
Unity Open Day 北京站-游戏专场:基于 SRP 的跨平台渲染管线实践
【获取 2023 Unity Open Day 北京站演讲 PPT】邱天行:我分享的主要内容是基于SRP高质量可伸缩管线,包括这样几个部分:背景介绍、面向运行时的LOD Hybrid Pipeline、基于可微渲染的资源生产管线和后续的规划。在大型游戏开发中通常会有一个明确的感受——高复杂度的场景十分依赖运行时的LOD数据。但是往往会忽略两个方面:一个是LOD的生产管线和生产成本;一个是对LOD的
·

邱天行:我分享的主要内容是基于SRP高质量可伸缩管线,包括这样几个部分:背景介绍、面向运行时的LOD Hybrid Pipeline、基于可微渲染的资源生产管线和后续的规划。
在大型游戏开发中通常会有一个明确的感受——高复杂度的场景十分依赖运行时的LOD数据。但是往往会忽略两个方面:一个是LOD的生产管线和生产成本;一个是对LOD的全局认知,我们通常会理解LOD为模型减面,实际上LOD可以从更全局的视角去理解。
Funplus是主要面向海外发布的游戏公司,立志于做高品质游戏,关注用户体验,发布平台包含PC、主机、移动设备。很多时候海外设备是很离奇的,我们经常要在一些莫名其妙的设备上做性能优化,适配很多不太合理的设备,这对渲染管线提出了很高的要求。

我们处理管线的时候也会遇到一些问题:
1.针对不同设备的性能跨度是非常大的。由于我们主要做海外市场,需要考虑北美这种T0市场,同时也有巴西或非洲等设备性能很差的市场。因为是混合类型的公司,所以需要面对不同的游戏类型。
2.URP或者HDRP这些辅助框架虽然都可以针对目标平台提供不错的效果,但如果想生产一个跨平台游戏需要怎么办?既不能选择URP再去升级,也很难用HDRP再做降级,那么就会面临很尴尬的情况。
3.通常资源生产是一个很容易被忽略,但对实际游戏生产更重要的环节,因为涉及到资金开销。
4.如何评估每一级LOD?假设当前有高配、中配和低配划分,高配肯定是最优资产;但是怎样界定中配应该有多少面数量、DC,或者应该做成什么样?这些通常比较经验化阐述的东西,是否可以通过另外一种思路去做更数学化或者更物理化的建模?

针对我们面临的问题,解决方案归纳起来就是这几点:
1.运行时通过自定义的SRP管线处理URP和HDRP跨度的问题;
2.基于LOD思路的Hybrid管线。一定要用全局的视角理解LOD,不仅仅是简单的模型简面或者Shader简化,需要从包括渲染管线和类似Unity、Adaptive Performance框架的更全局视野评估。
3.我们不仅要考虑运行时怎么快乐地使用LOD,更重要的问题是怎样提高效率生产出LOD需要的资源。
LOD-based Hybrid Pipeline
既然是LOD,必然要对管线进行简单的划分。我们的管线围绕L1到L4进行大致的分类:L1就是最高端,直接面向高端PC和主机平台,L2会面对低端PC和高端手机设备,L3就是通常意义上的海外移动设备,L4会应对更极端的情况。

我们这样分类有内在的考虑:L1核心就是Hybrid管线,需要开启光追相关的功能和特性,所以L1会被直接定位为高端PC。L2对于低端PC和高端手机,肯定会关闭光追相关的特性,但需要在光追实现的功能上做一层Fallback接近光追的效果,代价是损失一部分动态特性,同时在这些设备上做基于Computer Shader或者其它相对比较现代特性的优化。L3更加倾向于保守,为了适配大部分海外设备。L4就是更极端的优化。
来看一个简单的Overview,因为很多项目都是研发状态,不太适合直接分享图片,下面我会用一个简单的建筑模型进行演示,包含一个方向光和传统的天光,提供法线图和ppr的材质,剩下都是靠渲染管线着色。

L1就是针对PC的管线,目标是更高的渲染质量和类似Ground Truth的状态,在此分级下希望尽可能依赖光追的特性,达成动态GI特性和更好的效果。后面也会分享做光追的Tips。
通常说到光追仿佛都是很高端的特性或者很耗费性能的特性,实际上现代渲染管线中也完全可以做到每个像素1spp进行采样,通过时序累加和空间累加的方式达到很高性能的光追。我们会做完整的延时渲染管线,支持更多的点光源,也会有完整的PBR资源,针对PC的规格进行资源生产。

L2针对高端移动设备或者低端手机,这些设备的特点是具备相对比较新的硬件特性支持,包括Instansing、Computer Shader等,但性能没有足够好到跑完整的光追或动态GI。针对这一部分机器,核心思路就是因为刚才已经有了光追实现的完整管线,接下来就要在这种模式下把光追每个效果产生预计算的数据,通过预计算来做一部分缓存。基于Hybrid DeferredShadering进行光照和GI方面的处理,最后就是对材质会去做简单的LOD,但会尽可能保持跟刚才的光照效果一致。和L1相比,保留了整体的光照氛围、强度和局部的GI。

L3就是设备再降一级,如果面对比较正常的海外设备,会在这一阶段依赖于Lightmap+Probe+Forward Shading这种比较传统的渲染管线达成和以上接近一致的效果。对于后处理会进一步做限制。对于资源会通过可微管线进行资源降级。

L4就是最差的部分设备,关注的是耗电、功耗和能不能跑,不是跑得怎么样。所以对光照和管线来说很简单,就是做一个全烘焙的lightmap。更极端的情况下,我们也可以做全场景的顶点色烘焙,十分追求性能的情况下甚至可以不依赖于纹理直接完成整个场景的着色。

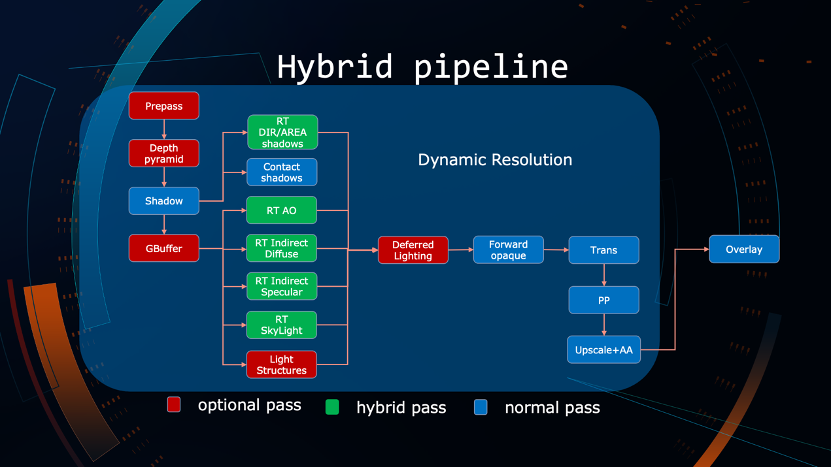
我们的 Hybrid 管线红色部分代表可关闭的部分,核心在Deferred shading相关的依赖上面。比如高配和第二级配置会使用Deferred shading,当降到forward shading时,Deferred shading的部分可以被关闭。
绿色代表 Hybrid 的部分。拿阴影举例,最高配光追模式下可以产生物理正确的软阴影,关闭的时候也可以使用前向管线如传统的 PCF 等方法去近似。对于 AO,最高配会做完整的 Ray Tracing AO,中低配可以用 GTAO 或 SSAO,最差的情况下可以对 AO 做顶点色烘焙。再比如 indirect diffuse 间接光,最高是光追,在中配光追关闭的情况下可以使用 lightmap+probe 做缓存。Indirect specular 同样最高光追,往下一级用传统的 IBL,即把 Indirect Specular 分成几个部分,天光和天空盒会单独处理,剩下缓存到 IBL 纹理处理。Slkyight 一样最高配走基于多重采样的光追,再降一级 skylight 可以使用三阶球协函数进行模拟,运行时会有一个接近天光的颜色。所有都是基于动态分辨率做调整的。
这里主要给大家一些简单的Tips作为抛砖引玉,希望大家找到更加合适的方法。
首先,Hybrid Ray-tracing光追技术更加专注于间接光的部分,因为直接光按照现在的设备来说完全可以实时运算,没有必要使用光追的方式。光追是基于1SPP采样和降噪产生,每帧每像素只做1次光线追踪,但我们会做跨帧的光照累加,通过类似svgf这样的方式合到一张图像上去,流程高度依赖于降噪算法。

做一个简单的示意,左边是1sPP Ray-tracing每帧每像素做一次的采样得到这样的结构图,包括Diffuse和高光的部分,通过每帧1SPP采样进行降噪算法。核心思路就是针对Diffuse、Specular、Shadow进行不同的降噪操作,Diffuse的特性在于低频但连续,Specular是高频信息,可以采用不同的降噪得到相对连续构造的图像(右侧)。

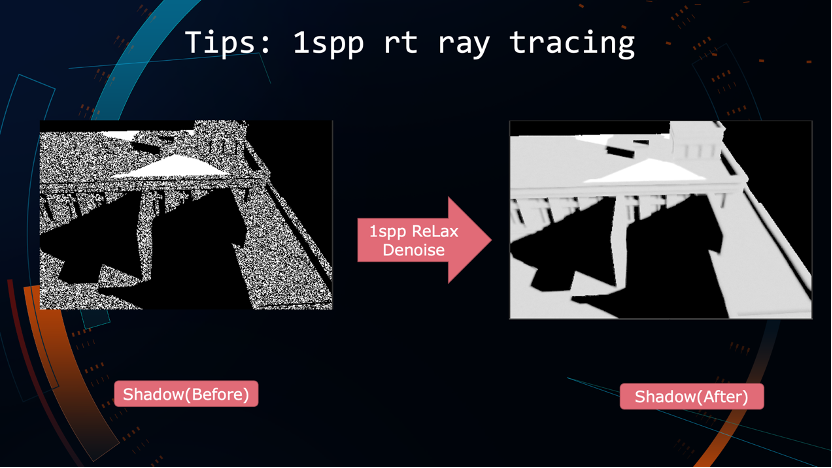
Shadow 也是同样的方法,可以用算法得到相对连续且高频的图像。
最后把这些东西拼接起来就是前面看到的间接 Diffuse、间接高光、直接软阴影加上实时渲染的直接光图像,拼接在一起得到全局 GI 或者动态 GI 光照的 PC 最终画面。

前面一直在说间接光的部分,因为这是比较难计算的,直接光的部分反而比较好理解,这里想分享几个关键点:
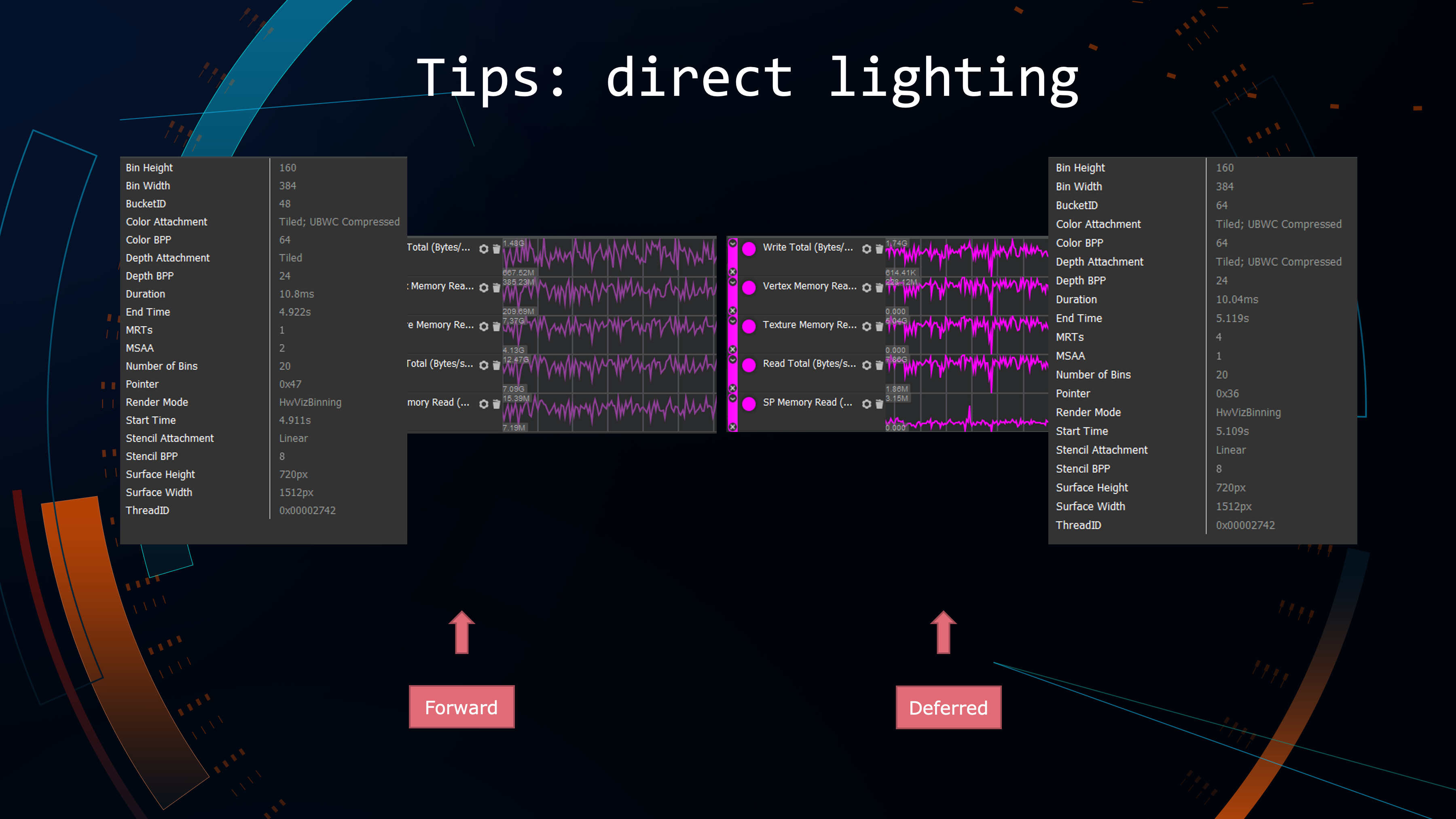
很多时候,我们认为Deferred和Forward Shading是二选一的状态,其实二者并不冲突。因为从光照结果可以达成一致,我们的管线完全可以根据当前的场景负载或者光源数量在两种状态进行动态切换,并不是一定要二选一。如果有同学在做优化的话,Deferred Shading就是可以合理利用片上缓存,不要让片上缓存交换到主存,有效降低总带宽占用。
移动端依赖两个关键特性去做Deferred Shading,如果不支持就会关闭管线:骁龙和其他一些GPU使用MRT framebuffer fetch,mali芯片使用PLS,可以操作片上缓存。基于这些可以保证所有运算都在片上,以降低带宽。这两个特性都有192位的带宽限制,最多4.2T,可以合理规划RT数量,有效降低总的带宽开销。

可以看到,Deferred只比Forward增长不到20%的带宽开销,只要还有附加光源,Deferred shading在正常的移动设备性能都是等于或者高于Forward状态。
刚才讲的是直接光照情况,还有一些烘焙的Tips。
我们是基于自己定制的烘焙器进行烘焙,支持常规的烘焙模式,包括Lightmap或者主流的AHD,PRT (precomputed radiance transfer) 会在某些情况下使用。PRT 本质上在解决的核心问题就是烘焙光源怎样解决 24小时昼夜变换的问题,支持TOD的场景会用PRT烘焙,不需要支持的就会用简单的lightmap烘焙。

这样自己开发的简易烘焙器主要包括几个方面特性:
-
提升局部烘焙质量;
-
生成我们需要的信息,比如Lightmap。优化方案需要依赖PRT或者其它烘焙方式,包括AO,我们需要它能生产出来独立的烘焙数据,那么就依赖于自定义的烘焙器;
-
如果有经常做Unity大场景烘焙的同学会有很直观的感受,场景上不做烘焙的话,烘焙出来的场景和实时状态就会差异比较大,但如果做烘焙就会很慢,因为可能需要等一两个小时才能看到当前场景烘焙以后的结果。我们会在此基础上去做预览模式,核心解决的问题就是通过光追方式预览烘焙之后的场景光照,不需要等到真正意义上烘焙完,加快迭代效率,最终发布版本前进行一次烘焙即可。这个工具本身是用OptiX框架和CUDA做的。

简单图形化对比,左边是各光照模式预览模式的结果,右边是烘焙得到的结果,几乎是完全一致的。上面是直接光的部分,下面是间接光的部分,下一张图是天光的部分,合并在一起就会得到最后的结果。核心是不需要等待烘焙完成,可以直接看到烘焙结果加速美术迭代。


刚才说到质量提升,对比图中lightmap分布是红圈的部分。右边是Lightmapper生成的结果,左边是自己的烘焙器生成的结果,右边碎片化和高频信息丢失比较严重,左边使用自定义的烘焙器让整个场景的软阴影部分看上去更准确一些。

说到动态分辨率和深采样的问题。动态分辨率我们是基于当前帧率和游戏逻辑回馈决定应该产生什么分辨率,虽然我们不会每帧重建RT,但可以调整视口大小达到提升帧率的目的,包括很多细分的分支,比如NSR,以及骁龙有些其它驱动层面的支持,这些都属于动态分辨率的分支用法。无论哪种方法,动态分辨率面临的最困难、最关键的问题是怎样降低帧之间的抖动。因为一旦触发动态分辨率,必然会有视觉上的跳变,最差的就是每帧都在监测帧率,不停触发分辨率调整产生抖动,我们的优化策略核心也是正确处理抖动问题。
一旦把分辨率动态下降,必然要有一个比较好的方式还原到原分辨率。如果什么都不做,默认就是双线性或者三线性差值,但通常可以用更好的算法。因为Upscaling本质是滤波算法,希望找到画面外廓频率比较高的部分做边缘识别。我们做了一些对比和测试,通常备选的就是三线性采样、AMD的FSR(默认集成在URP)、FSR2.0、NIS。根据我们内部的对比结果,NVIDIA NIS做的深采样表现最好,所以我们最终选择使用。
考虑到跨平台,刚才说的主要针对相对差的机器或者移动平台,对于PC只要显卡支持可以直接考虑使用DLSS3,它比较好地实现了机器学习的深采样,确实能够让帧率提升很多,肉眼感受不太能够看得出来调整过。
最后一点,深采样很多时候和TAA都是绑定的,通常深采样算法都要求得到一个经过抗锯齿采样之后的图,TAA可以和深采样同时运作,并不依赖两个PASS。

Differentiable Production Pipeline (可微生产管线)
刚才讲的是运行时管线的思路、Hybrid管线以及每个阶段可能的优化点是什么,接下来分享基于可微渲染的资源生产管线。
为什么要用可微管线?首先,LOD是几乎所有伸缩管线的基准;但在生产LOD的时候可评估性是最大的问题。比如一个模型有5000面,决定把某级LOD减到2000面,为什么要在L2级别把5000减到2000?其实这是很玄学的问题;LOD不仅是模型减面,它需要负担更多东西,包括材质降低、材质合并、光照模型的LOD,这些都是需要考虑的;最后,现在都是AIGC的时代,在此模式下,我们可以用可微管线去做更多的东西。

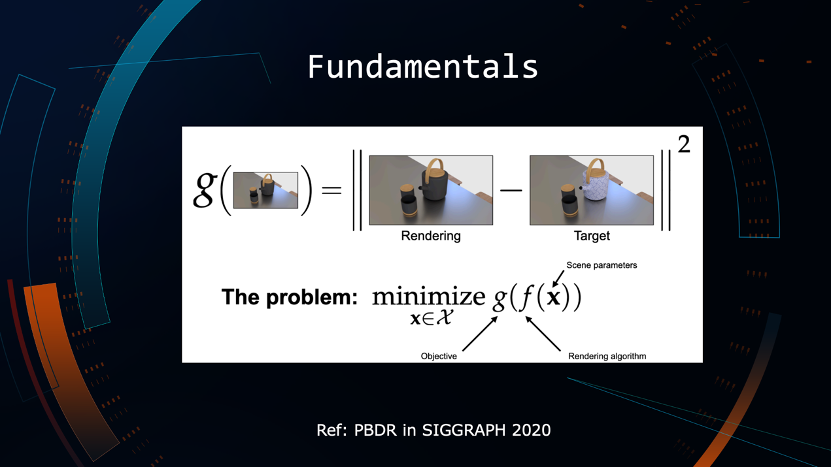
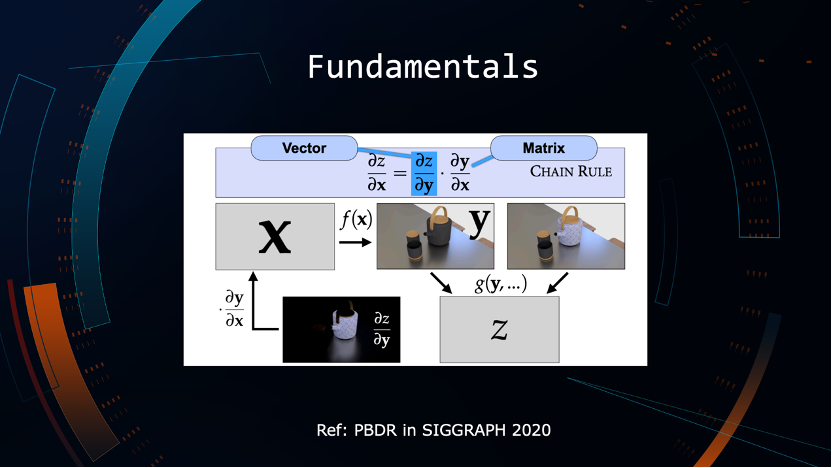
简单分享一下可微理论。图中的X可以被认为是场景的一组参数,比如顶点、几何体、材质、光源,可以理解为一组矩阵或者参数X。通常说的渲染本质上就是函数变换,要把f(x)变成Y,Y是一张2d图像。如果已经拿到最终的图像,有没有可能通过逆运算还原原来的X关键参数?这些是可微渲染需要解决的核心问题。

LOD可以理解为定义损失函数,我们希望生成LOD以后的资产会获得两张图:一张是原资产某个视角下的渲染图,另一张是当前LOD渲染之后的图。LOD本质上是期望在眼睛2D感受不到损失的情况下尽可能把模型面数/材质降低,变成一个简单的数学问题,就是怎样让损失函数最小的情况下能够把面数和其他参数降到最低。
这个数学问题的解法就是我们可以对它做简单的链式求导,得到损失函数的两个分段偏导数:一个是当前对于这一帧渲染图像的偏导,另一个是当前渲染图像对于原图像的偏导。借助自动微分框架就可以得到最优的LOD的解。
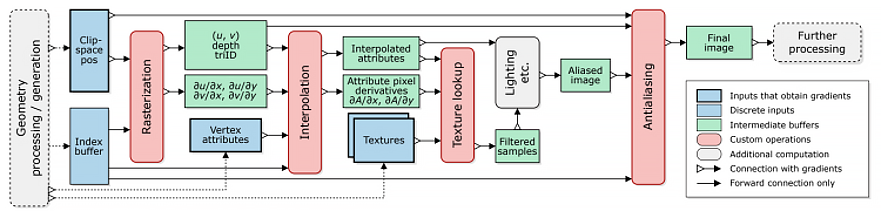
可微管线包括两个大的方向:基于光栅化的可微管线和基于Path Tracing的框架,我们会把这两个合并使用——光栅化后端是Nvdiff,光追后端是Suba3框架。我们的管线会独立在Unity之外,Unity把资源导出,通过可微管线进行模型和材质降配,再重新导入Unity中。

下图是Nvdiff的框架介绍,核心是我们可以把可微渲染管线高度抽象形成几个关键状态:光栅化状态、插值状态、纹理采样、抗锯齿,通过四个关键阶段的自定义最终就可以定义渲染流程。
这种管线的核心思路是要做可控的模型降配,右侧是参考图,上边是第一帧迭代时产生的LOD模型,可以看到是破碎的,没有收敛的状态。经过大概1000次左右的迭代收敛到左下这张图,视觉损失可以用一个很标准的误差函数评估,意味着通过定义每级LOD误差的容忍度来决定每级LOD到底可以减到多少面,能达到最优解。这也是对最开始问题的回答,即我们怎样让LOD的等级和过程自动化和可评估。

下图同样第一次迭代没有纹理信息,可以通过100次左右的迭代快速生成一张质量类似,但实际上排布更优、更小的一张纹理。

最后就是我们的方向考虑和未来工作:
首先,如何借助AIGC的能力加速资源生产?SD(stable diffusion)可以生成图像,加上DR可以还原3D模型,借助材质或者光照复原的能力,可以得到一套完整的PBR资产;
另外,我们可能通过这种方式进行场景的风格迁移,包括快速原型开发;
也会集成PCG流程和能力加速资源生产。

谢谢大家!

分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐

 0
0 0
0- 0



 已为社区贡献740条内容
已为社区贡献740条内容

所有评论(0)