
Unite Shanghai 2025 | 移动平台的虚拟几何体
团结引擎虚拟几何体现在已经登陆移动端,为移动端的次时代画质飞跃奠定坚实的技术基础。在Unite Shanghai 2025团结引擎专场中,Unity中国软件工程师、团结引擎Graphics团队核心开发成员李晨旭、吴笛分享了虚拟几何体在移动平台的落地实践,展示团结引擎虚拟几何体技术在移动端的渲染效果。本文为演讲全文实录。请持续关注,一起学习Unite 分享的最新干货。

李晨旭:很荣幸今天能在这里代表Unity中国图形组向大家介绍团结引擎的新功能——移动平台的虚拟几何体。虚拟几何体Virtual Geometry,一般简称VG。这是随着团结1.0版本就已经发布了的一个比较重磅的功能,至今也已经发布了有一年多的时间。在VG发布的这一年多时间里边,VG都是只支持HDRP管线,并且只能在Windows和Linux这两种系统中使用。但是从团结引擎1.7.3版本开始,团结引擎正式支持VG在移动设备上使用。包括支持了URP,以及在安卓、iOS上的使用。
虚拟几何体简介
讲述移动端的虚拟几何体之前,先带大家一起回顾一下虚拟几何体是什么?

用以下这么几句话去描述虚拟几何体:首先,它是一个GPU驱动的渲染管线,在传统渲染管线上很大一部分需要在CPU上完成的工作,都交给了并行度更高、效率更有优势的GPU去进行。其次,虚拟几何体有着自适应的Cluster LOD,有着相对于传统渲染管线更加精细粒度的剔除,能够降低Overdraw,并且对几何与材质进行了解耦,大幅度减少了Draw Call的数量。因为以上的优化,虚拟几何体拥有实时渲染上亿量级面片的能力。
那么什么是自适应的Cluster LOD呢?在VG中,Mesh会被重构为以Cluster为单位进行渲染,一个cluster就是一个三角面的集合,最多包含128个三角形。Mesh会被重新构建成多个细节层级的Cluster。可以在上方视频的左半部分看到,一个连续的相同颜色的色块就代表一个Cluster。随着相机的移动,一个相同位置所使用的Cluster一直在发生变化。这也就是自适应的Cluster LOD,VG会根据相机与物体的位置,自动的选择最合适的Cluster细节层级,这个选择到的cluster细节层级会尽量地去保证每一个需要渲染的三角面在屏幕中会占据一个固定的大小。因为这个原理,所以无论场景中能看到的物体原来的面数有多高,最终我们在一帧的绘制之中所真正绘制的三角形面数总是不会超过一个上限。

因为Mesh被重构为了粒度更小的Cluster,所以可以在GPU上以cluster为单位进行更加精细的剔除,这里既包括视锥体剔除,也包括遮挡剔除。这里有一个大致的示意图,背后三个雕像是三个高模,左右两个雕像有一部分被遮挡。在开启了VG之后,被遮挡部分的Cluster都被剔除掉了,而没有开启VG时,遮挡剔除只能以Renderer为单位,则绘制了更多的地方。
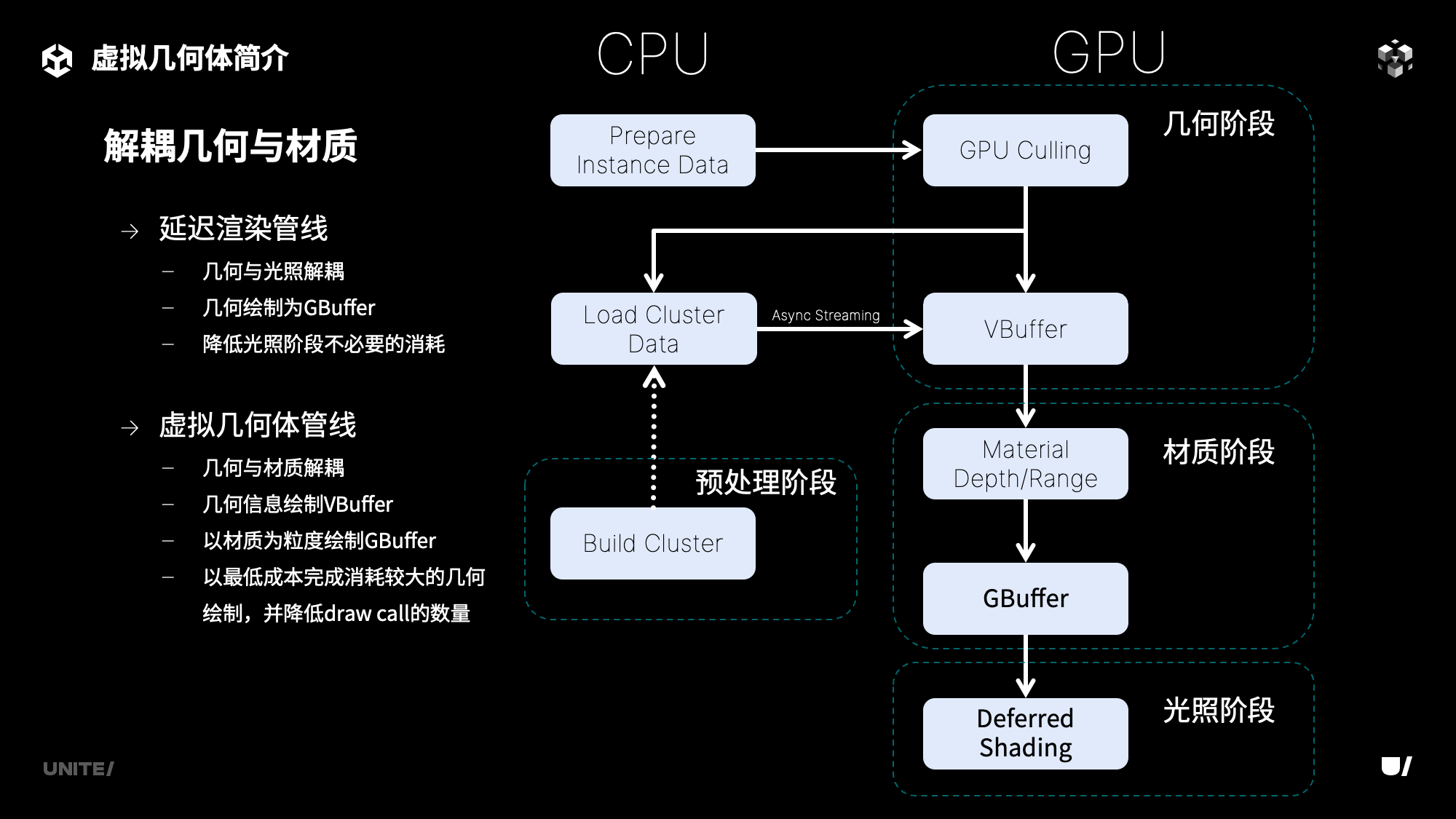
再说到几何与材质的解耦。在我们传统的延迟渲染管线里边,我们将几何与光照进行了解耦,也就是在使用Geometry进行绘制时,只绘制GBuffer,而不做光照的处理,将这两个阶段分开,以此降低在光照阶段本来不必要的消耗。而在虚拟几何体之中,再一次将几何与材质也进行了解耦,在使用Geometry信息进行绘制时只绘制Visibiliy Buffer,也就是VBuffer。这个过程不会涉及到材质相关的数据,所有通过了Culling的Cluster在最少1个Draw Call之内就能完成VBuffer的绘制。而后再以Material为粒度,去进行GBuffer的绘制。这样可以以最低的成本完成本来消耗会比较大的几何绘制,并且很大程度上降低了DrawCall的数量。右边的示意图大致展示了虚拟几何体管线的过程,可以看到几何、材质、光照这三个阶段完全解耦。
移动端的虚拟几何体
因为有以上这些优化,所以VG可以在基本不损失画质的情况下,以流畅的速度实时渲染上亿量级面片的场景。如果这样的技术可以运行在移动设备之上,对于移动设备上的渲染效果会有很强的提升。
接下来,我想要给大家直接投屏展示一下当前VG在移动端的运行情况。
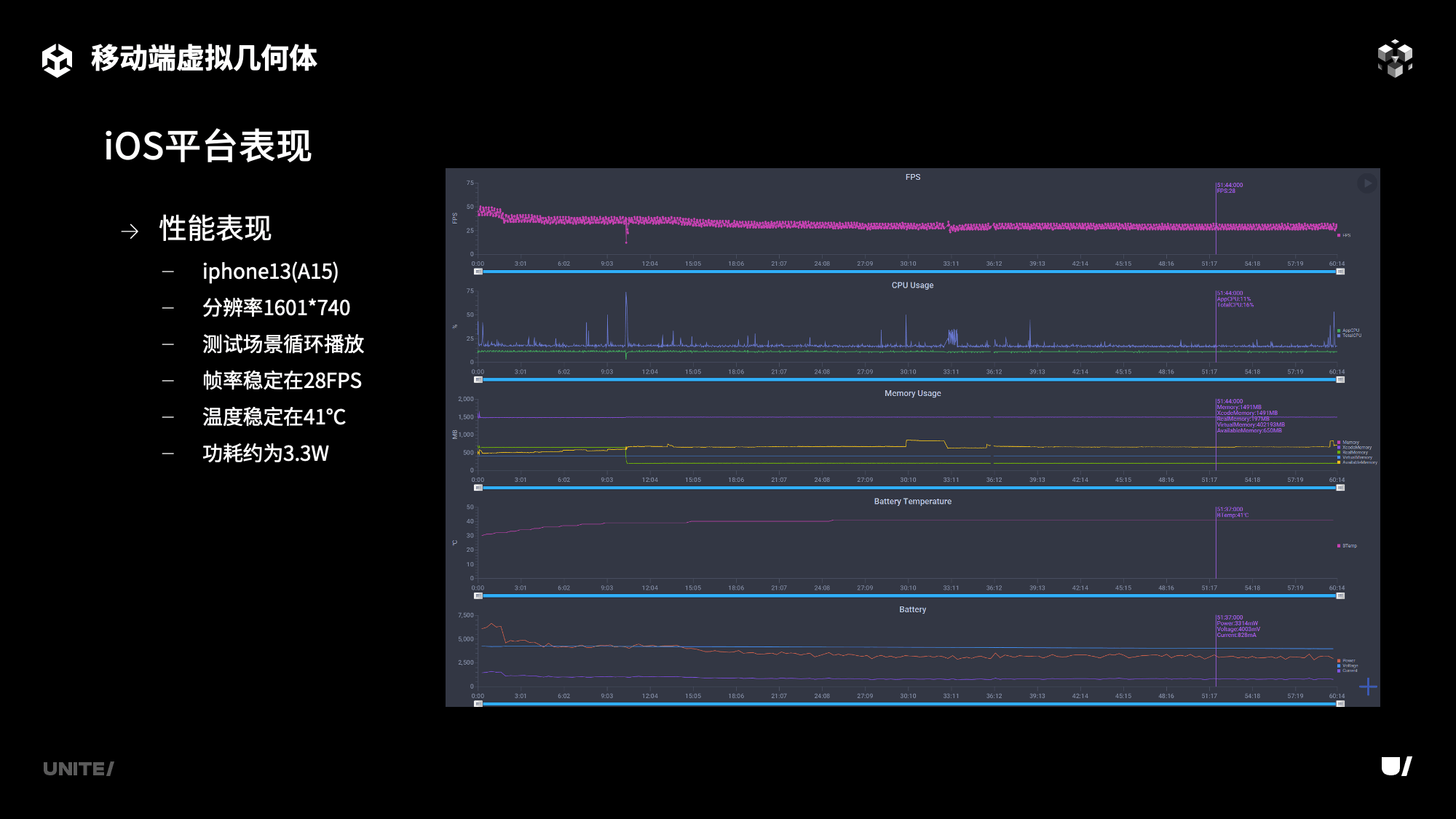
以上就是虚拟几何体在移动端的运行情况,可以看到对于这样比较高面数的场景,VG在移动端可以发挥非常大的优势。我们看一下在长时间使用的情况之下,移动端VG的表现。上图为在iphone13搭载了A15芯片下进行的性能测试。分辨率是1601*740,测试场景是视频demo中演示的场景,对着刚才看到的雕像阵列进行旋转观察,测试时间是一个小时。可以看到手机的温度随着时间会有上升,从最开始的30℃,在大约进行到30分钟的时候上升到41℃。随着温度上升,Soc发生降频,功耗从最开始的大概6W的功耗,到一两分钟会降低到不到5W的功耗,最后在半小时左右稳定在3W的功耗。而帧率也从最开始的稳定50帧左右逐步下降,最终是稳定在了28帧。可以看到在一个非常高消耗的场景,在iphone13这样的机型上,最终帧率也是可以稳定在30帧左右的。
像是这样的高模是很难在传统渲染管线中绘制出来的,那我们就对比一下在移动端开启和关闭VG时,渲染高模的表现。因为前面这个展示的场景如果不开VG的话,在手机上是完全运行不起来的,所以这里用一个更简单的场景来展示。在这个场景中放置了13个四百万面的雕像,在iphone13上运行。上边的这个视频是开启VG的状态,下边这个视频是关闭VG的状态。可以看到在开启VG时,可以稳定60帧渲染这个场景。在关闭VG的时候,帧率大约只有10帧左右。但是在画面效果上,两边基本上可以说是完全一致的,虽然VG这里有减面,没有影响到渲染的效果。
前面我所展示的都是在iOS上的效果。当然移动平台的虚拟几何体也支持了安卓端,这里通过视频展示一下VG在安卓上的运行情况。这里我们使用的是搭载了天玑9300的手机,分辨率设置为1920*864。就在刚才的这个演示场景中飞了一圈,没有锁30帧,平均帧率大约是44帧左右。这个视频看起来可能有些卡顿,这是录屏导致的问题。实际在运行的时候,他的表现还是比较流畅的。
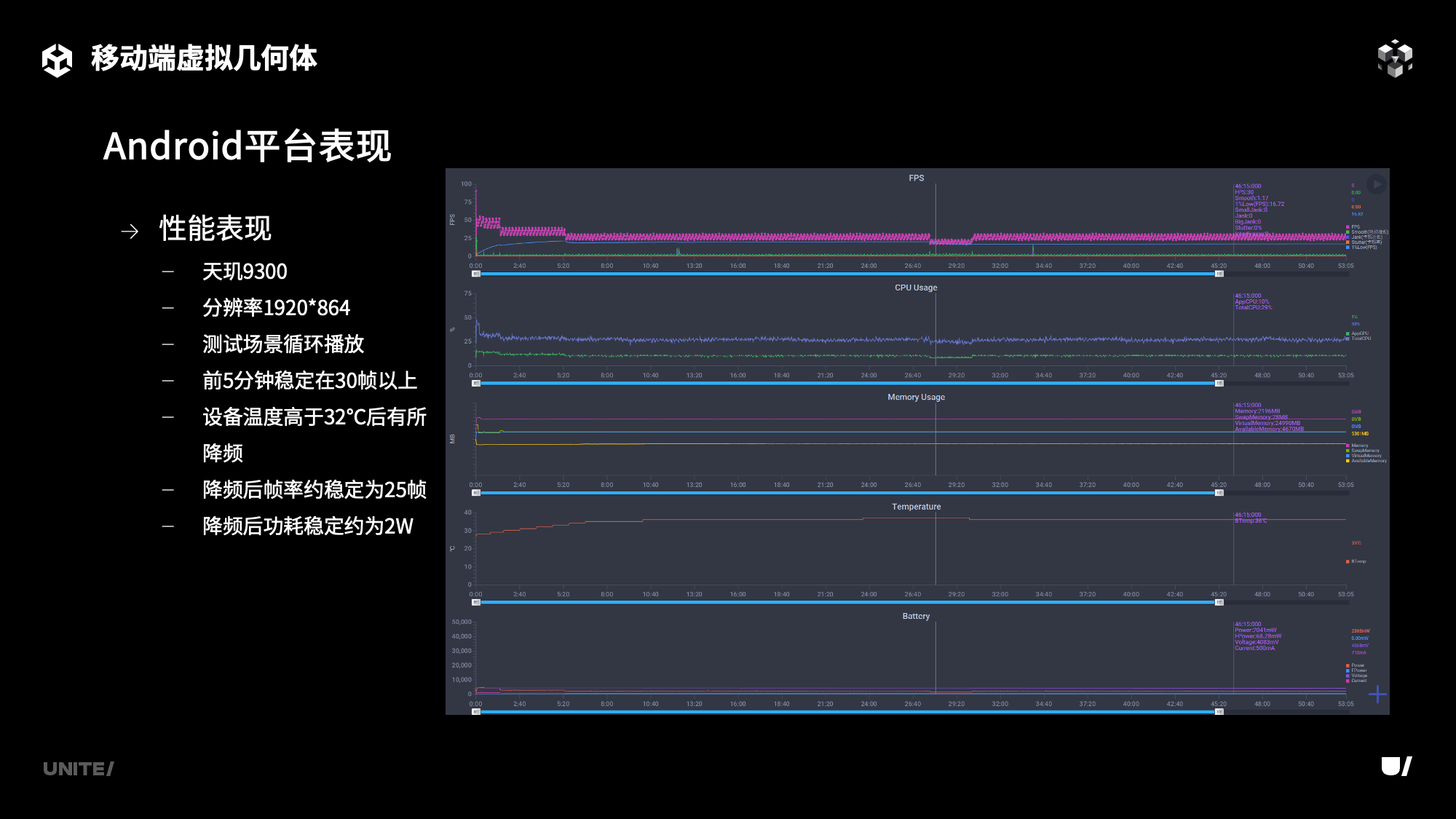
在安卓上长时间使用的表现与在iOS上类似。在天玑9300的设备上,分辨率设置为1920*864,还是之前的这个场景。前5分钟可以稳定在30帧以上。而后手机的温度上升到32℃以上之后,SOC会有一定程度的降频,最后帧率稳定在平均25帧左右。功耗大约是2W左右。
以上就是VG在移动端的表现,接下来请我的同事吴笛为大家继续讲述VG在移动端的使用方法以及技术细节。

吴笛:我首先讲解的是移动端虚拟几何体的使用方法。
移动端虚拟几何体使用方法

目前团结引擎仅在URP渲染管线中支持移动端的虚拟几何体功能,因此我们需要先创建一个URP工程项目,在项目设置下的Graphics栏中找到Virtual Geometry的开关,打开它,并等待项目重启完成。之后选择想要使用虚拟几何体功能的模型资产,在其Inspector中找到并开启Virtual Geometry开关,待虚拟几何体数据生成完成后,将模型资产放入场景中,并确保其Mesh Renderer的Virtual Geometry开关处于开启状态,即可让模型以虚拟几何体的方式进行渲染。在使用上,虚拟几何体功能做到了开箱即用。这里需要注意的是URP的项目默认使用的渲染管线是前向渲染管线,而目前虚拟几何体仅支持延迟渲染管线,因此我们需要开启延迟渲染管线功能,不然放入场景中的虚拟几何体模型无法被正确渲染。
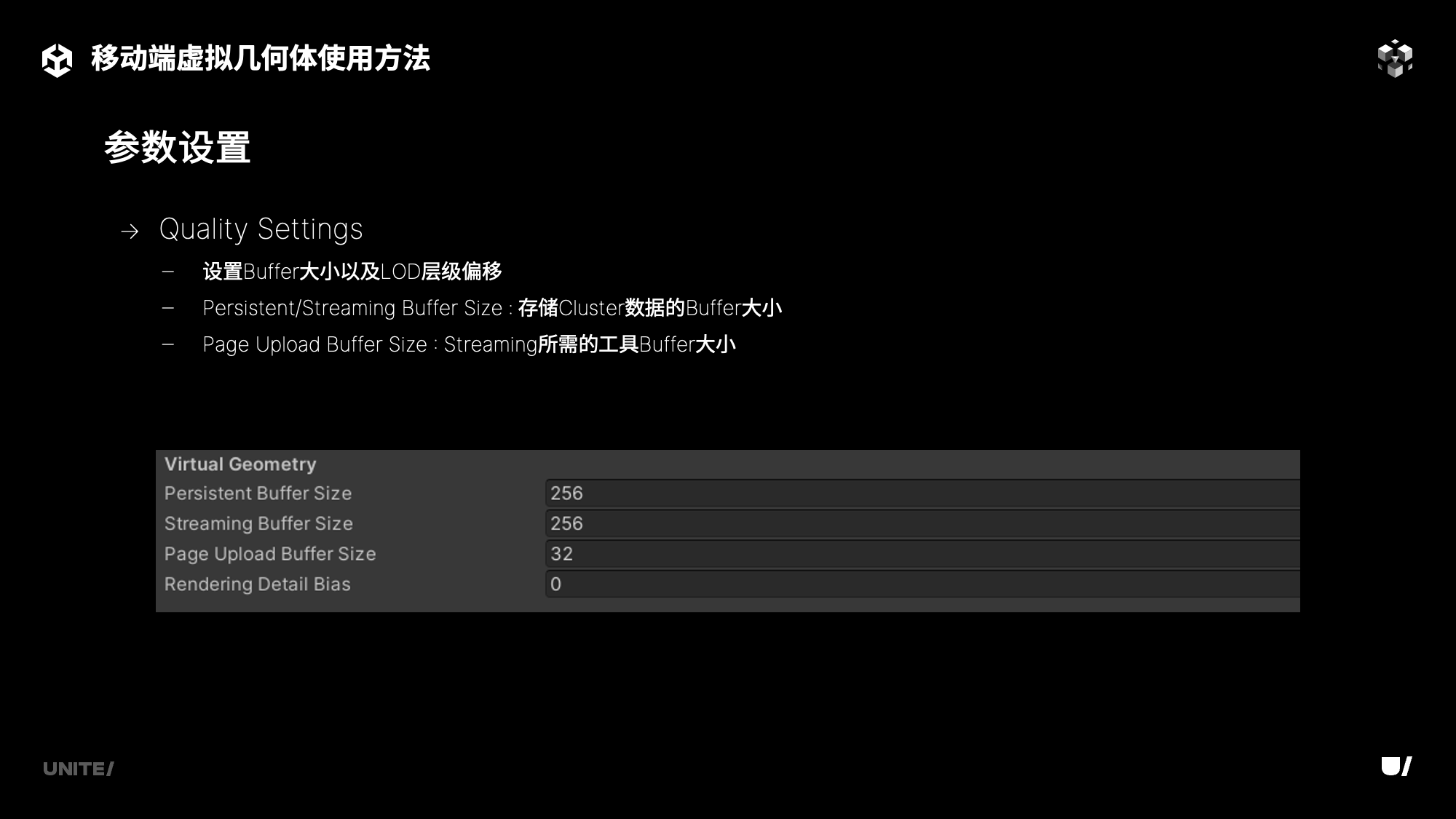
不同于桌面端硬件,移动端设备,特别是苹果设备对内存限制相对严格,为此团结引擎在项目设置的Quality栏中添加了虚拟几何体部分Buffer大小的参数设置,方便各位开发者根据目标帧率、目标设备和项目资产进行更改。其中Persistent Buffer决定了项目中Mesh的数量,如果Mesh的数量越多它所需要的Persistent Buffer的大小就越大,而Streaming Buffer则是与项目目标平台的渲染分辨率相关。如果渲染分辨率提升,相应的Streaming Buffer的大小也会需要提升。而Page Upload Buffer需要在LOD自适应过程中提供一个中转的Buffer来将Streaming所需要的配置数据由硬盘转至GPU显存中,如果需要在场景快速移动的过程中有更好的LOD自适应表现,也需要将这个Buffer大小变大。
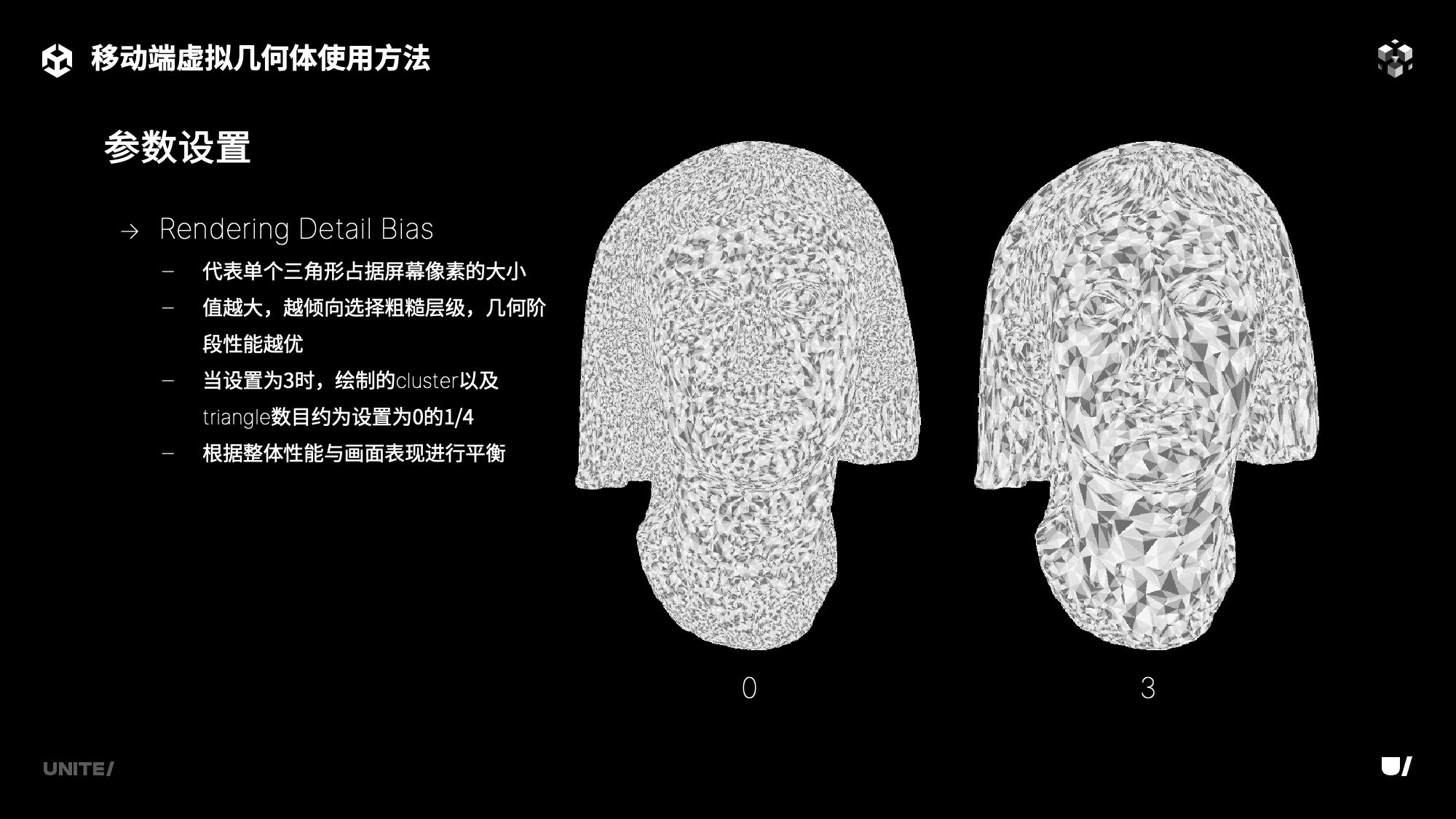
同时对于浮点算力较弱的移动端设备,团结引擎提供了Rendering Detail Bias选项。该选项决定了虚拟几何体自适应LOD变化过程中选择的单个三角形所占屏幕像素的大小,值越大,越倾向于选择粗糙层级的三角形,在相同距离下模型绘制的三角形数量减少,几何阶段有更优的性能表现。

比如LOD自适应过程中所选择的三角形通常所占的屏幕像素点是1个,而在添加了这个选项之后,我们可以自行控制LOD自适应过程中所选择的单个三角形在屏幕所占的像素数量。目前该选项的范围是0-3,当设置为0的时候,就以最精细的方式进行渲染,而选择为3的时候,单个模型在相同距离下渲染所绘制的三角形数量约为设置为0时的1/4,相应的,我们也能看到模型的细节有所减少,开发者需要在整体的画面表现和性能之间进行平衡。
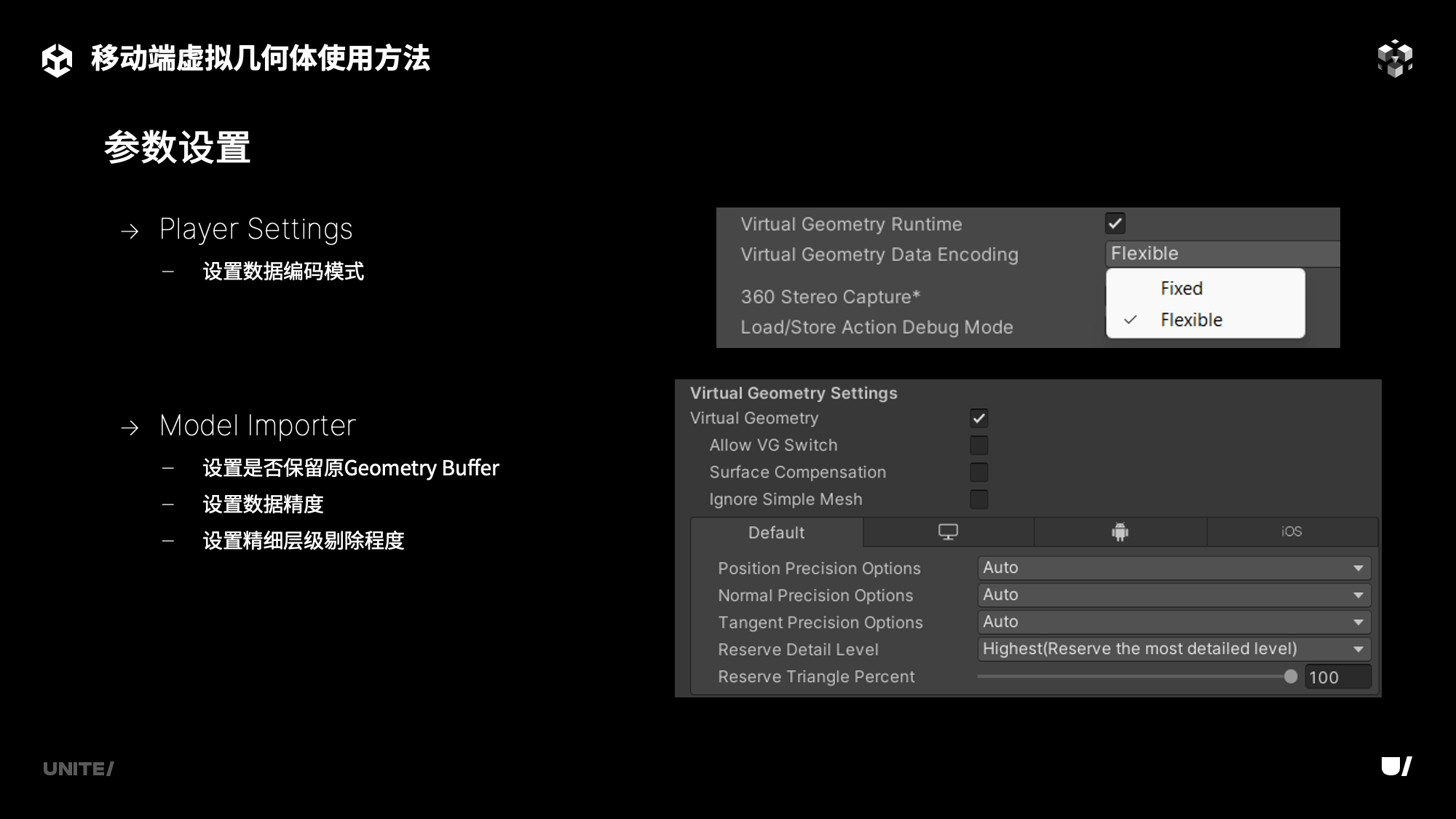
在适配移动端虚拟几何体的过程中,我们发现移动端设备较弱的浮点性能可能成为虚拟几何体数据解码阶段的性能瓶颈,因此团结引擎提供了Fixed编码格式,来减少解码的算力需求,编码格式的调整可以在项目设置的Player Settings中根据平台进行设置。

对于模型资产的设置,在原有的基础上,团结引擎添加了模型精细层级剔除的新选项。该选项决定了模型生成的虚拟几何体数据的精细层级保留情况,以此来减少模型在移动端出包时的包体大小,以及运行时的显存占用。

当然精细层级被剔除,意味着自适应LOD切换过程中,无法在更靠近的情况下,选择到更精细的Cluster数据,开发者们需要根据模型在场景中的可视程度决定该参数选项。关于移动端虚拟几何体的使用,团结引擎已同步更新了官网的Manual文档,欢迎各位开发者前去查看。
技术实践
接下来就移动端的虚拟几何体技术适配过程中所遇到的问题,挑出两个为大家阐述我们的解决方案。
URP Reflection Probe
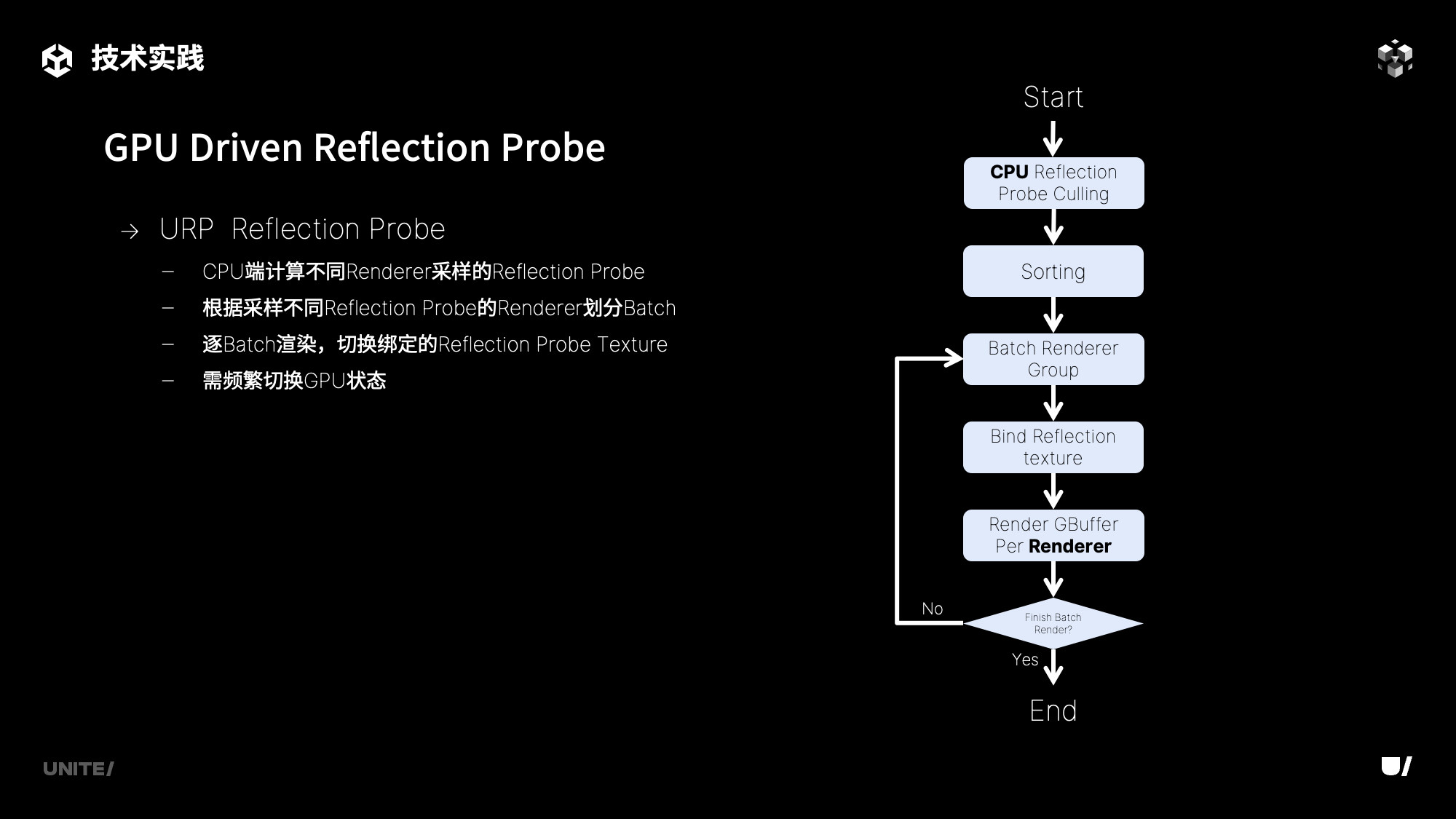
首先是URP的Reflection Probe,传统的渲染管线中Reflection Probe渲染流程如度所示,每一帧都需要由CPU计算场景中Renderer所需采样的Texture,根据Texture划分Renderer到不同的Batch中,再在GPU上逐Batch进行渲染,而每个Batch都需要重新绑定Texture,这势必会导致GPU状态的频繁切换。

而在GPUDriven渲染管线中,虚拟几何体以逐Material的方式绘制GBuffer,不同的渲染方式决定了我们需要采取其他方案处理Texture和Renderer的对应关系,为了能够获取Renderer的信息,我们创建了一个Buffer将其存储,在GBuffer绘制过程中,根据VBuffer的像素结果,从我们创建的Buffer中取出Renderer数据进行Reflection Probe的采样。而使用相同材质的不同Renderer,可能会采样不同的Reflection Probe的Texture,我们将所有的Texture紧密排列在一张Atlas中进行采样。
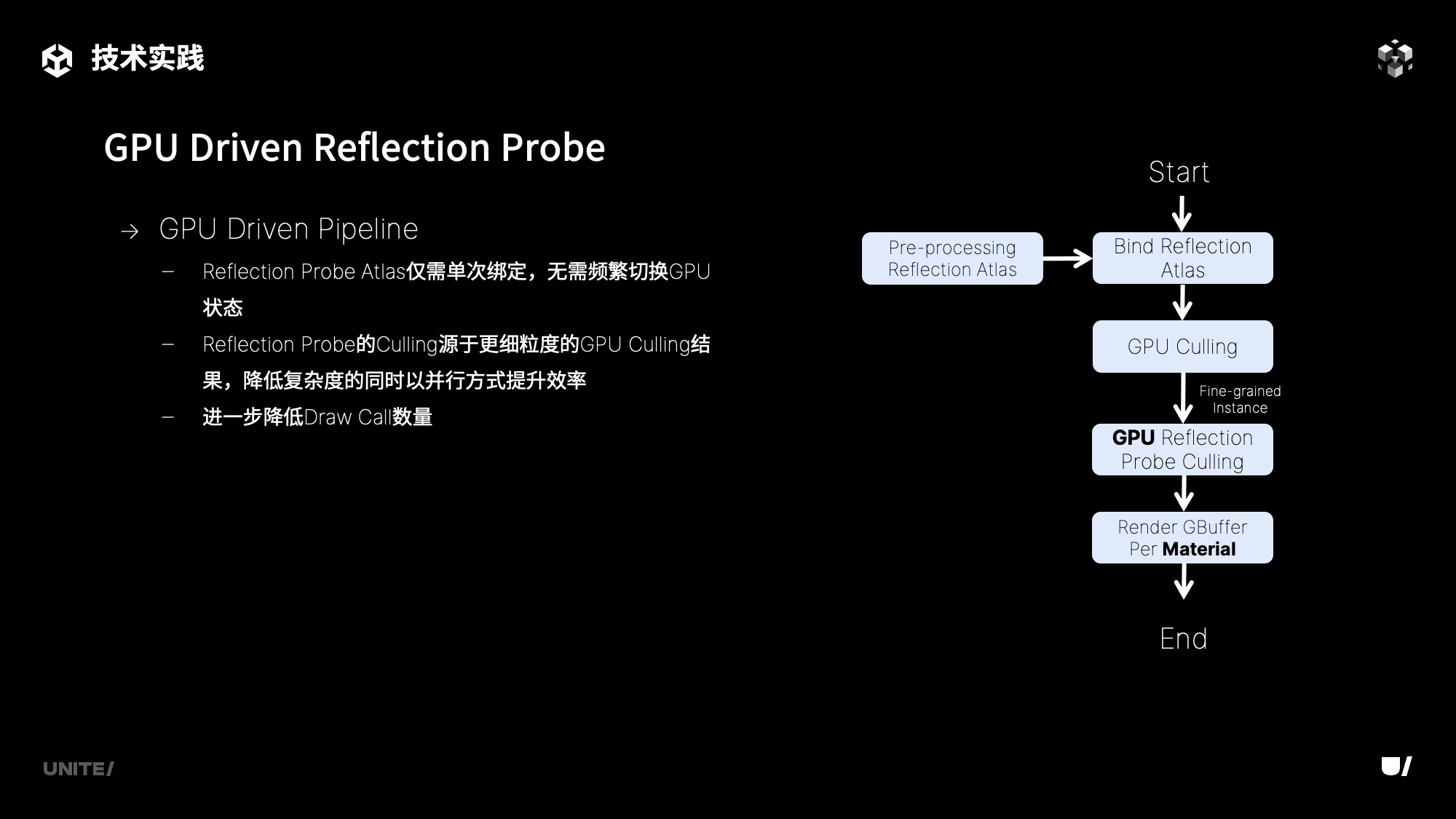
单张Atlas可以减少Texture的绑定次数,此外Reflection Probe的剔除也被替换为了更高粒度的GPU剔除方案,提升了剔除效率,降低了Over Draw,并减少了Draw Call的数量。

我们创建了一个简单场景进行性能测试,场景中摆放了64个使用相同材质的Renderer以及64个与之对应的Reflection Probe。
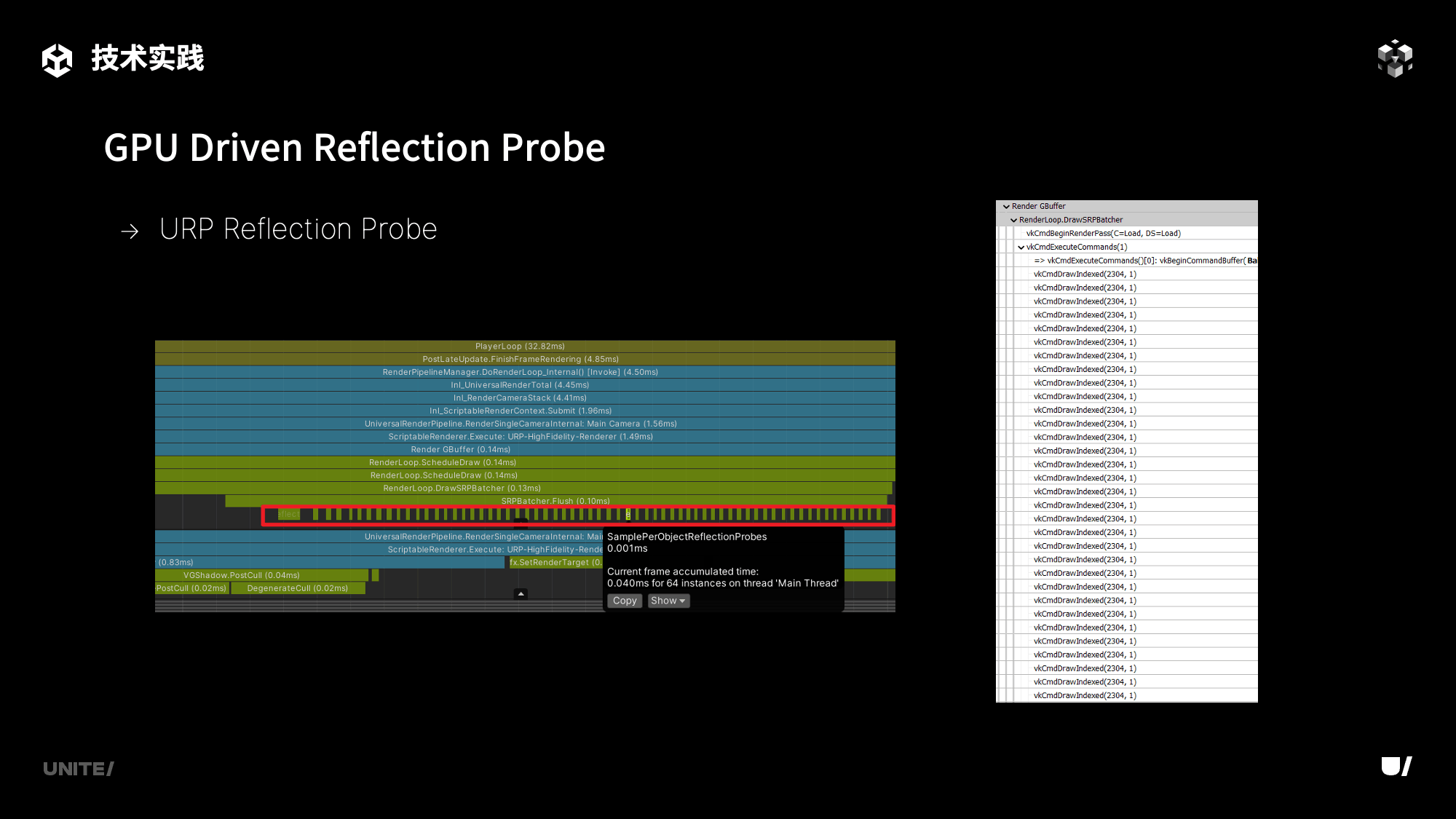
在原有渲染管线下,每一个都需要单独进行绘制,在这种相对极端的场景下,就需要64个Draw Call,将64个Reflection Probe分别绘制在64个在Renderer上。

而在GPU Driven渲染管线中,由于都是使用相同的材质,只需单个Draw Call,就可以完成单一材质的全部Reflection Probe的绘制。
虚拟几何体实时阴影方案

其次是虚拟几何体实时阴影方案的实现,目前URP中仍然使用的是级联阴影贴图,即CSM的方案, 传统的CSM方案没有绘制大规模精细模型的能力,因此我们对其进行了GPUDriven渲染管线的适配,主要完成了四项工作:一是使用GPU替代CPU完成剔除;二是将几何和材质解耦,减少Draw Call数量;三是利用Multi View技术,一次Draw Call完成所有Cascade的绘制,进一步减少Draw Call数量;四是根据CSM的渲染特点,调整自适应LOD算法,减少Artifacts,并降低渲染压力。一和二让CSM具有了流畅绘制高精模型的能力,三则是更进一步优化多Cascade下的CSM性能表现。
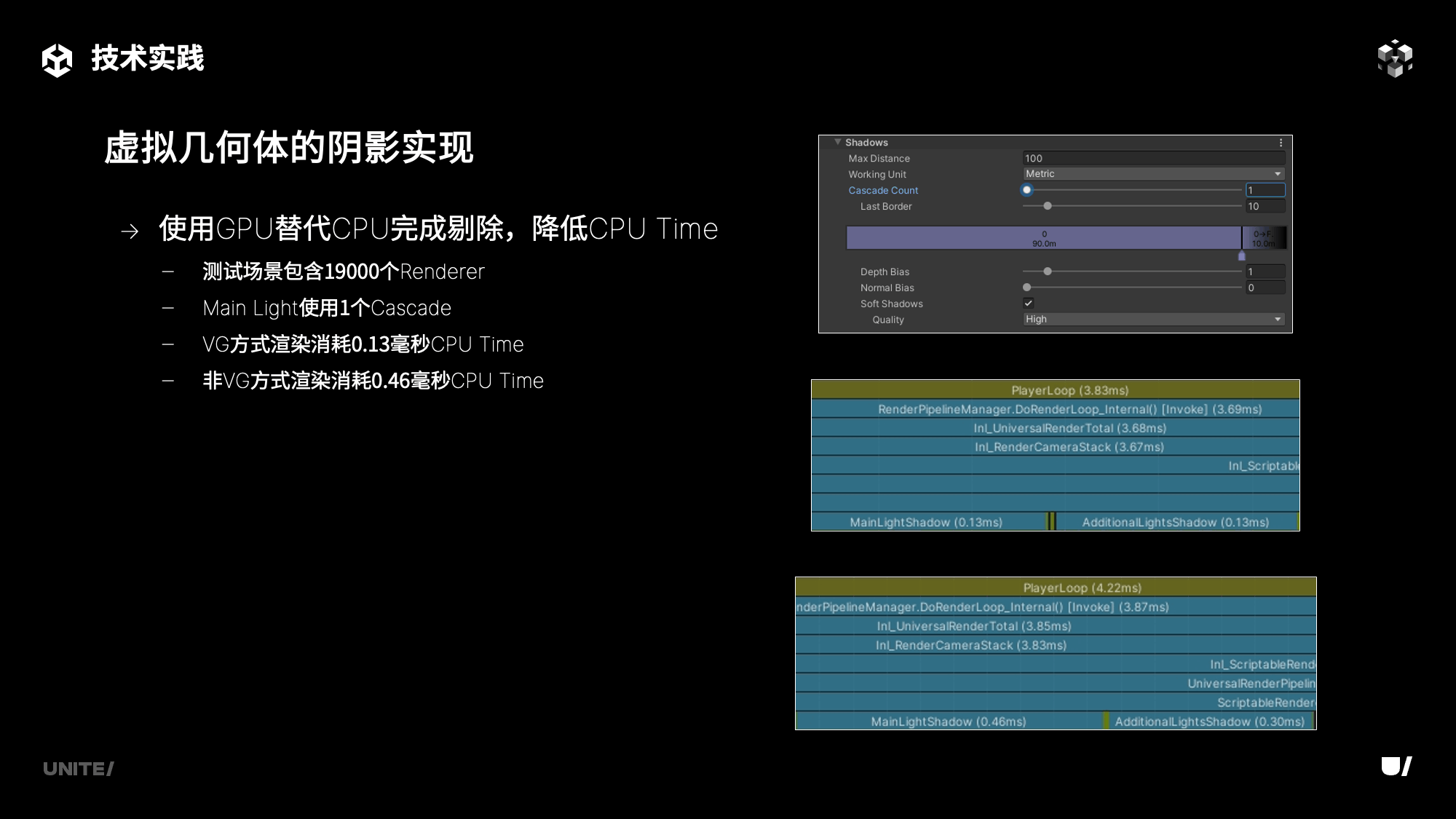
以Main Light的CSM阴影为例,我们进行了测试,所选择的测试场景是刚刚实机展示的场景,该场景包含了约19000个Renderer,使用GPU取代CPU完成剔除,在1个Cascade下,VG相较于非VG的方式节省了0.33毫秒的CPU Time,这部分时间的减少主要源于CPU不再参与剔除工作所带来的优势。

随着Cascade数量的上升,VG相较于非VG方式的性能优势会更加明显。因为对于原本的CMS方案,在CPU进行剔除,每一个Cascade都代表了一次剔除的操作。
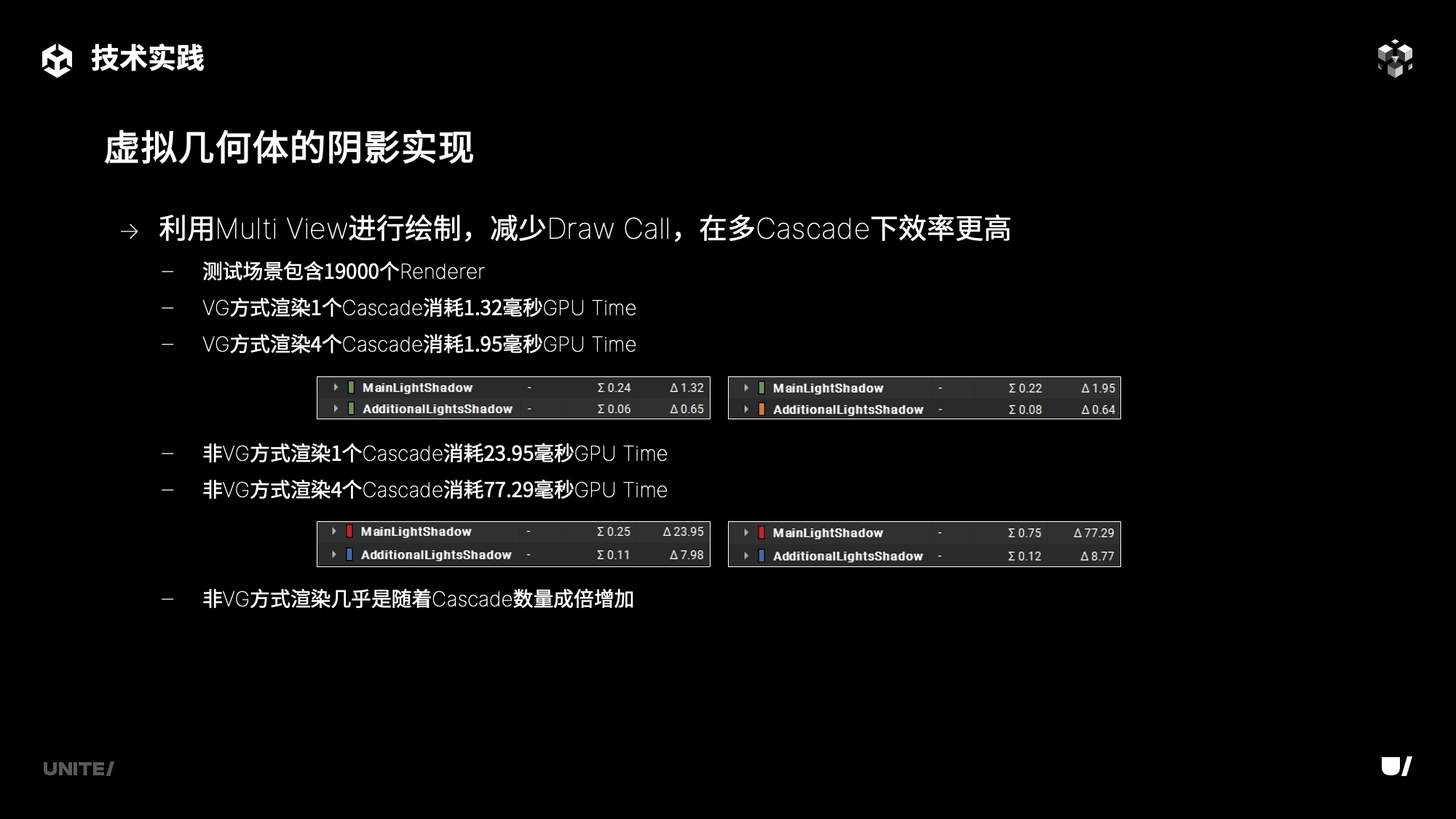
而Multi View的引入则是在GPU层面提高了渲染效率,同样是该测试场景,分别在1个Cascade和4个Cascade的情况下,非VG方式渲染的GPU Time则几乎是随着Cascade数量的增加成倍增长,而VG方式渲染CSM的GPU Time并没有随着Cascade数量的增加增长。这为虚拟几何体的CSM带来了更高的多Cascade渲染效率,在有多个产生阴影的Additional Light光源时,提升尤为明显。
面临问题与未来方向
以上是技术实践部分的内容,接下来我将讲述目前团结引擎移动端虚拟几何体功能所面临的问题和未来的开发方向。

受限于目前移动端设备的硬件和图形API。目前团结引擎的移动端虚拟几何体功能支持iPhone 8及之后推出的苹果移动端设备,即A11及之后推出的A系列和M系列的苹果移动芯片。对于安卓设备,天玑支持9200及之后推出的9000系芯片。骁龙支持8 Gen2及之后推出的8系芯片。而对于不支持的移动端芯片,我们遇到了不同硬件、不同驱动和不同系统所带来的渲染表现不一致和早期芯片硬件设计对现代化图形API特性支持较差等问题。
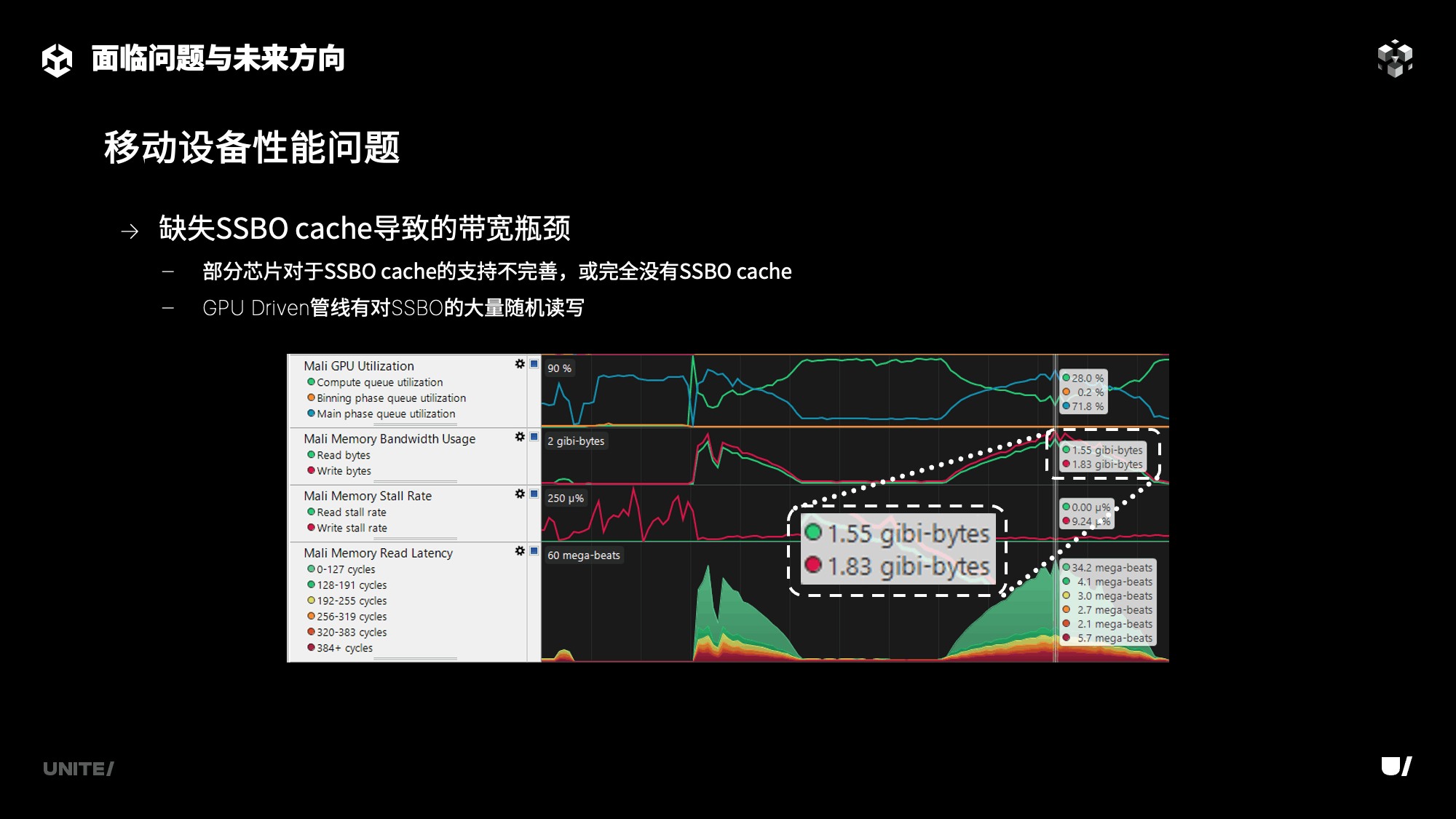
比如GPU Driven的渲染管线所必需的特性就是SSBO,GPUDriven渲染管线所依赖的SSBO在部分移动端芯片上支持不够完善,例如没有SSBO Cache,这会给我们带来严重的带宽性能瓶颈。

目前我们会不断测试更多机型,以期将移动端虚拟几何体功能带入更多的安卓和苹果端设备。而在开源鸿蒙系统方面目前我们已经测试可以成功运行,不过它还存在部分性能瓶颈。未来我们将发挥团结引擎对多平台的支撑优势,尽快完成对开源鸿蒙系统的支持。后续我们会在论坛以及各个方面持续收集各位开发者的建议,对移动端虚拟几何体的渲染性能持续进行优化。
今天的分享就到这里,感谢大家的聆听!

分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐

 0
0 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)