
UUG北京站 | 重度游戏在小游戏平台下的探索与实践
演讲资料PPT下载地址:https://u3d.sharepoint.cn/:b:/s/UnityChinaResources/EVI_8TXp-xFIpI6wmRVmrUkBf25eruL8jV0xFHWplb1wwg?e=pLF8cy在2025年5月24日的Unity User Group北京站活动中,完美世界《诛仙手游》客户端负责人刘彦麟带来分享《重度游戏在小游戏平台下的探索与实践》。刘彦鳞
演讲资料PPT下载地址:https://u3d.sharepoint.cn/:b:/s/UnityChinaResources/EVI_8TXp-xFIpI6wmRVmrUkBf25eruL8jV0xFHWplb1wwg?e=pLF8cy
在2025年5月24日的Unity User Group北京站活动中,完美世界《诛仙手游》客户端负责人刘彦麟带来分享《重度游戏在小游戏平台下的探索与实践》。

刘彦鳞:我来自完美世界《诛仙手游》项目组。本次分享的内容聚焦于完美世界小游戏开发的经验,特别是小游戏下WASM和堆内存的优化方案,以及团结引擎对于小游戏的技术支持。
我们的小游戏移植工作启动于2023年中旬。然而,早在几年前,尝试小游戏的想法就已经萌生,并且进行过技术尝试。这其中包括对Unity和其他H5引擎的探索,但由于未能达到预期的综合目标,这些尝试最终未能继续推进。
随着2022年和2023年小游戏市场快速发展,以及大量“爆款”涌现,其中不乏MMO(大型多人在线)、SLG等中重度游戏也表现出色。无论从产品、运营,还是从技术角度来看,都促使我们决定再次尝试小游戏平台。
经过约半年的调研和分析,发现无论是市场前景还是技术承载能力来看,都存在机会。因此,我们在2023年6月正式启动小游戏的项目。经过约半年时间的移植工作和产品 调优,项目从2024年的1月开始对外进行多轮CCB测试,今年1月,在微信小游戏平台开启正式OB。目前,开发团队也正在进行抖音平台的性能调优,后续还会发行到更多小游戏平台。

MMO类游戏因其固有的特性,即使在硬件资源丰富的端游或手游平台上,如果技术方案欠妥,亦可能产生相当大的性能问题。这因为此类游戏需要更大内存,更大的计算承压(包括CPU与GPU),且部分功能需要多线程支持,而这些问题在小游戏平台上将进一步放大。这其中,内存和CPU是相对关键的要素,亦是攻克小游戏平台性能瓶颈的关键点。

在小游戏平台上,iOS设备的内存普遍限制在1.4G。然而,在手游平台上,1.4G仅是部分低端机型的内存阈值,且此类机型在APP平台上的占比极小。此外,小游戏平台的CPU性能大约仅为手游的1/3,并且不支持多线程,这使得小游戏平台对密集性运算更为敏感。然而,重度游戏恰恰需要大量计算,以及运行时的内存支持。同时,Unity 中的许多功能也依赖多线程支持,例如动画、蒙皮、粒子系统和物理系统。一些功能甚至会借助 Job System 来加速计算。然而,在小游戏平台上,这些功能都会转为 主线程上的线性计算,不仅无法利用多线程优势,还会抢占主线程资源,进一步加重运算压力。

小游戏内存主要分为几个方面,其中影响最大是UnityHeap、WASM以及GPU显存,这三者是移植后造成小游戏平台内存暴增的主要因素,只要妥善处理这三方面,整体内存使用基本就能达标。
01 WebAssembly性能优化与内存挑战
WebAssembly并非旨在替代JavaScript(JS),而是通过扩展Web的能力提升其性能上限,从而更好地支持3D游戏、vr/ar 图像/视频编辑等类似的需要高性能计算要求的任务,其主要作用在于弥补JS在算力方面的不足。JS作为解释性语言,运行效率相对较低;而WASM则是编译型的字节码,性能更接近原生。

在一篇关于WASM与JS能耗对比的论文中,对比了在安卓平台下,不同的手机浏览器中WASM与JS的能耗表现,可以清楚地看到,JS的能耗远远大于WASM,最大能耗差异接近三倍。这意味着将WebAssembly 用于 Web应用 能 显著降低 对 移动设备的能耗,最直接的影响就是降低发热。

尽管WASM的性能接近原生,但两者之间仍存在一定差距。下面这篇论文对多种WASM独立运行时的程序进行了表征性研究,并从内存、机器指令、缓存命中等方面与原生程序进行了性能对比。最终的结论就是在独立运行时下,wasm就会比原生程序降低1.5~9.5倍的性能。以上两篇论文发表于2022年,具有很高的参考价值。

WASM调用WebGL API时,同样也需要遵守浏览器的安全模型和策略。WebGL中每次调用API都会伴随着一定开销,这主要是由于安全验证所引入的。在重度游戏中,WebGL API调用极为频繁,这意味着在Web平台下,状态切换的代价会更高。因此,有必要尽可能减少SetPass调用以及与WebAPI的交互。

WASM虽然解决了JavaScript在高性能计算的问题,但也带来了内存挑战。在小游戏中,编译后的C++代码会再次通过emscripten编译成WASM。在运行时,WASM代码会被再次编译并实例化,而编译+实例化的过程将会产生近10倍 wasm文件大小的内存占用。

例如,在诛仙第一个Chrome版本中,WASM文件大小为90M,这意味着在运行时产生了900M的内存。鉴于iOS小游戏内存限制为1.4GB,WASM占据了900MB,仅剩500MB可用空间,这对于MMO游戏而言是远远不够的。这部分内存的实际最终大小与平台、内核版本也有关系。我们在不同的手机及不同浏览器上进行过详细测试,结果显示,尽管内存大小存在一定浮动,但最终结论都接近于10倍。因此,对WASM进行缩减是必要的。

WASM是代码编译的结果,因此,缩减WASM的本质就是缩减代码的使用。Unity项目的代码主要由引擎代码、package、第三方库,以及游戏逻辑代码组成。可以通过Player settings对引擎代码和托管代码进行剔除,但这种剔除并不彻底,部分代码可能被引擎误判为已使用,或因错误操作产生引用,此时便需要进行手动剥离。其中,最常见的就是package和第三方库,特别是对于仅在editor下使用的代码库,要正确设置其程序集平台,保证其只在editor环境下使用。
除此之外,还有一些需要注意的方面。例如命名空间,小游戏中无法使用多线程,尽管使用多线程的代码编译无误且运行结果正确,但最终还会以单线程方式执行,这会导致性能差异。因此,需要剔除线程类的命名空间。
对于Job、Task等与线程相关的,由于无法发挥其多线程优势,也应该直接代码中剔除,并相应的将功能改为单线程实现,同时基于单线程优化代码算法。
另外,关于共享库的使用,例如json,在微信和抖音小游戏SDK当中都包含一份json,而一些第三方库或package也可能包含或引用一份json。对于此类问题,需要进行手动修改,确保项目存在一份json。
关于代码设计模式,优秀的设计模式固然能提高项目的可扩展性和可维护性,但是过度设计则会影响开发效率,尤其在小游戏环境中,过度的设计模式会使WASM变得更加臃肿。
WASM作为相对低级的编译目标,不支持泛型或模板等高级语言特性,生成的 wasm 代码是针对具体类型的具体实现。虽然在编译时,可以设置编译参数,进行编译优化,但对于过度复杂的设计模式,编译优化也无能为力。

举例来说,将属性写为访问器形式,编译后会额外产生2个函数。此外,foreach循环还会额外产生包含try-catch的语句,这些都会增大WASM的体积。
除编译问题,代码方面还有许多值得注意的地方。比如,对于string,运行中产生的并且频繁使用的string,最好使用intern把它强制放到常量池。能使用常量就使用常量,比如 vector.one,没必要再new vector(0,0,0)。类似的问题还有很多。因此,需开发人员更加了解IL2CPP,和WASM的机制,以便编写出更高质量的代码。

再说回到编译的问题,编译时可以导出一张符号表,如右上这张图 symbols.json 就是导出的明文符号表,左下就是该符号表的内容。利用这张符号表就可以对其文件进行解析,从而统计代码中每个类的占比。图右下,显示了对符号表处理的结果,例如 uilabel约占整个WASM的0.1%。开发团队会根据解析结果,从占比最高的类入手,逐步进行分析和优化,进而实现代码的剥离。图右下的是我们最开始生成的wasm分析文本。

目前,此功能在团结下已经得到了非常大的改进,能够可视化查看和对比两版本的差别,极大地提高了研发效率。

经过上述处理,WASM文件已从最初的90MB精简至目前的51MB,相当于节省了400MB的内存空间。
从图右侧可以看出,前述的每一步WASM精简方法,都对WASM内存产生了显著的影响,然而,目前仍有500兆的WASM编译内存,这仍然是一个相当大的数值。

即使通过代码剔除,在游戏的实际运行中,仍会存在一部分使用不到的函数。事实上,每个小游戏平台目前都提供了代码分包的能力,可以将运行时使用的函数收集到主包,未收集到的函数划分到子包。主包中所包含的函数,才是整个游戏生命周期所使用的函数。通常情况下,大部分游戏的主包代码占比不会超过50%,这意味着在最差的情况下,可以通过代码分包将WASM的编译内存再次减半。
然而,首次进行代码分包是一个相对耗时的过程,需要进行充分的函数收集,以避免因收集不全导致函数被划分到子包。频繁地远程拉取子包函数,会使游戏运行变得异常卡顿。以上便是我们针对WASM文件的所有优化方法。
02 小游戏中的Unity堆内存
小游戏中的堆内存结构与APP基本一致,两者均通过贝母GC进行管理,但在细节上存在差异。

在web平台,UnityHeap被实现为一个连续的线性内存空间数组,这部分内存是通过浏览器分配的,并且在生命周期内不会返还给浏览器。

在初始化阶段,需要为UnityHeap设定并设置一个大小,即预留内存。当内存不足的时候,系统会通过CopyArray的方式进行扩容,此过程会产生一个内存峰值,极有可能导致内存崩溃。例如,若预留内存设置为600兆,由于内存对齐,实际可能匹配到608兆,当内存不足进行扩容时,该帧的内存峰值可能达到1.4GB,此时极易发生崩溃。多数中重度游戏崩溃的原因,都是未能设置合理的预留内存,从而在内存扩容时发生崩溃。

通常对于重度游戏,推荐的预留内存值为768兆。然而,并非必须严格遵循此值,只要确保内存峰值不超过预留内存即可,即使略大于768MB也无妨。同理,如若游戏内存峰值肯定达不到768兆,也可设置得更小,将内存让给其他空间,比如js。因此,设置预留内存的目的是在合理的范围内使用内存,避免触发内存扩容和内存浪费。

托管内存方面,与APP不同,托管堆(Managed Heap)来自于unity堆,释放后也只会返回给unity堆,而不会返回给系统。尤其在Web平台下,托管堆具有只增不降的特性,这是一个显著的差异。

托管堆不只一块,会根据实际的内存使用,在unity堆中开辟多块,那么就会产生托管堆的碎片。尽管Unity没有提供相关的设置或者相关的编译参数,来提前预留托管内存,微小抖小平台也没有提供相关的接口进行设置,但可以利用托管堆只增不降的机制,提前开辟一大块托管堆内存进行复用,以减小内存碎片,提高内存的整体使用率。通过对比图示可以看出,上图未进行托管内存预留时,内存分布较为分散;而下图进行预留后,内存碎片明显减少,整体内存消耗也随之降低。

在内存管理方面,GC(垃圾回收)在移动平台和Web平台也存在显著差异。移动平台上,GC在触发后会立即执行,而在Web平台,GC仅在两个特定时机触发:每帧结束时会执行少量GC,以及切换场景时会执行一次完整的GC。因此,在Web平台的单场景尤其是单帧内,对内存的使用要注意以下几个方面:

一是设置合理的预留内存:避免因为预留内存不足而造成Copyarray。
二是避免内存碎片:特别针对托管内存,可以提前申请合理的使用空间并善用对象池来有效预防。
三是避免帧内内存峰值: 在移植过程中,曾出现过单帧内加载多张配置文件导致托管内存暴增的情况。对于native内存的暴增,最常见的原因是对AssetBundle的加载。避免单帧内存峰值的最佳方法是拆分数据,分帧加载。
尤其值得注意的是,强烈推荐使用小游戏平台提供的AssetBundle接口,例如微信的WXAsssetBundle和抖音的TTAssetBundle。尽管早期项目曾尝试不依赖小游戏平台接口,但效果不佳。实践证明,WXAsssetBundle或TTAssetBundle能真正利用文件系统,从而显著减少内存占用。
四是,避免不当使用像代理、匿名lambda、闭包等,这些不规范的使用方式会频繁产生堆内存,进而造成内存碎片,降低堆的利用率。
03 基于Unity的优化策略
许多常用的unity优化方法在小游戏和手游上同样适用,对于优化来说,可以把小游戏视为对性能要求更为严苛的手游,以下是一些手游和小游戏开发中被验证实用的优化方法。

首先,针对Unity资源件,可根据项目的实际需求进行进一步精简。比如 anim,Unity下,anim 可以针对不同文件,设置不同的误差,采用不同的压缩率。但在相同的骨骼点下,它们所需的精度有所差异;这意味着相同的误差对于不同的骨骼点会产生不同的影响。

对于站立动作,其通常是新玩家进入游戏创角场景后看到的第一个动作。较大的压缩误差会使脚步与地面产生较大的位移。通过对比error 1.0和0.5的设置,可以观察到模型脚步与地面之间存在显著差异。尽管有些项目为了给新玩家提供更好的体验,会在创角场景采用独立的资源以保证更优质的效果,但这会额外增加包体大小,并可能导致频繁的下载。
在《诛仙》项目中,我们采用了程序化方法对动画文件进行组合性压缩,针对不同动作、不同肢体部位采用不同的压缩误差,以此实现效果与性能的平衡。可以看到经过组合压缩的站立动作,腿部与地面的相对位移几乎很小。

具体来说,对于于站立动作,在腿部会采用更低的误差以减少滑步现象,而其他部位则会采用高误差低精度的方式进行处理,从而平衡整个动作文件的大小并保障局部动作效果。经过这种处理,动作文件在腿部组合压缩后会拥有更多的采样点,确保了腿部的精度。

同时,在不影响手臂效果的前提下,组合压缩会尽可能减少手臂的采样点,从而平衡了整体文件的内存占用。

通过下图可以看出,组合压缩会更加拟合原始动作文件,而Error 1.0和Error 0.5的文件则与原始动作文件存在明显的曲线偏差。

这种组合压缩方法不仅能达到预期的效果,而且压缩后的文件大小也非常理想,甚至在某些情况下会比Error 1.0的文件更小。

除了AssetBundle,全局光照(GI)数据也是重度游戏,尤其是MMO类游戏消耗内存的重要部分。在大场景中,目前通常通过光照贴图(Lightmap)和光照探针(Light Probe)的方式实现效果。光照探针作为一种实现GI的方式,相比Lightmap,它更容易规避单帧内申请过多内存,也更便于实现离散的分帧加载,并且在制作TOD时更为便捷,显著增加了灵活性。

然而,光照探针的灵活性也伴随着内存的问题。一个Lightmap中的采样点可视为一个RGB值(即3个float),而Unity中的光照探针使用的是三阶球谐函数(3rd order Spherical Harmonics),这需要9个系数,共计27个float。对于GI而言,采样点越多,效果自然越好。但是,过多的光照探针相比Lightmap内存势必也会翻倍。
鉴于球谐函数用作GI通常是低频信号,其在空间中的变化是平滑且连续的,因此相邻球谐函数的系数也极为相似。基于这一特性,可以对场景中的探针进行基于特征空间的降维压缩,从而有效优化内存占用。
在二维空间中,可以通过找到一个特征轴来表达平面内点的特征。同理,在三维空间中,也可以通过多个特征轴来表达三维空间的特征。因此,可以提取所有球谐函数的特征数据,并将其映射到特征空间,再根据前n个特征来重构原始数据,从而实现高保真度的压缩与还原。

从上图右侧可以看出,在不同特征数量下所表达的平面结果:特征数越多,越接近原始效果。在三维空间中,对于光照探针、环境光遮蔽(AO)等具有方向性的数据,均可通过这种方法进行降维压缩。

上图左侧的图像展示了三阶球谐函数的原始效果。中间的四幅图是经过降维并还原后的结果,其中特征是叠加的。当特征数量为一时,它表达的是最主要的特征。随着特征数的增加,细节也随之增多。在中间的四张图中也可以观察到,随着特征数量的增加,绿色部分变得更加明显。当特征数达到13时,整体效果与原始球谐采样几乎一致。

当然,也可以直接使用二阶球谐函数,但它会产生明显的差异。从上图左侧的两张图可以看出,尽管二阶球谐函数的色调与三阶一致,但在明度上存在较大差异,并且这种差异会随着建筑结构、光源等空间复杂度的增加而愈发明显。但是当特征=13的时候, 与三阶球谐相比,无论从色调还是明度,几乎感受不出差距。

利用特征空间进行降维的目的不仅是为了实现高还原度,更在于其在内存方面具备显著优势。
通过左上的两个公式可以更直观地看出,在大量探针的应用场景下,基于特征空间的降维显著降低了球谐阶数对内存的影响。具体而言,三阶球谐函数每增加一个探针将稳定增加108字节。而基于特征空间的压缩方法,每次增加的字节数是特征数乘以4。当特征数等于13时,每个探针仅增加52字节。并且此时几乎可以还原原始探针的全部效果。
鉴于球谐函数主要用于表达GI的低频信号,在实际应用中可以适度缩小特征数。这样做既能有效减少内存占用,又能确保GI效果的质量。

以上阐述了针对数据压缩的方法。如前所述,小游戏对Draw Call和SetPass更为敏感。在保证效果的前提下,LOD是降低Draw Call和面数的最佳方法。
LOD的优势在于可以通过全局划分显著减少Draw Call和面数。但值得注意的是,单场景、单帧内对内存的申请也会随之增大。

我们重写了LODGroup组件,在切换不同物体的同时,能够使其以流式的方法逐步加载卸载对应的资源,这意味着仅加载当前可见的资源,而非一次性加载所有资源。这种做法能够平衡LOD带来的内存增加,有效管理和利用模型资源,从而达到平衡内存、Draw Call和面数的目的。

值得注意的是,由于web环境下不支持多线程,所以Unity自带的的流式纹理也是无法正常工作。所有资源的流式加载都需要手动重新实现。

除了实体,我们也对粒子做LOD。如上图,随着LOD等级变化,部分粒子发射器会被直接剔除,而另一些粒子并不会被剔除,但其粒子的产生速率与生命周期会明显的缩短。这种优化方式在团战等特效密集的的场景中效果明显,能在保证整体视觉效果的同时,进一步降低粒子消耗,优化场景性能。

对于草地特效这类同质物体群落,使用LODGroup无法达到理想效果。LODGroup主要表达的是单个物体随距离远近的变化,而植被群落则表达为一个面。因此,我们通过CullingGroup的方式,基于距离实现不同密度的实例化绘制。使用CullingGroup的主要目的是弥补实例化合批无法被剔除的问题。后面我也会介绍一种在团结引擎下能够进行剔除的实例化合批的方法。

对于大型场景,还可以根据地块和距离调整特征数,让不同的地块使用不同的特征数,可以进一步降低探针内存。比如近处使用13特征的GI,尽可能还原效果,而中距离、远距离逐步降低特征数,减少内存消耗。
04 团结引擎支持下的优化与实践
团结引擎对小游戏的支持是开发团队当前正在利用的重要引擎功能之一。借助团结引擎,我们能够进一步降低内存消耗。在将项目从Unity切换至团结引擎后,开发团队在所有配置(包括 projectsetting,playersetting等引擎层面的参数设置)均保持相同的前提下进行了内存对比。结果显示,直接使用团结引擎能够为项目额外节省约60兆的内存,这一优化效果非常可观。

在团结引擎中,托管代码精简新增了“extreme”模式。相较于“high”模式,“extreme”模式在代码剔除方面更为激进。对于MonoBehaviou和rScriptableObject,该模式仅保留项目中实际使用的类及函数。在我们的项目中启用此选项,能够将最终的WASM文件大小进一步缩小约10兆字节,这相应地意味着可以节省约100兆字节的内存。

Unity中Skinned Mesh Renderer是一个性能消耗较高的组件,但在MMO类游戏中又必不可少。小游戏平台CPU性能大约只有APP的三分之一,因此需要尽可能减轻CPU的压力。为应对此挑战,我们将场景中可进行合批的角色通过“Instancing + VAT”的方式进行绘制,取得了较为理想的效果。

在骁龙660设备上,开发团队分别使用GPU和CPU两种方法为140个角色进行随机动画播放测试。结果显示,完全依赖CPU播放的帧率仅能达到21帧,而采用GPU播放动画则能稳定保持在30帧。

在2023年中旬开始小游戏移植时,缺少团结引擎和gpu skinning,因此VAT(vertex animation texture)是一个相对性价比很高的解决方案。目前,团结引擎已经能够通过GPU skinning在GPU端实现蒙皮计算,同样可以减轻CPU压力,并达到理想的性能标准。因此,我们已经用GPU skinning替代了原有的VAT方案,也节省了额外的工作量。
从上图中可以看出,在108个角色同屏的情况下,通过GPU skinning能够稳定达到30帧。而在相同场景下,使用CPU skinning的帧率只能维持在10帧以下。

WASM调用WebGL API需遵循浏览器的安全模型和策略,每次调用API都会产生一定的开销。这部分对开发者来说是黑盒的,我们唯一的办法就是降低dc和setpass,也就是降低游戏的复杂度。

在团结引擎下,可以对Shader进行优化,包括直接通过引擎层面减少对WebGL API的调用。这种方法对于某些低系统设备效果非常显著。我们在iOS 16.4系统上进行了不限帧测试,包括野外团战和副本。开启上图所示选项后,帧率能够提升大约8到10帧。
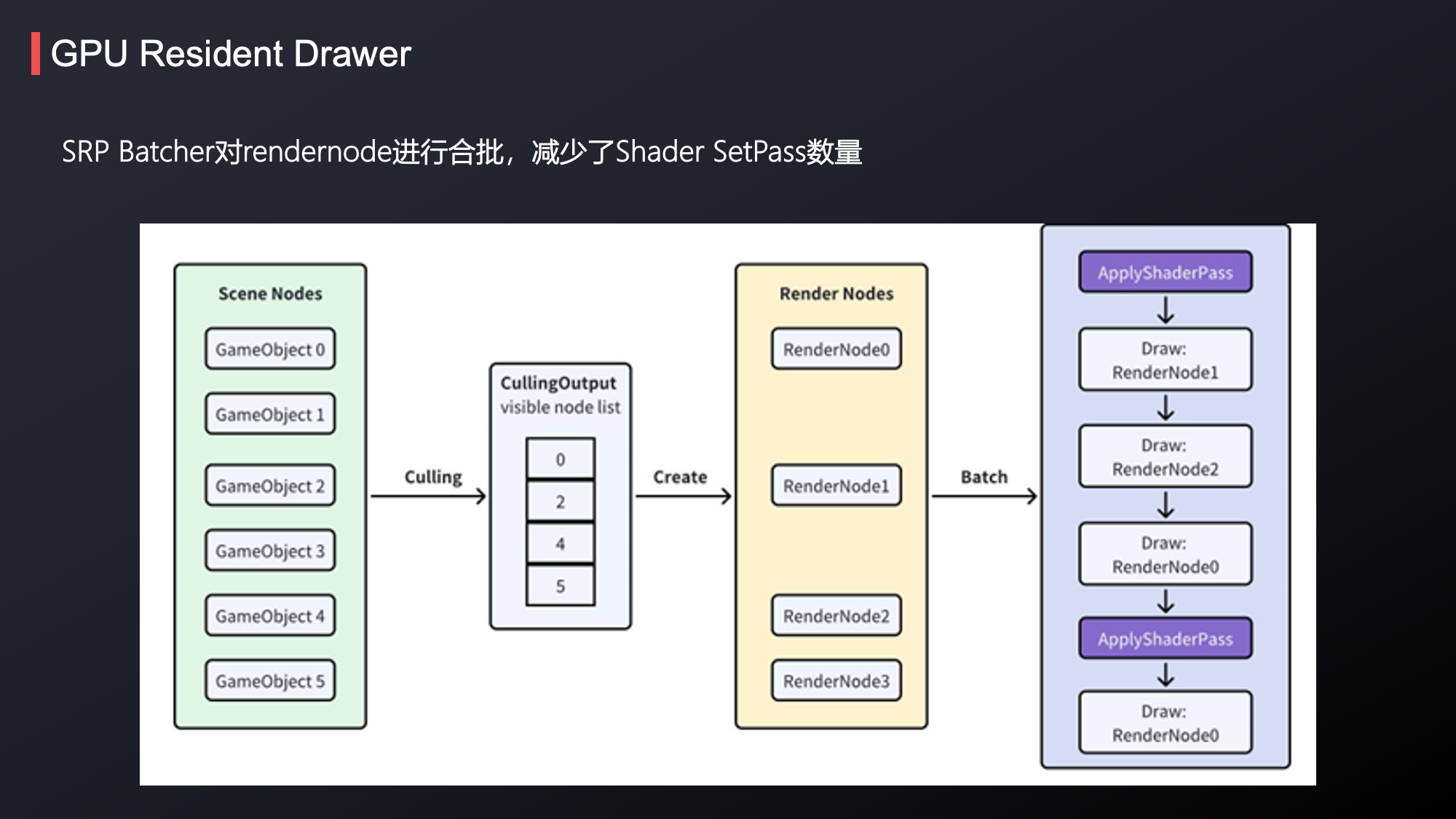
在合批方面,SRP Batcher能够通过排序,将使用相同Shader的物体放到一起去绘制,从而使每个批次仅调用一次ApplyShaderPass,减少了重复设置Shader的时间消耗。
目前,项目主要采用的合批方式仍是SRP Batcher。运行时相比StaticBatch会有一定的消耗,因为引擎每帧会根据可见的renderers生成render nodes。然而经过大量测试发现,在我们项目中,SRP Batcher和 static batch 对于帧率的影响是相近的。鉴于静态合批会额外增加内存或包体大小,因此我们仍将SRP Batcher作为主要的合批方式。

后续团结引擎将推出一种更高效的合批方式,即GPU Resident Drawer。目前团队正配合团结的同学进行性能测试。理论上GPU Resident Drawer的执行效率将高于SRP Batcher,主要通过BRG(Batch Renderer Group)进一步提高渲染效率,并且根据小游戏的特性,在单线程上做了特定的优化。只要场景中的物体是静态的,它的buffer就不需要更新,会长期驻留在GPU上。因此,与SRP Batcher相比,GPU Resident Drawer在运行时也能减少一定的计算消耗。

GPUResident Drawer的主要目的是对于复杂场景的优化,尤其适用于场景中存在大量可以实例化合批的分散物体的情况。如果直接使用实例化进行合批,由于缺乏剔除,反而可能导致负优化。同样,若在CPU端自己实现剔除后再调用graphic Drawinstance进行绘制,也会加重CPU端的计算压力,同样可能造成负优化。
而GPU Resident Drawer的一个重要特性就是解决了剔除问题。上方的表格是主城的测试结果,在Drawcall、Setpass以及功耗方面都有了非常明显的降低。
以上就是我今天的分享 谢谢大家。

分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐



 21
21 0
0- 0



 已为社区贡献747条内容
已为社区贡献747条内容

所有评论(0)