
末世科幻游戏《星球:重启》在 Unity 中的技术基建揭秘
星球:重启》是一款以外星降临的末世为背景的科幻生存 RPG 游戏,鼓励玩家自由探索、创造未来世界。因其出色的创意和设计,曾荣获 2022 年华语科幻星云奖最佳科幻游戏创意奖。游戏通过独特的科幻世界观和前沿的技术应用,为玩家打造了一个超越现实的未来图景与富有科技感的丰富场景,将对地球与人类未来的想象延伸到了另一个空间。在 Unite Shanghai 2024 游戏生态专场演讲中,字节跳动江南工作室
《星球:重启》是一款以外星降临的末世为背景的科幻生存 RPG 游戏,鼓励玩家自由探索、创造未来世界。因其出色的创意和设计,曾荣获 2022 年华语科幻星云奖最佳科幻游戏创意奖。
游戏通过独特的科幻世界观和前沿的技术应用,为玩家打造了一个超越现实的未来图景与富有科技感的丰富场景,将对地球与人类未来的想象延伸到了另一个空间。在 Unite Shanghai 2024 游戏生态专场演讲中,字节跳动江南工作室引擎技术总监王超先生,分享了《星球:重启》的引擎技术揭秘。他的演讲内容主要分为图形渲染、超大场景、内容生产三部分。
图形渲染

1. 渲染批次组织
渲染批次组织的关键词是 Hybrid。多种方法结合使用,针对每一类的渲染对象采用最优的方法。
第一种方法是我们场景中大部分物体使用的,Unity DOTS 技术栈里的基于 ECS 的渲染。下图有一个量化的对比表格,这个是 GameObject 渲染和 ECS 渲染的数据对比。

在 PC 上帧时间的提升大概是 5 倍,在移动设备上这个倍数会低一点,可能是 3 倍左右,并没有达到网友们在实验条件下的几十倍的提升,因为我们的实际游戏场景中东西非常的丰富,拆成的批次非常多,所以每个 chunk 之间的 instance 的数量参差不齐,达不到数十倍提升,但其实三倍已经是很香的提升了,比如说我们原来渲染一帧需要 16 毫秒,三倍提升以后是 5.33 毫秒,所以即使大量批次中的实例很少,用 ECS 相对 Game Object 也是有巨大的提升。
我们在官方的版本 ECS 上做了两个优化,第一是可变的 chunk 大小,这个是用来应对刚刚说的 chunk 利用率的问题。第二是原版的 ECS 里面,一个 mesh 的多个 submesh 是分别当作不同的 entity 来分别进行 culling 的,这里有一个重复计算的问题,所以我们做了 submesh 之间的合并 culling。
第二种方法是 Hierarchical culling。


顾名思义是有层级。我们构建的是 BVH,什么使用场景下才需要构建 BVH?就是有数量特别庞大的物体。ECS 里面是针对整体的 chunk culling 之后再进行逐个 instance 的 culling,instance 数量特别多的时候,多到 culling 的计算开销过大,这时候就需要 BVH 了。
顺便一提的是,我们的 hurricane hierarchical culling 也是充分利用 Brust 和 Jobs,它的并行程度虽然低于 ECS,但是实测上整体的 culling 耗时是下降的。另外对于特别大量的草之类的物体,除了使用序列化的 instance 来描述之外,还能用密度图描述,运行时生成 instance。
第三种方法是 GPU culling。

我们使用 BatchRendererGroup,针对每一组的 Mesh 和 Material 的组合去发起 indirect draw call,它在执行的时间轴上与光栅化里面的 shadow map 的 pass 是并行的。这个的结论是,在一部分移动设备上,对于一部分类别的渲染对象,GPU culling带来了性能收益。
2. 遮挡剔除
遮挡剔除是两种方法之间的 hybrid,首先我们针对主流的多个遮挡剔除算法做了对比实验,实验的指标是在测试场景的多个视角下的平均剔除率,实验结果与预期是一致的,实时方案的剔除率高于预计算的方法。

其中 query 在比较完善的 GPU driven 的管线上是一种比较好的方法,但是目前不适合移动平台。所以我们的首选是剔除率最高的 Hi-Z,它在 GPU 上做生成,所以效率高;次优选择 software,剔除率同样高,但是需要一部分的 CPU 的开销。

Hi-Z 的问题是使用的是上一帧的深度图,所以在某一些场景下有错误剔除的问题,这类的错误剔除无法通过 reprojection 完全避免。我们通过仔细观察,发现这类剔除错误常见于相机位于较大的墙面附近,并且在墙面边缘来回移动的时候,所以我们想到了一种 hybrid 方法,把 Softwore 和 Hi-Z 结合起来,通过在主要的墙面去放置遮挡体的 proxy 模型,运行时实时获取 proxy 在相机视野中的 coverage,根据这个 coverage 有没有超过一定的阈值,如果超过阈值我们就切换到 Softwore,其他大部分的时候使用的是 Hi-Z,起到了两种方法取长补短的效果。
3. 多线程渲染
我们针对 Unity 默认的 native 模式 graphic jobs 进行了改进,下图是 native 模式的 graphic jobs 流程图。

我们发现有这些可以改进的地方:
第一,它主要的并行性来自 draw objects job,这个 job 是针对 SRP 里面的 draw renders 和 draw shadows 这些单个命令名来拆分的,它的问题是不同的命令之间是串行处理的,这导致在实际的游戏场景中,每个的 draw 命令包含的实例数量是不等的,所以这个 job 的并行性就无法完美地发挥出来。
第二,主线程的工作仍然较多,包括处理 SRP 命令,准备 job data,这些都是在主线程串行的处理。
第三,这里会生成大量的 secondary command buffer,一个是额外开销高,另一个是如果并行性完全依赖于 secondary command buffer,那么在某一些有兼容性问题的安卓设备上就开不起来这个 graphic jobs。
下图是我们改进之后的 graphic jobs 流程图:

主要发现有三点,第一点是 SRP 命令在 job 线程里处理,主线程的工作非常少,第二点是 render pass 之间能够并行起来,第三点是多个 draw renders 命令能够合并起来之后,再统一地进行拆分 job,这样并行程度得到了显著提升。
4. 渲染管线
我们基于 Unity 的 SRP 构建了自己的自定义渲染管线。有 3 个目标,第一是高品质,第二是伸缩性,指的是在尽量一致的渲染流程里伸缩到高端的 PC 和中低端的移动设备,希望能够以同样的流程伸缩。第三是工程性,这其实是前面两个目标带来的,我们在渲染流程里有更多的 hybrid 方法,这时候如果不做工程性的思考,代码的分支很容易变成一棵指数级生长的树,维护起来是一场灾难,为了给渲染工程师提升生活质量,我们必须关注工程性。
我们在渲染流程里一个基本的选型是延迟渲染。

对于高品质的目标来说,很自然用 Clustered culling 能够支持大量的光源,然后基于 G-buffer 能够实现丰富的渲染特性,在着色阶段能够支持较为复杂的计算,多平台的画面由于都是同样的延迟渲染,所以能够做到尽可能地对齐。
对于伸缩性目标而言,首先移动端基于 tile-based 的实现,我们实测下来延迟渲染的性能表现是非常优秀的,它会显著地快于forward渲染。超高三角形带来的 4-pixel quad 的问题,在延迟渲染中它的影响会显著降低。下面是由于渲染被拆分成了不同的阶段所以形成了较短小的 shader。另外,我们把不同的 shading model 拆分成了不同的 shader,也会导致每个 shader 比较短小。短小的 shader 能够提升 GPU 调度线程组的能力,更好地进行 latency hiding。
我们在移动平台上的 tile-base 的 G-buffer 实现原理,分为四个不同的平台。

下一点是 Render Graph。

为了以良好的工程性达到伸缩性目标,如果没有 Render Graph,我们会遇到代码中大量的分支。“大量”来源于这几点:首先是大量可开关的图形特性,然后是平台数量乘以质量分级,这里有一个组合爆炸的问题,然后是根据平台是否支持来选择性地使用 subpass,然后是每一个 GPU 的 resource 的资源生命周期、store action、memoryless 等等都需要分别设置。
Render Graph 有一个很重要的点,是因为它是在运行时进行编译的,所以编译器的性能优化是非常重要的,我们仍然是重度地利用了 Burst compiler。
Render Graph 其实这些年已经较为常见,这里主要讲一下我们针对移动端做了什么优化。

移动端的编译器有一个很重要的部件叫 Pass Combiner,有了这个 Pass Combiner 之后我们在编写渲染流程的时候就不用管 sub pass 这个概念了,也不用管 pass 之间什么关系,只需要把每一个步骤当作一个 pass 来表达,只需要声明这个 pass 对所有的 RT 的读写行为,然后这个 Pass Combiner 会自动地去合并相邻的 pass,把相邻的 pass 合并成同一个 render pass,原本编写流程中的 pass 就变成了一个一个的 sub pass。
在不支持 sub pass的平台,我们发现对 GLES 也是有显著性能提升的,因为我们把相邻 pass 的 RT 的集合变成一个并集之后,pass 之间不再需要切 RT 了。
5. 渲染特性

首先讲一下全局光照,我们使用了 irradiance volume,它是覆盖全场景的预烘焙的大量 probes。覆盖一个大世界场景,我们不可能不使用稀疏存储的球谐系数来表达间接光和遮蔽信息。
第二个图展示了遮蔽信息的合成,看到遮蔽信息分别来自前述的 irradiance volume、材质纹理、屏幕空间计算的遮蔽,以及最终画面渲染的结果。稀疏存储的数据 GPU 用不了,我们必须在运行的时候根据相机的实时位置来 streaming 地加载稀疏存储的数据,以及进行解压缩,利用 clip map 的思想去局部更新一张 3D 纹理,这个 3D 纹理是真正用于 shader 里面着色的 irradiance volume。
全局光照还有一个 Hybrid 方法。

前面说的 irradiance volume 有一个天然的缺陷是缺乏高频的信息;另外一种较为广泛使用的是屏幕空间的方法,也叫 SSGI,它的天然缺陷是缺乏屏幕外的信息。所以我们想到了在屏幕空间去 trace 时候,除了探测几何信息之外,还可以去采样 irradiance volume,这样两种方法之间的天然缺陷可以相互弥补。
全局光照怎么实现 Time of Day 呢?因为我们是预烘焙的,离线烘焙多个离散的不同太阳光照角度,或者昼夜,在不同的光照之下烘焙出多组的 irradiance volume 数据,然后输入到一个神经网络里面训练,在运行时可以实时解压,实时推理出在任意给定的光照方向、任意给定的昼夜时刻上的数据。

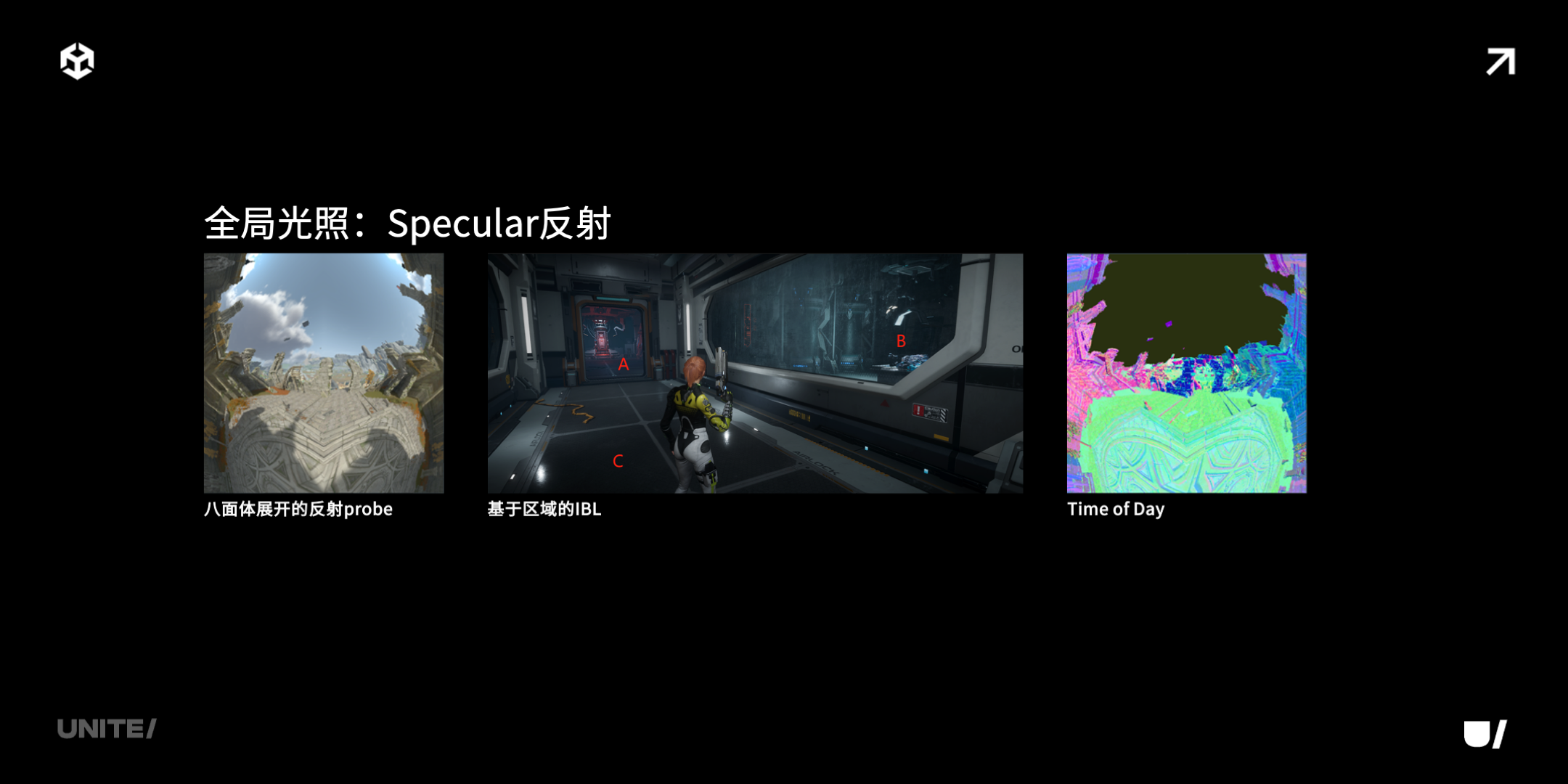
全局光照还有一个部分是 Specular 反射,Specular 常用的是 cub map,我们这里使用的是经过八面体展开成平面的,把球面展成平面的 2D 反射纹理。它的好处一个是采样效率高,另一个是信息密度均匀。
下图二中有三个区域,如果这些区域用同一个反射的 probe 效果肯定是不对的,所以我们运行的时候需要 streaming 加载多个区域的 2D 反射纹理。这带来了 2D 纹理另外一个好处,它可以组成动态的纹理数组。每个渲染对象应该采样哪一个反射纹理,这里有一个 index,是作为 instance data 存放在 draw call 的数据中的。第三点 specular reflection 怎么实现 TOD,它的做法比较直接,我们在 2D 的反射纹理里存的就不是颜色了,存的是 G-buffer 的数据。
全局光照还有一个屏幕空间反射的成分,左边用于水平面,是一个性能比较高,在移动端也完全可以适用的 SSPR 的算法;右边主要用于 PC ,用来呈现任意不规则几何表面的屏幕空间反射的 SSR 算法。

关于全局光照的更详细的内容,以及关于高品质的阴影技术在游戏中的实现,我们在往年的 Unity 技术开放日上有两篇不错的分享:
https://www.bilibili.com/video/BV1Rz4y1372T/?spm_id_from=333.999.0.0
https://developer.unity.cn/projects/60efe674edbc2a0159e317cf

我们的抗锯齿算法,可以看到从左往右是高规格到低规格,高规格主要是用于 PC 平台,TAA 可以用于 PC 也可以用于一些高端的手机设备。

TAA 和 FXAA 使用 RCAS 锐化,RCAS 是我们从 FSR 里抽离出来一个算法中的锐化步骤,我们发现把 RCAS apply 到 TAA 和 FXAA 之后,最终的画面结果可以得到一个非常显著的提升。
超大场景
超大场景方面主要实现以下目标:

第一是大量的三角形和大量的物体,第二是丰富的 Mesh 和丰富的材质,第三是视距至少需要 1000米,也可以达到 2000米甚至更多,第四点是跨平台,不仅考虑移动设备的渲染性能,还要考虑 iOS 等设备的内存压力。

一个比较常规的做法是场景需要 streaming 加载,我们做的是把地图均匀地分割成边长为 64 米的正方形地块,这个地块一般称为 chunk,在我们这里作为场景的存储单元,叫做 block。加载一个 block 的时候,如果远处有一个 block 要加载,里面的大型建筑和小型的物体会全部加载进来,这显然是不合理的,所以我们额外做了一步是把物体按照它的可视距离来分层。在块里面分层,块是我们的存储单元,层是我们的加载单元,我们根据相机靠近的方向以及 assets 在运行时估算的屏幕空间的尺寸,按一定的优先顺序加载,这样会达到最佳的视觉表现。
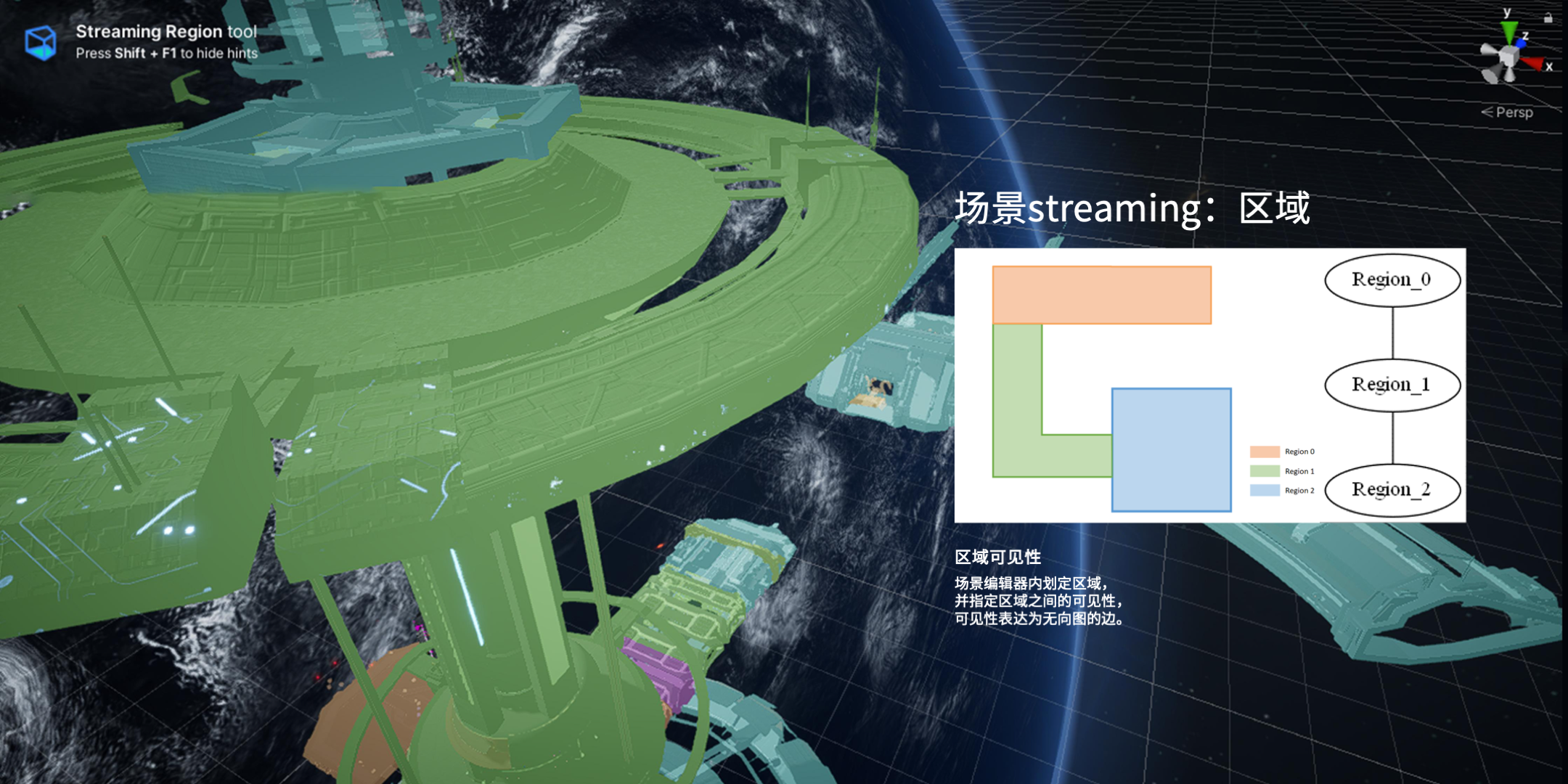
除了均匀分块之外我们做了一套基于区域的加载。这个是用于繁杂的都市、建筑、室内的场景,每个区域可以认为是一个图上的节点,区域之间的可见性就是图上节点之间是否存在边,运行时候可以根据区域之间的可见性,判断相机当前在哪个区域,就可以把那些可见的区域加载进来,看不到的区域就可以卸载掉。

大世界必不可少的一点是 HLOD 的生成,我们想在降低三角形数量的同时,还要确保最优化的 UV 的排布,以及确保最高度的材质贴图的复用率。我们为了对 HLOD 生成算法有更多的可控性,自己研发了算法。

HLOD 对于模型生成的方法有两种,一种是模型简化,一种是模型重建。美术同学可以在编辑器里针对每一个模型指定他要使用哪种方法生成,在某一些 case 下我们可以看到模型重建的效果比模型简化的效果好非常多,可以避免非常多的破碎表面。

当我们有非常多的 mesh,我们做了 HLOD 运行时会加载进来更多的 mesh,这时候 mesh 的数量也会对内存造成压力。所以我们通过对 mesh 顶点数据进行紧凑编码缓解这个问题,这个对 iOS 设备的意义非常重大。屏幕上的数字是 mesh 的各个通道在编码之后大小相比原来大小所占比例,除了内存降低,还可以让带宽消耗降低了相似的比例,包体占用也是有所下降。

编码 Position 最简单的一个方法是用 half,但是 half 的问题是它只有 10 个有效位,另外 6 位是符号位和指数位,会导致顶点位置失真比较严重。所以我们使用的是 SNorm16×4,其中有一个 W 分量是用来存储 scale 的,这个 scale 是 X、Y、Z 绝对值的最大值,我们把 X、Y、Z 分别除以 scale 之后存下来。它很像 HDR 颜色的 RGBM 的编码方式,这样做 X、Y、Z 能够获得接近 16 个有效位,顶点位置的失真变得很微小。

normal 和 tangent 的编码跟前面很类似,我们把这个球面映射到八面体,再展开成平面之后,就可以用平面的坐标表达球面的坐标了。相比常见的球面坐标,八面体展开之后的编码精度会更加均匀。这里平面坐标使用的是 2 个 SNorm8, tangent 还有一个 W 分量需要额外占用一个 Bit 来表示。
内容生产工具链

内容生产指的是美术、策划、音频等等的同学,在引擎编辑器内,以及外部的 DCC 软件中为游戏制作内容的工具链和工作流。工具链的设计开发是非常重要的事情,做好了不仅能极大提升内容生产的效率和质量,还能极大提升开发组同学的生活质量。今天我们聚焦场景编辑器。有这三个目标:超大场景、团队协作、高效生产。
首先,应对超大场景我们使用分块编辑器,这个图上显示的每一个有颜色的小格子,是一个块。这是我们的导航面板,有小地图、工具栏,它整合了地图编辑信息和编辑工具的入口。
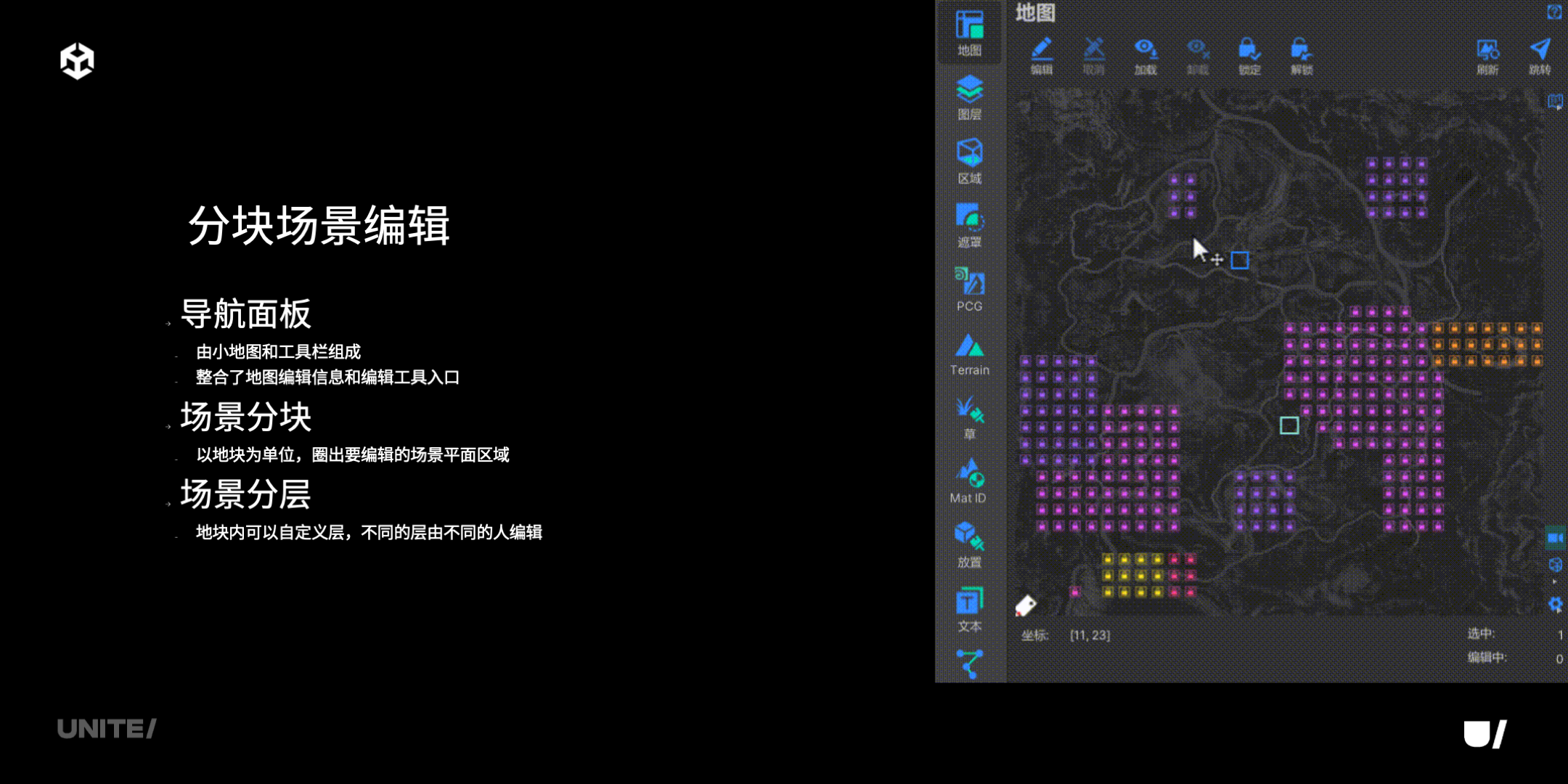

动图中框选意思是,现在要编辑哪个区域我就可以把它选出来。除了分块之外我们还可以在块内创建自定义的层,不同的层由不同的人、不同的职能来编辑。
基于分块还有一个非实时的协同编辑。


这个非实时的协同跟版本管理软件是同步的,可以看到上图中每个地块,用不同的图标就可以表示这个块的不同状态。大约有这几种协同编辑的状态:比如这个块在本地加载还是卸载,第二是被我锁定了,第三是被其他人锁定,第四是我正在编辑,第五是其他人提交了新的数据,我现在的本地数据是旧的,最后是我正在跟 perforce 进行同步。
场景编辑器的性能是非常重要的,下图中选中了一棵小草,如果说一个大世界的场景中每一棵小草都能够选中、都能够编辑的话,那么如果是基于 GameObject 的场景,它一定是难以去在编辑器里加载出来的,也难以用实时的帧率渲染。所以我们要做的是序列化和加载的阶段采用自定义的数据格式,然后在编辑器内也使用 streaming 加载;在编辑场景的渲染阶段运行时采用类似基于 ECS 的渲染。由于现在没有 GameObject,直接编辑的是 ECS 的 entity,所以我们需要制作自定义的编辑工具。

程序化生成这里分为全局和实时交互两类。我们打通了 Unity 的场景编辑器和 Houdini,打通的桥梁是 Houdini engine for Unity,然后我们利用一个 daily build 的 CI 在每天去构建一个全局生成的场景,如下图所示。


比较有意思的部分是实时交互的 PCG。

举三个例子,第一是道路工具,可以看到动图中绘制折线来形成道路的路径,这个工具会自动修改道路所覆盖地面地形的材质ID,还会删除道路上的草。

第二个例子是管道工具,同样也是绘制折线形成管道的路径,这个工具会自动摆放模块化管道的模型,并且确保顶点是对齐的,还要确保是进行自动打组的。
第三个例子是线缆的工具,绘制线缆的起始点,这个工具会自动去计算观感自然的线缆下垂状态,生成线缆的Mesh。
在 Unity 实现 Houdini 的丰富节点功能成本太高了。我们在本地后台启动了一个 Houdini 的服务进程,打通了 Unity 和 Houdini 之间的数据格式和数据交换,在 Unity 中只要实现用户的交互操作就行了。

未来工作
最后简单讲一下我们的未来工作。
主要是三个方面:第一是提升跨平台的品质上限,比如虚拟几何体和实时全局光照在移动平台的落地。第二是AI技术在运行时以及内容生产阶段的应用,这一页 PPT 上的两个图也是用AI生成的。第三是支持下一代的游戏产品,我们会有另一款更加重磅的科幻题材的大作,还会有一款年轻人喜欢的 UGC 的产品。


分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐


 22
22 0
0- 0



 已为社区贡献739条内容
已为社区贡献739条内容

所有评论(0)