
Unity Open Day 北京站-游戏专场:GPU-Driven实现移动端大规模氛围 NPC 渲染
【获取 2023 Unity Open Day 北京站演讲 PPT】王天宇:大家好,我是来自完美世界的王天宇。我分享的是P5X项目技术细节。“女神异闻录:夜幕魅影”这个IP相信大家都很熟悉,P5X就是这个项目的代号。游戏的涩谷可见人数能够达到80-90人,全场景人数是560个人,手机可见距离是60米。图中的场面就是我们印象中的涩谷,影视剧中经常出现十字街口的场面,我们在实际游戏场景中也是基于现实表
·

王天宇:大家好,我是来自完美世界的王天宇。我分享的是P5X项目技术细节。“女神异闻录:夜幕魅影”这个IP相信大家都很熟悉,P5X就是这个项目的代号。

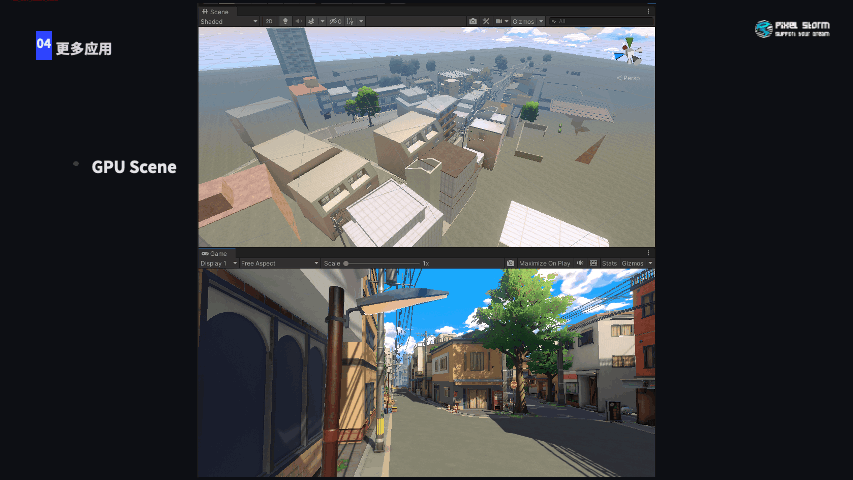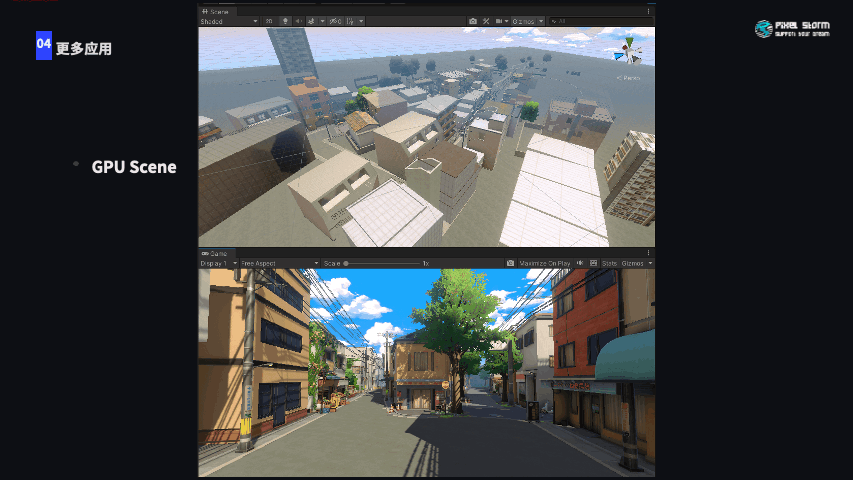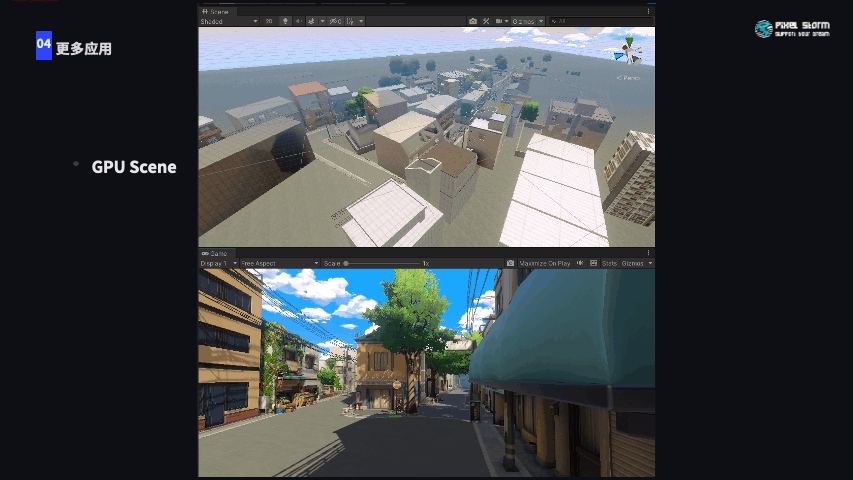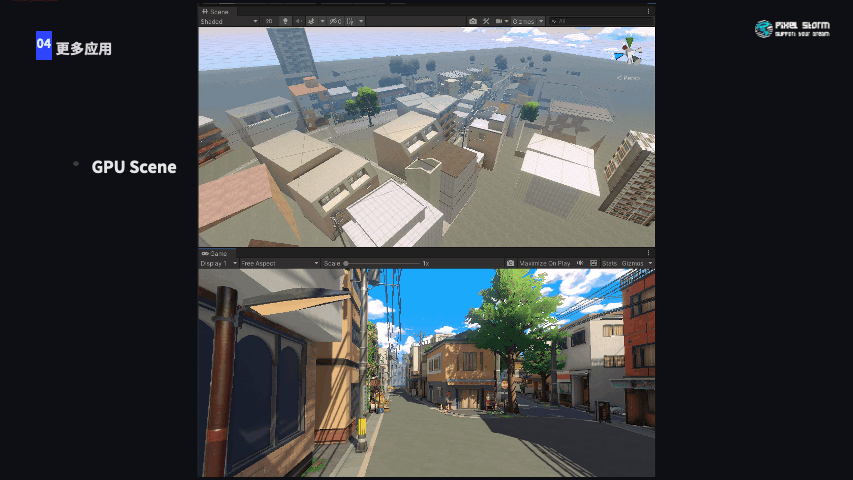
游戏的涩谷可见人数能够达到80-90人,全场景人数是560个人,手机可见距离是60米。图中的场面就是我们印象中的涩谷,影视剧中经常出现十字街口的场面,我们在实际游戏场景中也是基于现实表现出庞大的人流效果。



P5(女神异闻录5原作)故事发生的舞台之一也是涩谷,原作游戏中无法走到涩谷街头的近处,对这一场景的刻画就是简略的形式一带而过,玩家并不能实际看到这一著名的地标级现象。我们的团队比较有野心,希望能够刻画这一场景,并且在手机上达到60fps的流畅度。

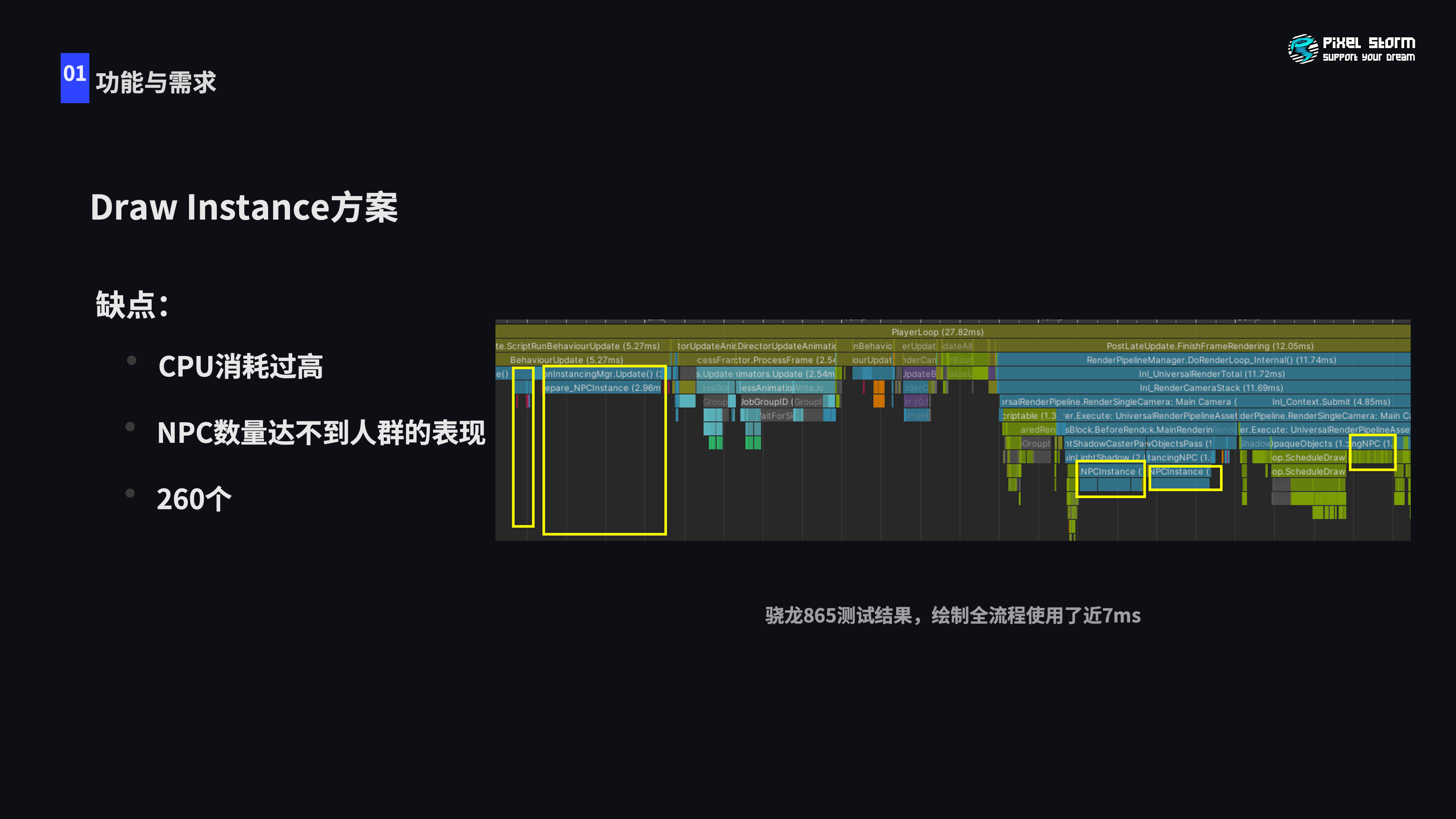
对于这种大规模的渲染,最开始考虑的传统方案是Instance,Instance方案能满足策划灵活的需求,但最大的性能瓶颈出现在CPU。Update是对每个NPC根据策划配置获取当前的状态,渲染之前需要把这些状态组织成Buffer提交到GPU。虽然在这个过程中可以插入逻辑满足策划的特殊需求,做到每一帧控制每个NPC,但对于16毫秒目标来说,仅NPC就有7毫秒的渲染组织耗时是不可接受的,所以我们需要更好的方案和表现。
我们下定决心彻底解决这个问题,所以和策划商量,大家能不能在表现和性能相互妥协,达到可行的方案?我们整理了当前策划需要的全部表现需求:NPC行为可以配置,需要完成站立、走动和动作,包括过马路的行为;NPC持有的物品可以切换,服装可以改变颜色,其实都是为了增加资源的复用性,通过少量的NPC种类能够达到好像有很多人的感觉;最大的要求就是一定要表现出来整个场景过马路的壮观景象。
NPC配置表中数据都是固定的,问题就会被简化成对大量数据的并行处理。刚开始我们考虑用CPU并行的方式(如Job System)进行处理,但估算之后可能还会有2-3毫秒的延迟,后来就考虑到GPU-driven的方案。

很多年前,GPU-driven在主机和PC就已经应用很广泛了。但是这种方案始终受限于市场硬件对Computer Shader和Buffer的支持,我们大规模使用这些方案还是很谨慎的。考虑到氛围NPC场景并不是非常硬性的渲染需求,可以在较低档机器回退到Instance甚至更低的方案灵活使用,而且这种方案确实可以解决高档机的性能问题,所以我们还是考虑用这种方案去做。
GPU-driven的关键点在于首先需要用GPU决定哪些物体绘制,其次减少CPU/GPU之间的回读,不用去等GPU做同步的操作。只要满足这两点,大部分情况下GPU的效率远高于CPU并行的效率。CPU要做的事情就是进行简单的绘制命令调用,甚至如果场景NPC数据不去修改的话,连Buffer都不用更新,GPU还可以进行更细粒度的剔除。

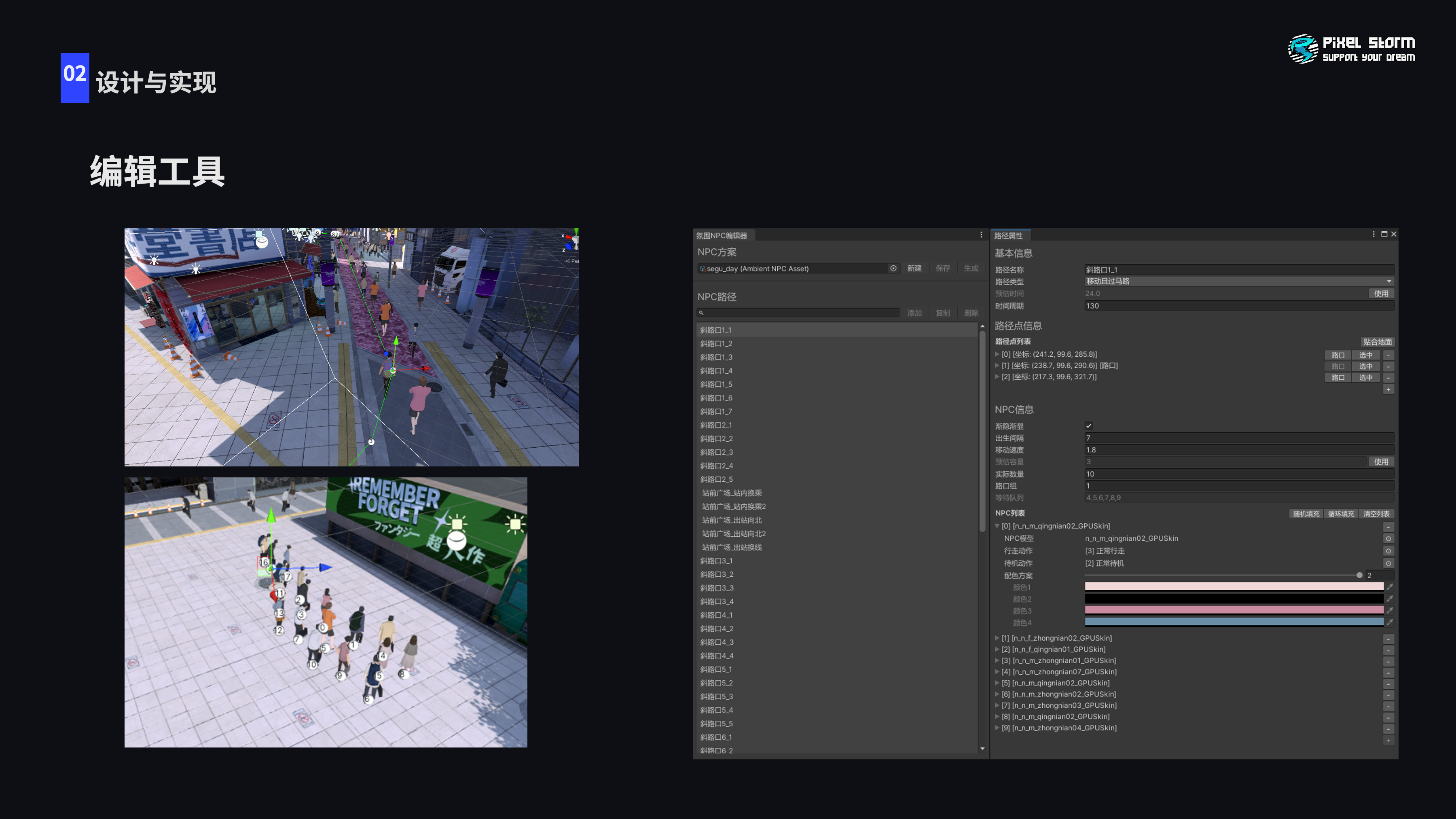
为了尽可能减少NPC数据,我们跟策划商量将NPC行为设计为循环,这些数据在整个游戏时间都是可以复用的,能够把当前的数据固定下来,这些数据打包整体上传到GPU。例如一个NPC生命周期是180秒,会在生命周期内根据自己的配置持续行为。GPU只需要跟CPU同步的全局时间即可在上传的配置中查询当前NPC状态进行表现。
除了刚才表现相关的内容,我们还要在Computer Shader中完成剔除的过程。剔除结果的index存在一个Buffer中,后续再用Instancing indirect的方式为每个不同的NPC材质提交一次绘制指令。

为了将NPC移动逻辑放到GPU计算,我们选择的还是比较基础的配置路点的方式,通过插值完成NPC移动。为了压缩数据,我们每个路点都是3D坐标加上Y轴旋转,因为处理的都是人物的移动。经过实际摆放,我们发现10个路点可以满足NPC全部行为需求。

动作表现还是传统的GPU Skin方案,烘焙到texture中。我们与美术在资源上进行了协商,保持骨骼数量在30根以内,以30FPS对动画进行采样,正常使用256×256贴图可以记录20秒左右的数据,能满足NPC动作需要。动作采用两骨骼混合,可以减少一些计算消耗。我们后续还是做了60FPS和更高精度的GPU Skin数据,可以满足一些half精度处理不了的动作问题。

图中可以看到剔除的结果,右侧摄像机被阻挡部分的NPC就不用画了。剔除方案在PC使用HIZ;对于移动平台,由于显示距离是比较短的,大多数绘制并没有被遮挡剔除掉,所以如果使用HIZ剔除反而是负优化,因此移动端我们简单使用了视椎剔除。剔除过程中因为绘制的目标都是比较规整的,所以我们没有用包围盒来做剔除,而是在脚的上面和头的下面选择两个点进行剔除,只要有一个点在视椎范围内就保留当前NPC,也是节省计算的操作。

项目使用的GI是比较传统的Lightmap + Light Probe。NPC希望使用Light Probe GI获取当前的环境信息,做法是在每个路点记录当前的Light Probe数值,NPC移动的时候根据NPC到两个路点的距离作为权重对整个SH(球谐函数)进行插值,得到环境光的信息。

刚才讲的是一些基本的实现思路,项目组还有更加细节的方案满足策划需求。策划首先提出的是需要大量铺设,其次是等红绿灯、过马路,要有多种手持物和换色以减少重复性。NPC和主角过于靠近会有一个渐隐,为了避免透明排序的问题是用Alpha Test。

这是客户端配合开发的编辑工具,通过路线进行编辑。策划最开始会铺设一整条路线,然后在这条路线上只要添加NPC即可,工具会自动设置成随机添加、随机时间间隔,然后路线上会按照一定规则生成NPC。如果NPC路线出现问题也可以按照整条路线排查哪个NPC出现了问题,方便回溯。
对于性能部分,我们着色的对象是很多的,这其实是性能非常敏感的方案。我们在很多地方进行了Trick减少消耗。现阶段是做了GPU Drivin以后,大部分工作被放在GPU,CPU消耗就可以忽略不计了。像素着色方面,我们对Shader绘制也做了精简,满足表现的情况下去掉了一些复杂的计算。
现在性能消耗最大的来源就是顶点着色器的GPU Skin,其次是像素着色器。顶点优化部分手段是比较有限的,需要从资源上入手降低顶点消耗。GPU Skin计算的时候使用half精度降低计算消耗,CS计算着色器负责的剔除操作的性能消耗较少,可以想到刚才的场景大概是500多个NPC,剔除操作对于GPU来说并没有那么复杂。
氛围NPC作为不透明物体可以参与各种绘制,包括阴影、PreDepth、MotionVector等。因为绘制的时候需要多次绘制顶点着色器,所以顶点消耗还是非常关键的,优化顶点可以在整个方案做出很大性能优化。

除了降低顶点数量以外,我们还在规划使用的Buffer。目标就是尽可能考虑缓存命中划分数据结构。我们是在CS、VS、PS三个阶段进行绘制,每个阶段需要的数据是不同的,所以根据各个阶段需要的数据把Buffer分成三个部分,让每个阶段能够读取到的Buffer尽可能满足只在这个阶段使用,提升缓存利用率。
关于剔除的部分,我们把所有NPC数据放在一个CS进行剔除,需要的数据就是NPC位置数据,每个NPC都是通用的。剔除结果的index根据NPC数量构成的offset存储下来,调用的时候可以根据预先统计的不同NPC offset加上Instance传入的ID拿到NPC Data的数据。
这里还有一些Trick,包括绘制阴影。因为我们绘制的内容多为角色,没有很大的高低落差,传统的从光源方向正交打投影方式剔除还是有很多浪费,所以在这里考虑直接用视椎相机的平头截体进行剔除,我们把平头截体朝Z轴负方向偏移了一段距离,保证即使NPC出了可见范围边缘仍然能有投影。经过这次提出,在阴影阶段VS消耗会大量减少。

刚才提到NPC会持有不同的手持物,就像刚才大家看到的包和伞之类的内容。我们把这些手持物跟NPC打包到一个Mesh里面,通过增添少量的骨骼,把每个手持物绑定一个骨骼,不需要的时候把这些骨骼Scale设成0,Mesh就不会显示了。切换手持物只是简单地对NPC动作进行切换。GPU Skin贴图大小允许的情况下,这是比较合理的优化方案。

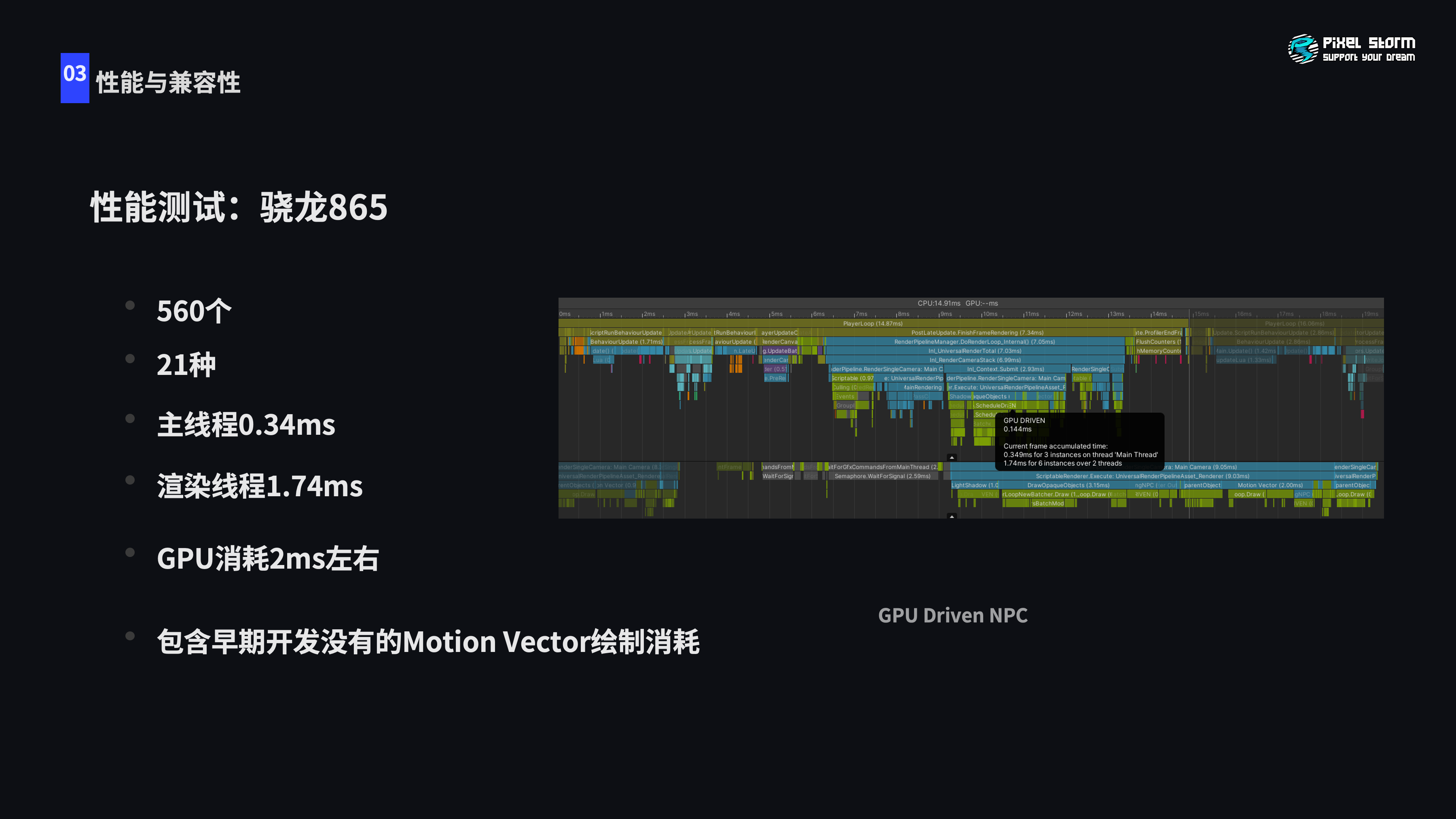
可以看到优化以后的性能测试,数量相比Instance提高到560个,一共21种NPC,主线程0.34秒的消耗可以忽略不计,渲染线程因为渲染状态切换还是有些提交的操作。GPU根据骁龙profiler的测试简单估算,骁龙865大概是2毫秒左右,早期开发没有的Motion Vector的消耗也在计算其中。Android平台实现方案对我们来说比较麻烦,苹果就会相对容易,苹果GPU因为VS、PS和CS可以并行,很多时候VS是免费的,我们的方案刚好是VS比较耗费,跟场景这些不透明物体的PS绘制过程并行,所以很多消耗是免费的,整体方案就会更省,大概就是1毫秒不到的消耗。
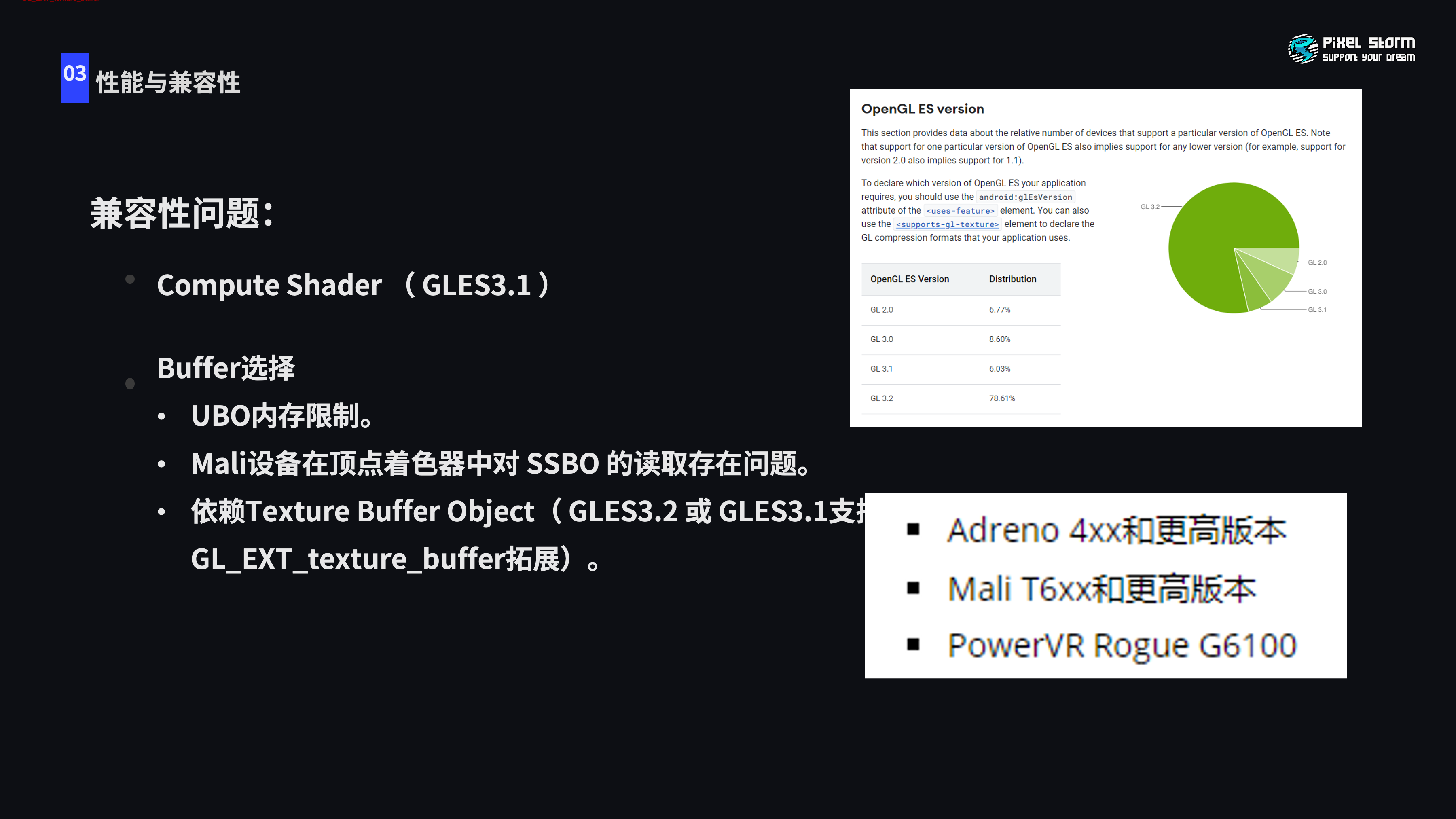
GPU Driven有兼容性问题,Computer Shader的兼容性是GLES3.1。我们的方案会在VS中读取剔除以后的Index数据,Buffer的选择也是一个问题。因为我们是上传整个NPC数据,UBO内存限制导致我们不能使用UBO作为Buffer类型,而Mali设备在VS阶段针对SSBO读取的时候也存在问题,所以最后Android平台选择TBO。全面支持TBO的方案就是GLS3.2版本,3.1版本支持GL_EXT_texture_buffer拓展的情况下也可以支持TBO调用和读取。
顺便一提,我们最后的支持方案是3.1以及GL_EXT_texture_buffer拓展的方案,在公司提供的Top500机型中的比重大概可以达到90%以上,Buffer转换Texture使用Unity提供的自动转换方式。
我们对GPU-driven还有更多的应用,基于传统的GPU Scene,整个场景划分Cluster以后,在镜头被遮挡的情况下对场景的剔除是相当可观的,这一部分应用还在实现中。


分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐

 1
1 0
0- 0



 已为社区贡献740条内容
已为社区贡献740条内容

所有评论(0)