切换到微信小游戏平台时,会自动安装 sdk,同时直接把微信打包页面集成到引擎 BuildSettings 里,用起来更方便。
-
我们还优化了 AB 打包,一个实测案例中,2.5 万个 AB,体积 4G 多,打包时间从 160 分钟减少到 70 分钟。
Dev Host、Frame Debugger、C# Debugging,这 3 个接下来会具体介绍一下。

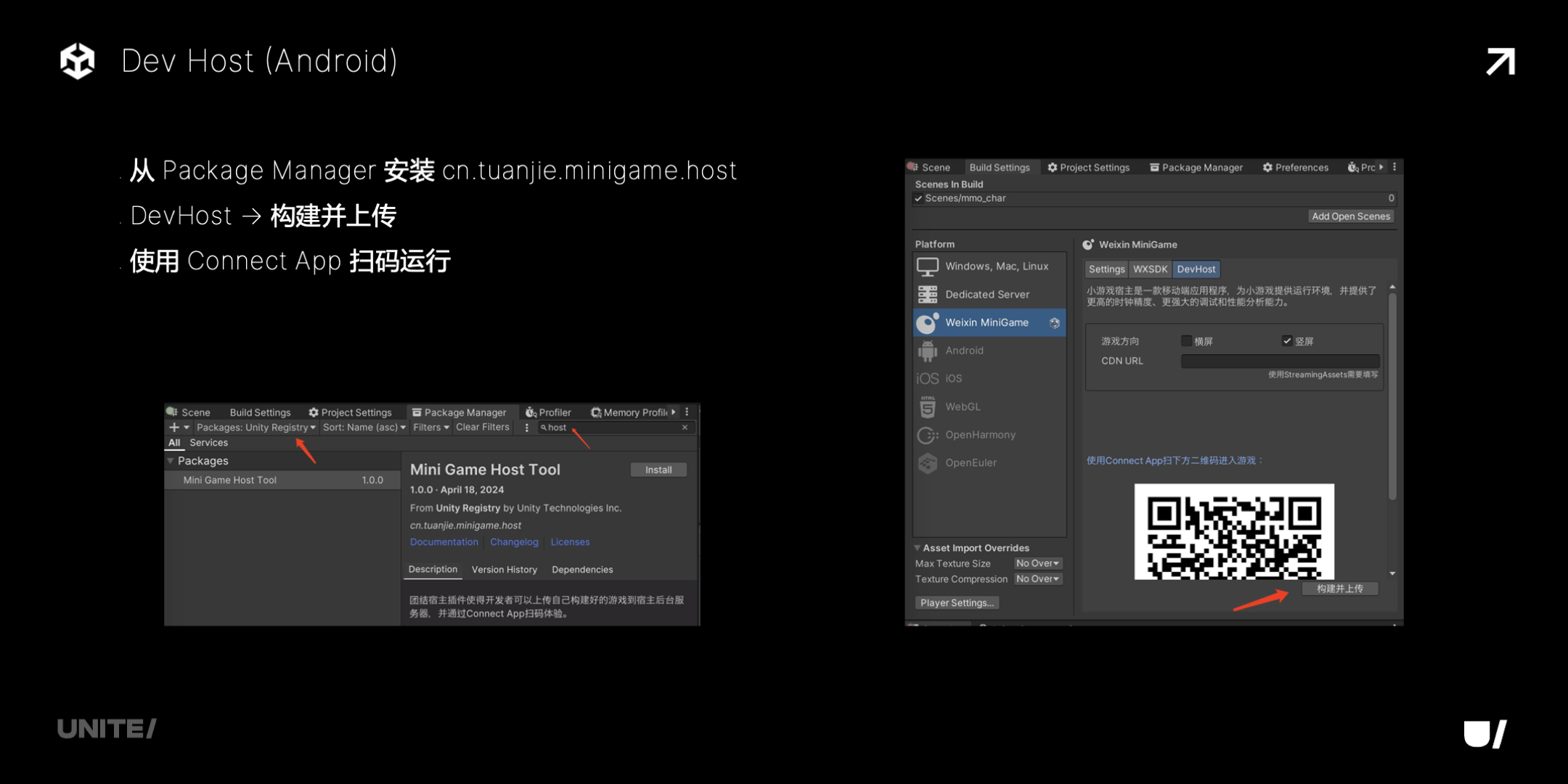
首先介绍 Dev Host。小游戏运行在类浏览器环境里,受限制比较多,比如多线程用到 SharedArrayBuffer 要求 https、无法监听端口和发送广播等等,导致 Unity WebGL 很多调试功能都不完善,不太好用,容易踩坑。所以我们在团结上开发了 Dev Host,让小游戏可以像原生应用一样高效 profile 和 debug。
Dev Host 目前提供安卓端,集成在 Unity Connect app 里,可以扫下图的二维码下载。iOS 端正在开发中,很快也会提供。安卓端基于 v8 开发,提供 CPU 使用率、帧率、内存、vConsole 等调试信息,支持一键发布,真机扫码就可以运行。
除了这些常见的基础能力,我们还提供了一些更强大的能力:
-
高精度时钟,对于 timeline 的 profile 帮助很大。
-
支持 frame debugger,便于绘制方面的调试。
-
还提供了真机 C# debugging 能力,这是其他工具不具备的。

使用也很方便,参照下图安装这个 package,在 DevHost 这里构建并上传,再使用 Connect App 扫码运行。
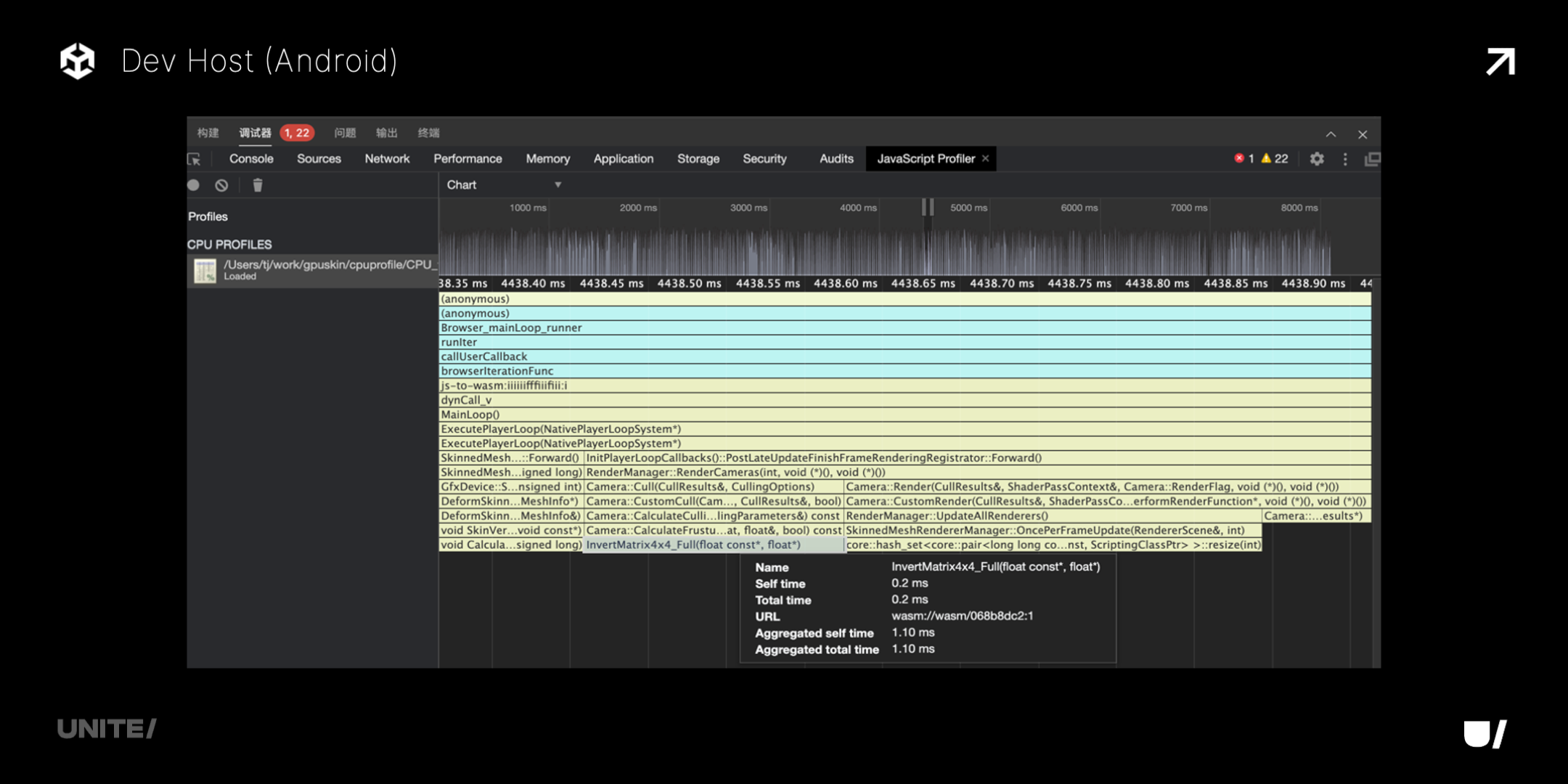
微信在安卓设备上可以导出 CPU profile,但是时间精度不足,只有 0.1ms,profile 细节的地方会比较困难。
下图是 Unity Profiler 连微信真机,提供的时间精度更低,只有 1ms。
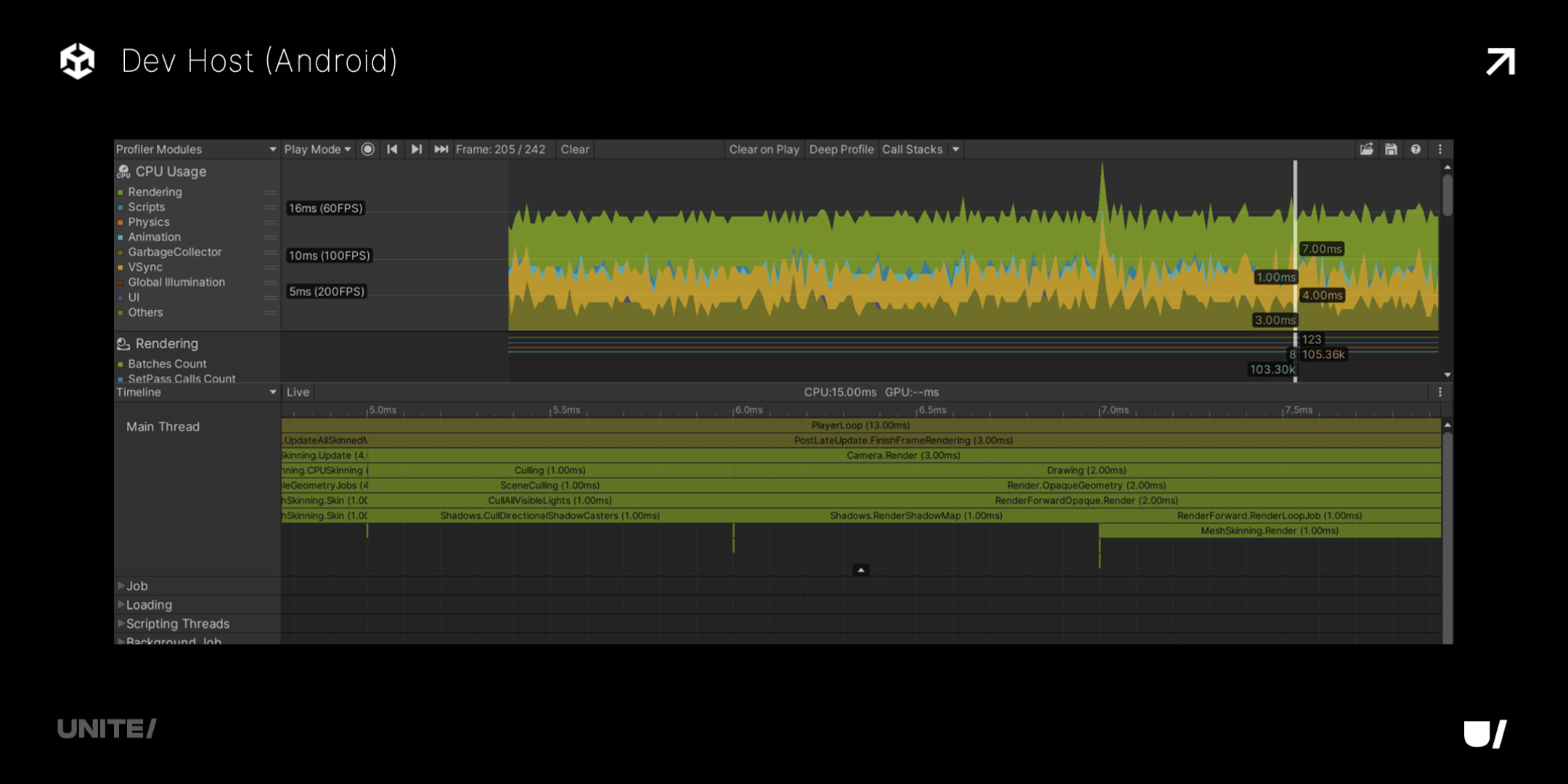
换成 Unity Profiler 连移动端 Chrome,好一点,但也还是只有 0.1ms。
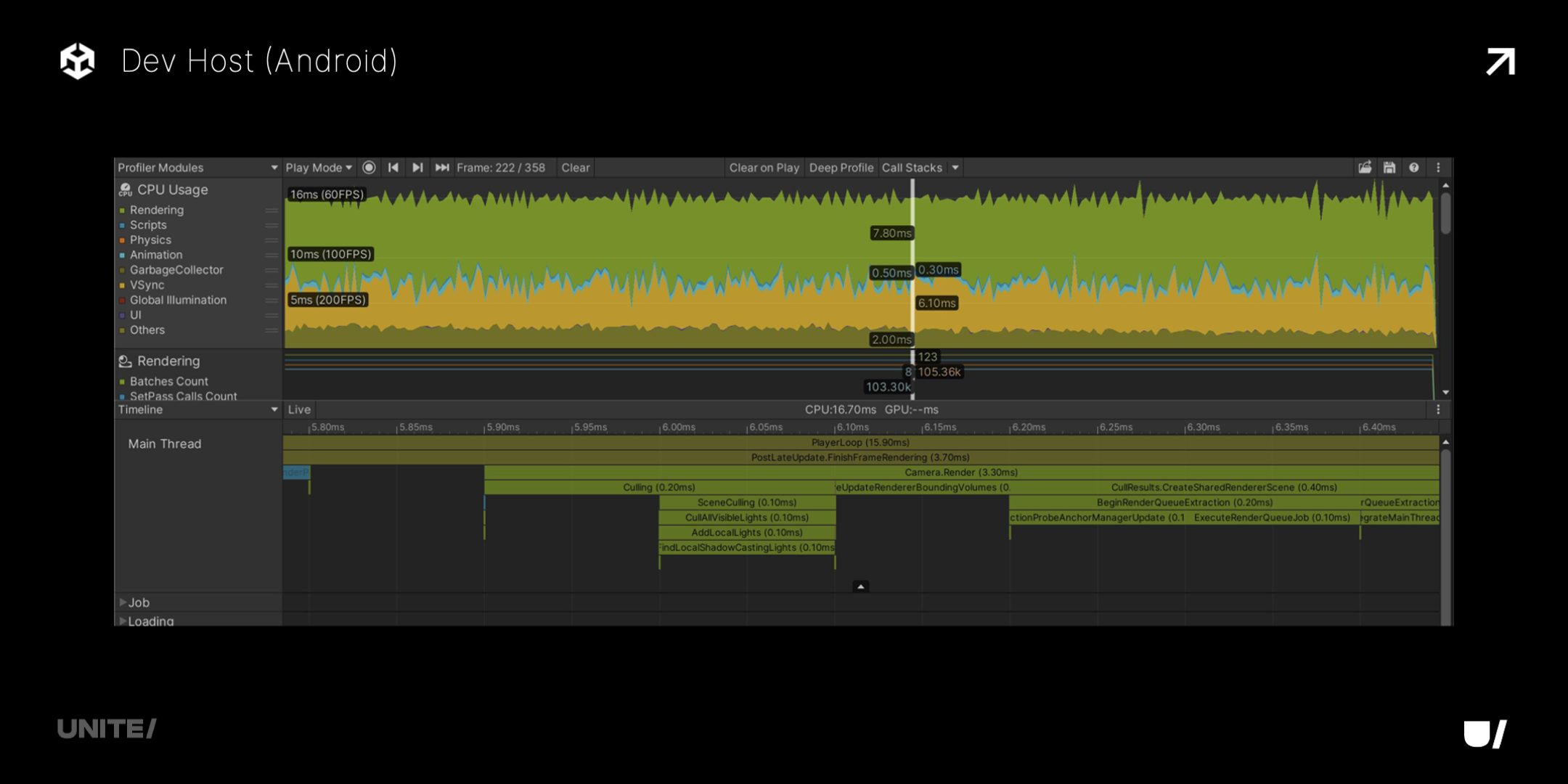
下图则是我们的 Dev Host,底层使用更高精度的 API,可以达到纳秒级,能看到更详细的堆栈信息,了解更真实的运行情况。
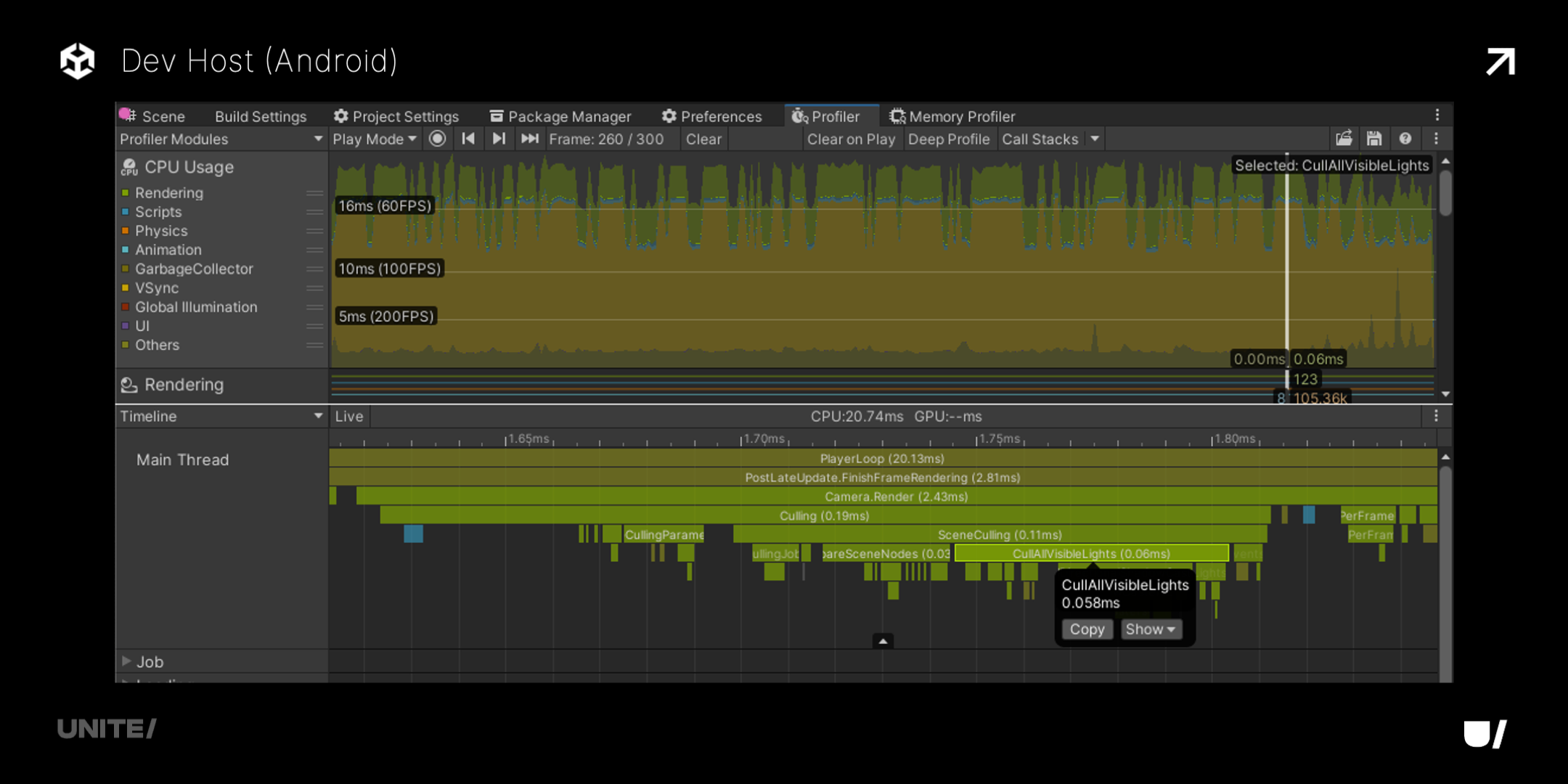
接下来是 frame debugger,这里展示了 frame debugger 连接微信真机小游戏调试的过程,用起来和其他平台一样。
最后再介绍下 C# 调试。Unity WebGL 是不支持 C# 调试的,原因包括多线程受限(需要一个独立的 debug agent 线程)、不支持 socket、无法发送广播、监听端口等等。小游戏平台上,我们的解决方案是增加多线程支持,在 Dev Host 里实现广播和监听,并且增加一个中间代理,桥接游戏 runtime 侧的 debug agent 的 WebSocket 和 ide 侧的 Socket。
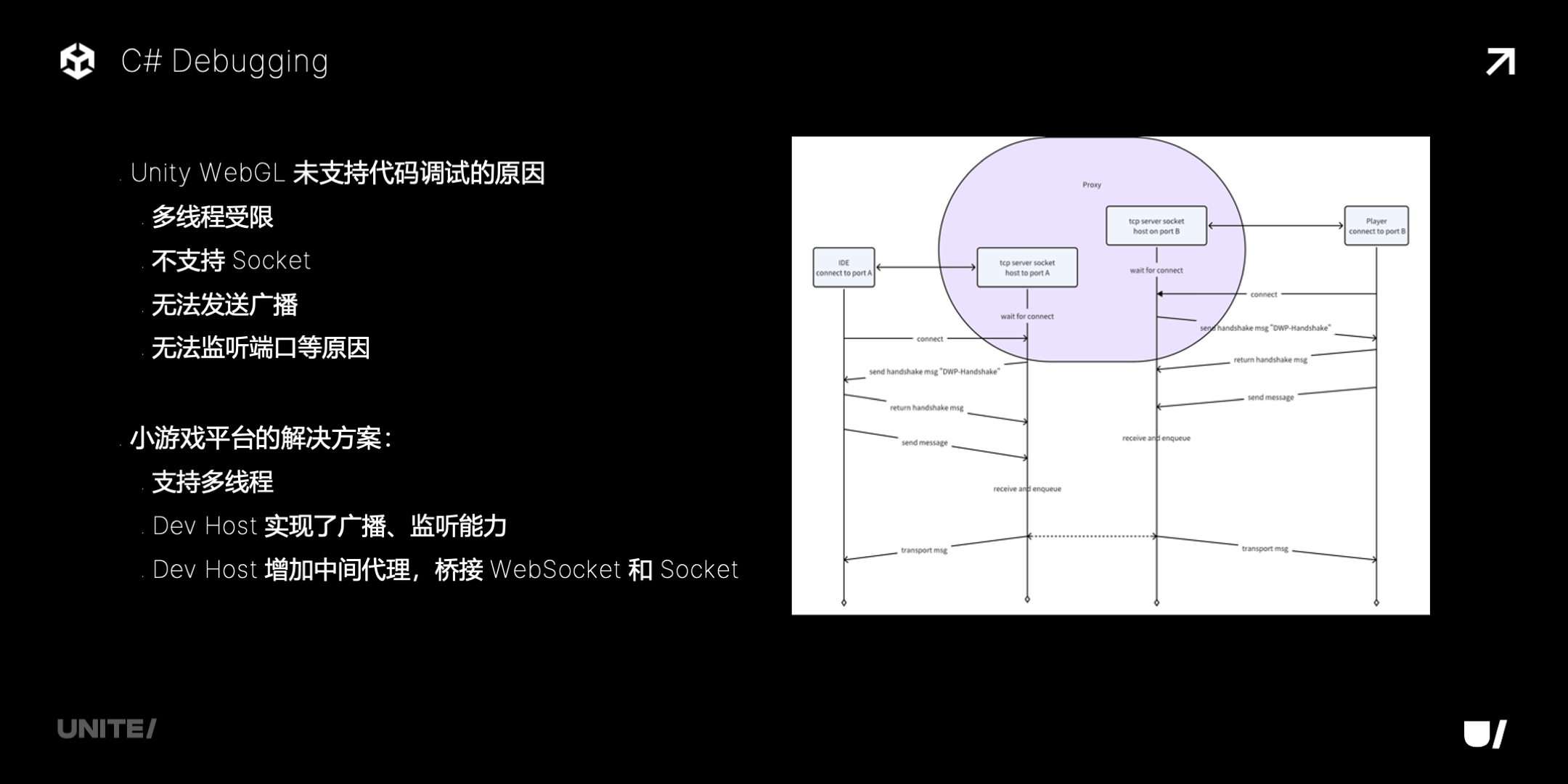
下面是具体的用法,打包时勾上 Scripting Debugging,Dev Host 上扫码然后打开这里的开关,在同一个网段内就可以调试了。有一点需要注意,现在暂时还不支持 .Net 8。
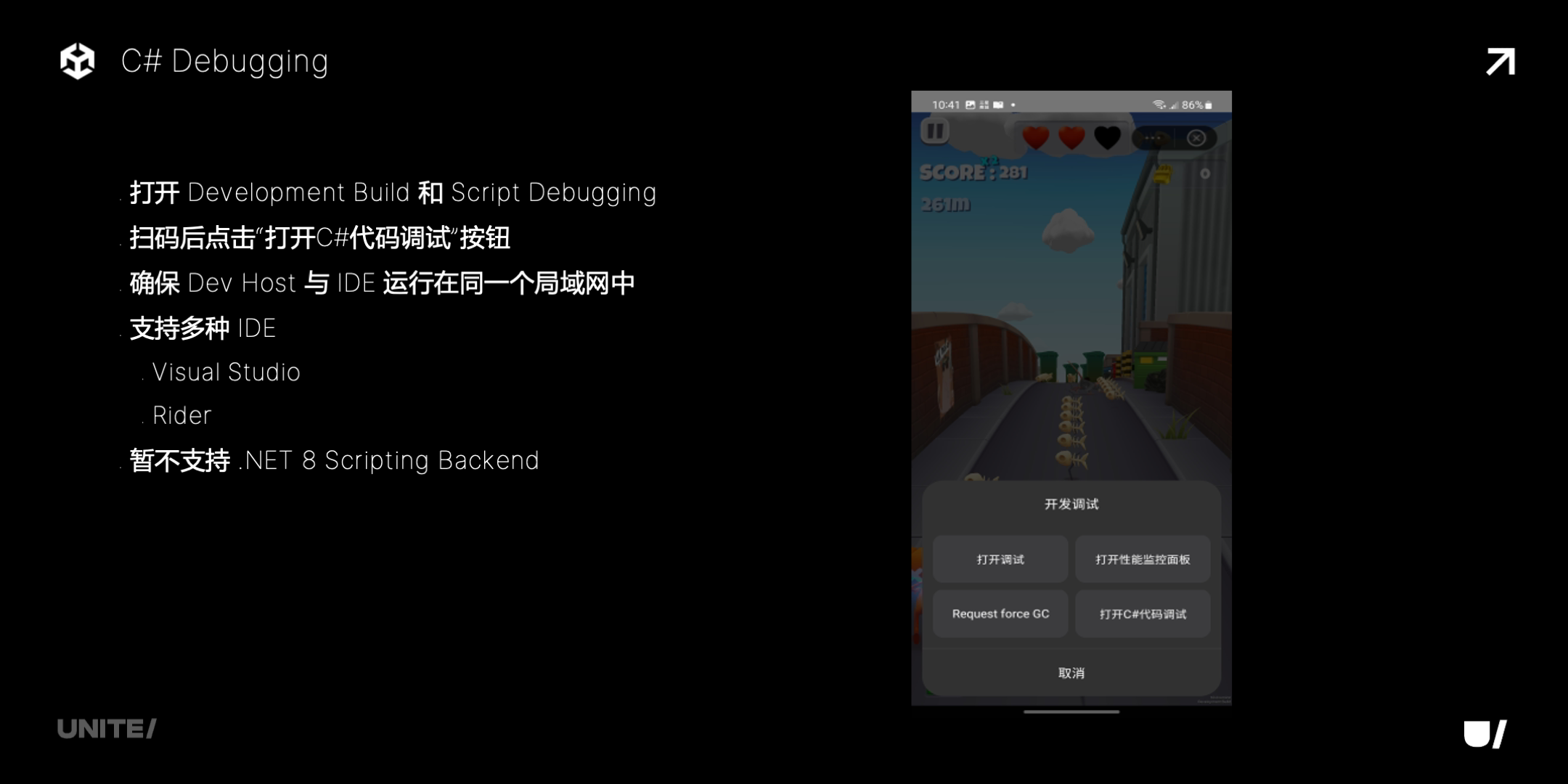
下图是一个案例的截图,Attach to Unity Process 之后,就能搜到可以调试的小游戏进程,然后就和传统的调试一样了。
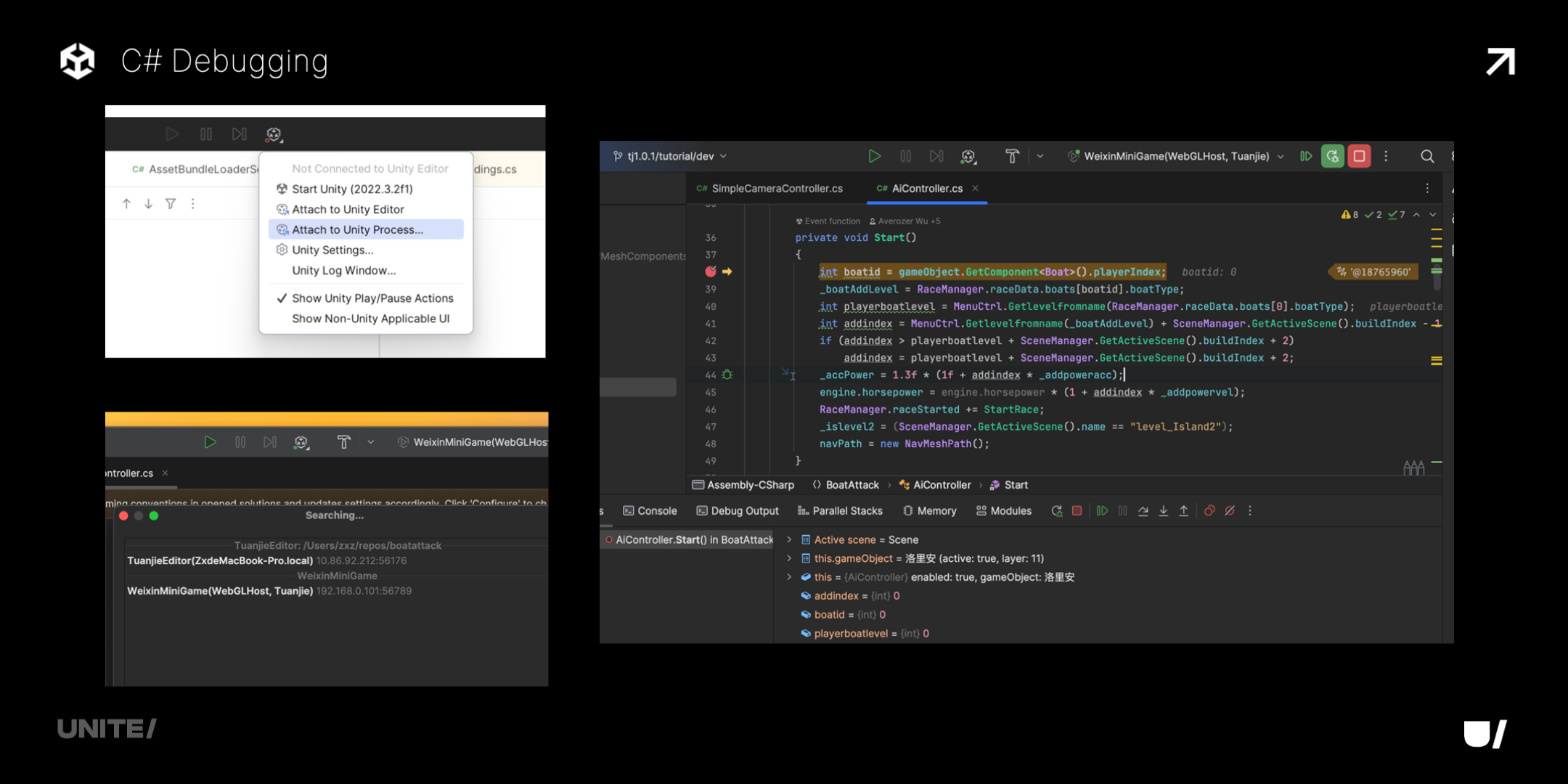
最后,展望未来部分继续交给赵亮。
未来展望
赵亮:接下来介绍一下我们目前正在开发中的功能,以及未来的探索方向。
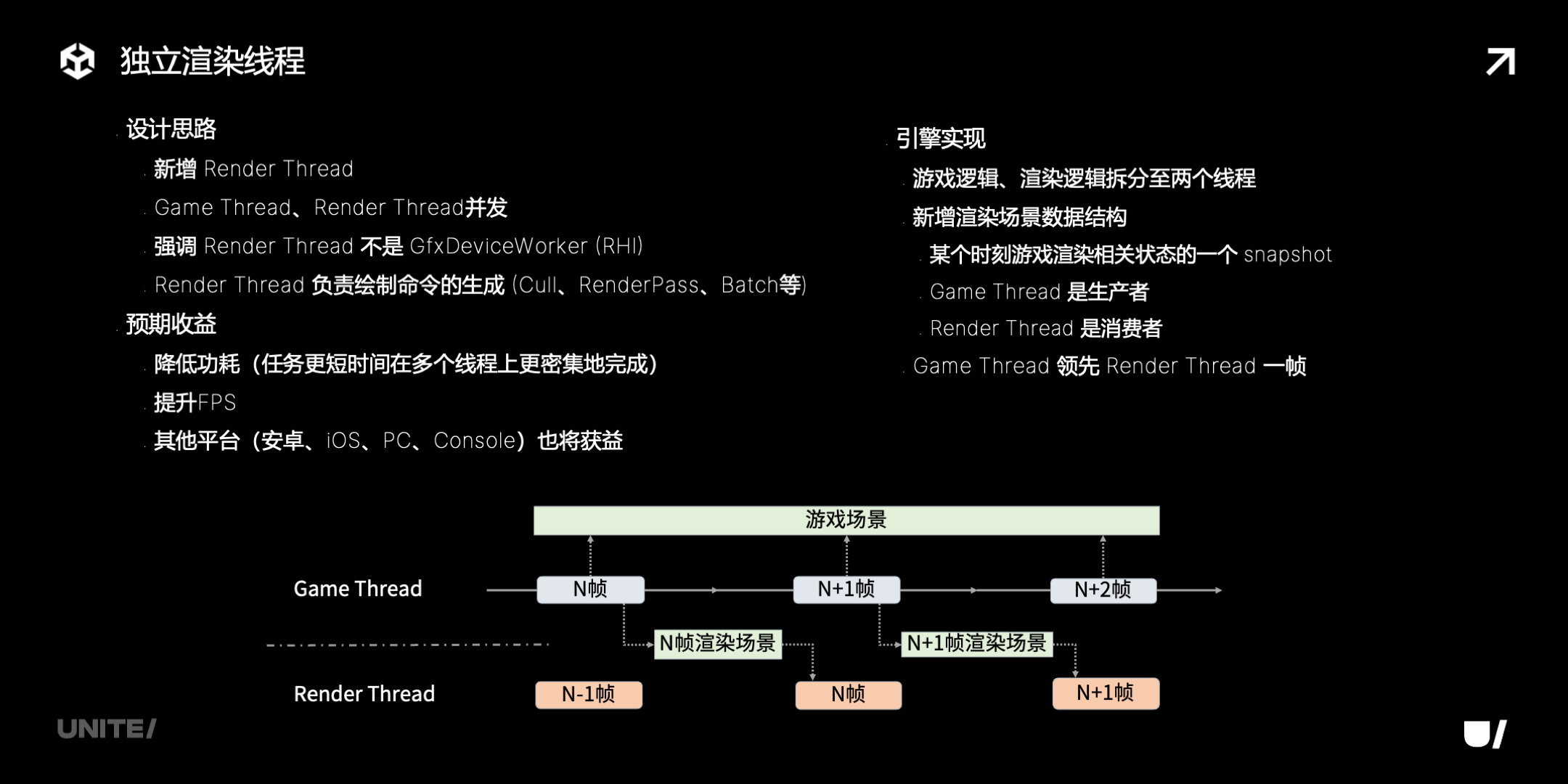
我们目前正在开发独立渲染线程,可以降低功耗、避免发热降频。我们在与微信一起探索小游戏平台能力的扩展,以及引擎如何利用这些扩展的能力提升小游戏的性能和画质。
这里还将介绍一下 Native 侧管理重度资源的思路,可以进一步减少内存、提高 CPU 侧运行性能。还有游戏场景加载的速度,我们一直在不断优化。
前面提到了 Spine 在 .Net 8 scripting backend 下遇到了性能问题,我们针对这个问题做了专项优化,把重度的计算从 C# 转到 C++ 实现(主要是 apply animation, build mesh 这些比较重的方法)。目前性能可以对齐 IL2CPP,已经有开发者在试用我们这个方案了。
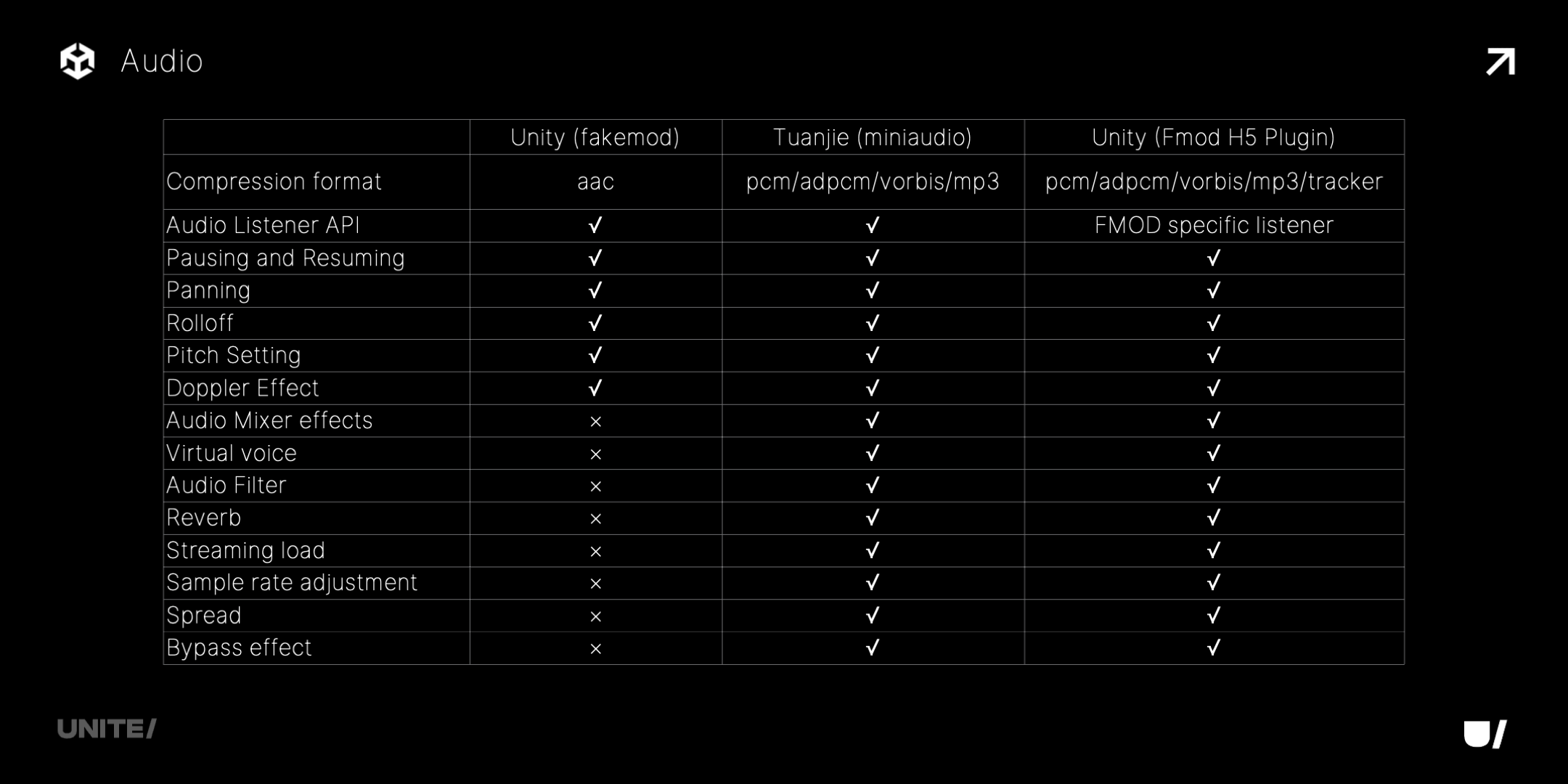
目前小游戏上,Unity 使用 Web Audio API 来播放声音,功能很受限。我们正在通过 miniaudio 解决这个问题。还有 WebGPU,我们也在做预研和测试。

首先看一下独立渲染线程。开发这个 feature 主要目的是降低功耗。苹果开发文档推荐的策略是,将任务集中在一起并发执行。虽然在并发执行的时候功率更高,但任务快速执行完毕后,CPU、内存、缓存、总线都可以进入空闲,所以总能耗会降低。因此使用多线程可以降低功耗。
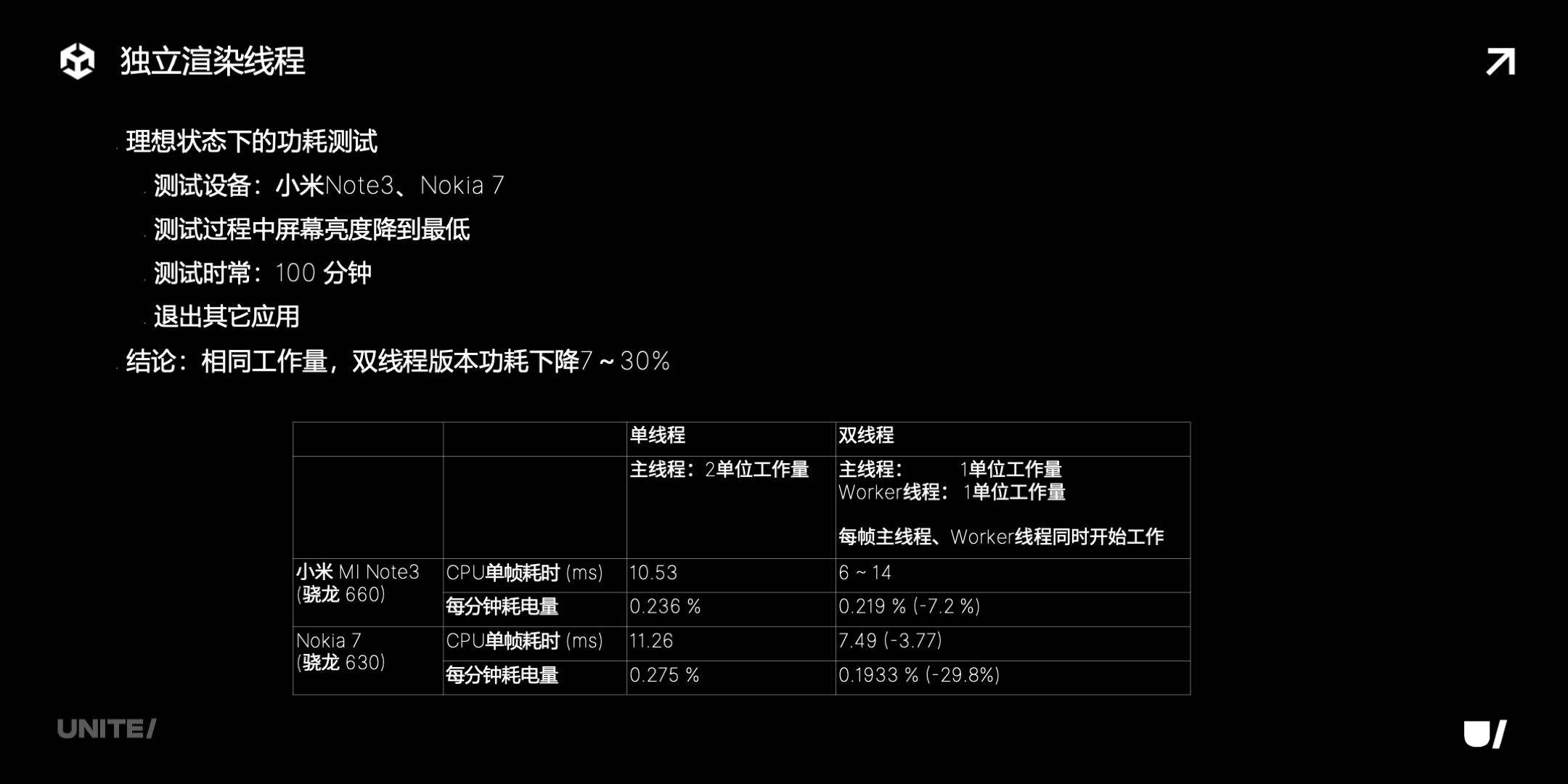
我们设计了一个对比测试用来验证这个结论。使用同样的工作负载,测试单线程与双线程 demo 的功耗。在测试过程中,把屏幕亮度降到最低,减少屏幕亮度对于功耗的影响,同时退出其他程序,减少干扰。
右边的表格是 iOS Safari 上的测试结果。虽然多线程版本 CPU 占用率更高,但它耗电量降低了很多。每分钟耗电量降低了 42%,电池输出电流平均值从 701mA 降到 411m,电池的温度也因而降了 3 度多。

下面的表格是安卓设备的测试结果,功耗优化程度跟 iOS 相比有所差异。
·小米Note3,使用(骁龙 660 芯片),耗电量下降 7%。
·Nokia7,使用(骁龙 630 芯片),耗电量下降 29%。
虽然在不同设备上功耗优化程度有所不同,但功耗均有可观的下降。
小游戏目前是单线程,为了降低功耗,我们把它改造成了双线程。
具体思路是:游戏中一帧的耗时可大致分为两部分:一部分是游戏更新逻辑、另一部分是渲染逻辑。这两部分的耗时虽然不像测试案例那么理想,刚好 1:1,但是是一个数量级的。因此我们设计成一个线程执行游戏更新逻辑,另一个线程并发执行上一帧的渲染逻辑。
为了实现逻辑和渲染的并行,对引擎架构的改动比较大。主要是渲染相关的数据结构。游戏逻辑的执行,会改变渲染数据,例如物体移动、光照变化。Game thread可以理解为渲染数据的生产者。这些渲染相关的数据,再交由 render thread 去裁剪、组织 render pass、生成具体的 render command。Render thread 可以理解为渲染数据的消费者。两个线程并发,需要处理好线程同步和数据访问策略。既要高效访问,又不能读写冲突。还要处理好数据的生命周期,避免浪费内存。
独立渲染线程预期在今年 12 月会有一个小游戏平台的 preview 版本发布。
接下来看小游戏平台能力的扩展。
微信在 iOS 平台上引入了高性能+方案,使平台对 WebGL 能力进行扩展有了可能。我们第一步将探索、引入部分 GLES3.1 的能力,从而提升小游戏的绘制效率和绘制效果。我们有望在小游戏中也能用上 BatchRenderGroup 和 VFX 等高级特性,甚至用上 GPU Driven 能力从而弥补小游戏 CPU 性能偏弱的天然缺陷。
团结每 3 个月发布一个 feature 版本,在接下来的几个 feature 版本中,我们将逐步推出这些扩展能力的支持。从下面的录屏可以看到,我们已经可以在微信上跑 BatchRenderGroup 的 demo 了。
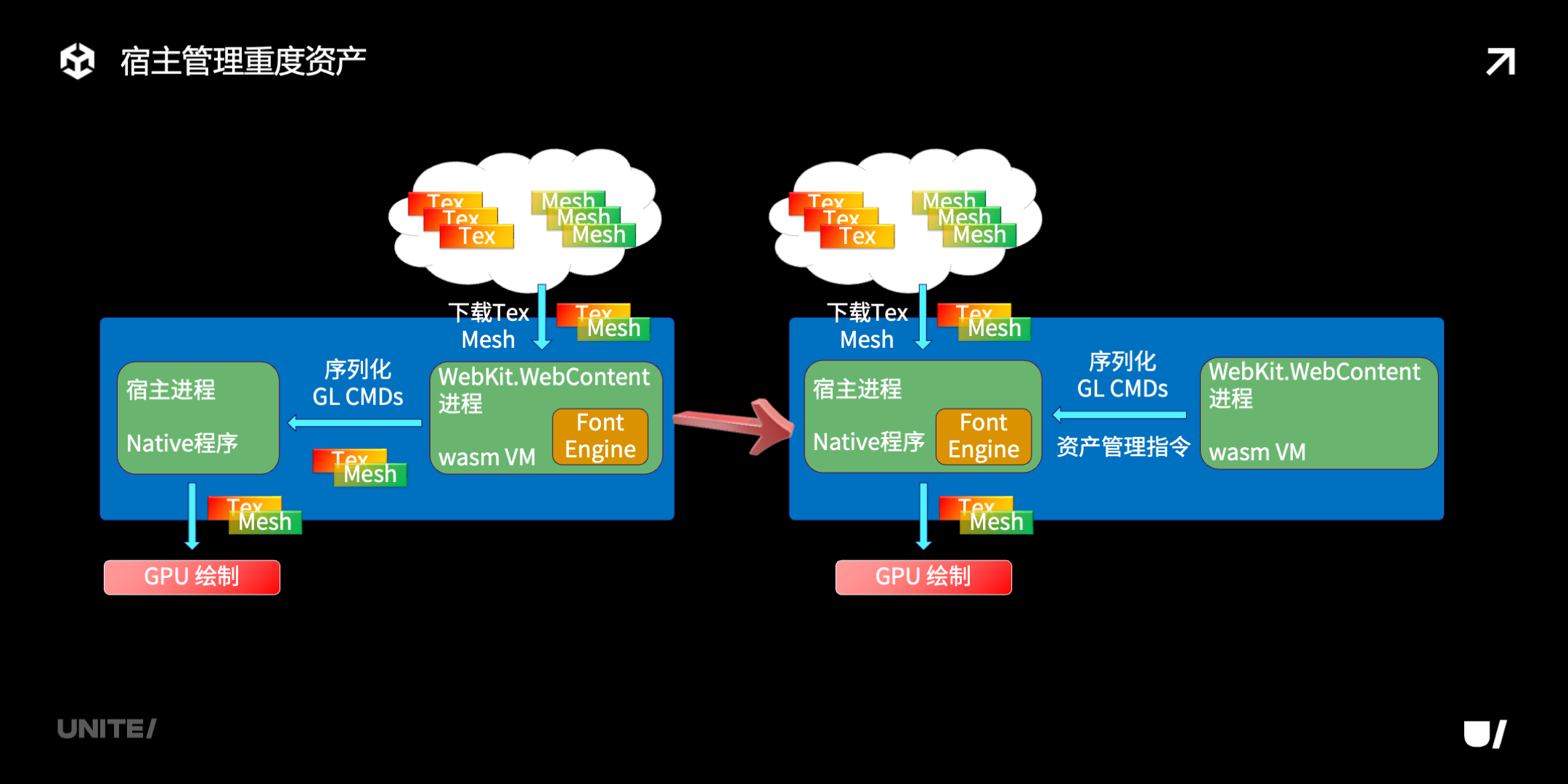
这里介绍一下宿主侧管理重度资产的思路。把 texture/mesh 这些重度的资产交给宿主进程管理,可以进一步降低小游戏内存占用,减少 oom 的概率;同时提高缓存访问效率、提升加载速度。我们也在考虑把 font engine 转移到 native 侧,既可以减小 WASM 大小,又能通过本地文件系统高效地访问操作系统提供的字体。
Unity 集成的 fmod 版本比较低,不支持 web audio。在 WebGL 平台上,Unity 直接使用 Web Audio API 来播放声音,功能比较受限。在团结引擎上我们使用 MiniAudio 替换了 fmod,MiniAudio 是支持 Web Audio API的,我们正在通过 MiniAudio 来补齐小游戏平台上的声音功能。很快就将推出试用版。
WebGPU 代表未来的发展方向。它有着一系列优势,可以更好地发挥现代 GPU 的能力,它与 vulkan/metal/dx12 更加接近,可以更好地支持 GPU driven 渲染管线。它支持 compute shader/command buffer/indirect raw/pipeline state object 等等。
为了充分发挥 WebGPU 的潜力,引擎侧需要做的重构工作比较多,主要包含两部分:
-
升级 GfxDevice 的接口,适配 WebGPU。而不是用 WebGPU 去实现旧的 GfxDevice 接口
-
重构渲染管线从而更好地利用这些能力。
由于这块的工作量较大,且各个平台对 WebGPU 的适配走向成熟稳定,还需要时间。我们跟微信沟通后,目前均认为小游戏要用上 WebGPU 还需要一段时间,应该是一到两年的时间。

今天先分享到这里,希望广大开发者能用团结引擎开发出更加优秀、更加成功的小游戏,谢谢大家!

分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐


 17
17 2
2- 0



 已为社区贡献739条内容
已为社区贡献739条内容

所有评论(0)