
CECC | Unity DOTS:面向数据编程的技术栈
在第四届中国计算机教育大会(Computer Education Conference of China)上,Unity 中国技术总监张黎明先生分享了 Unity DOTS 的基本概念、应用原理、1.0 版本的最新进展以及未来的开发计划。大家好,非常荣幸参加这次大会,我是 Unity 的张黎明。我给大家分享的内容是面向数据编程的技术栈。我们今年刚刚发布 DOTS 的 1.0 版本,从这个角度来讲它
·
在第四届中国计算机教育大会(Computer Education Conference of China)上,Unity 中国技术总监张黎明先生分享了 Unity DOTS 的基本概念、应用原理、1.0 版本的最新进展以及未来的开发计划。

大家好,非常荣幸参加这次大会,我是 Unity 的张黎明。
我给大家分享的内容是面向数据编程的技术栈。我们今年刚刚发布 DOTS 的 1.0 版本,从这个角度来讲它是一个非常新的技术。但是其实我们已经在 2018 年发布过 DOTS 最早的一个 demo 和当时的技术展示,从这个角度来讲,这个技术已经演进了五年时间。这也是 Unity 未来的一个发展方向,尤其是面向高性能的计算领域提供 Unity 的解决方案。
首先,为什么需要 DOTS?我们可以先看一个视频,Megacity 是我们 2018 年发布过的 DOTS demo。这是一个非常庞大的城市,里面有几百万个静态的 3D 的模型以及上万个音源,有数千个在空中飞行的汽车,它的计算量非常庞大。
在有 DOTS 技术之前,对老的 3D 引擎来讲,想实时做这种大规模的仿真或超复杂场景的渲染是非常困难的。后面会讲到为什么使用 DOTS 技术可以做到这种水平的仿真以及渲染。过去五年时间,Unity DOTS 经过了内部几代的演进,这个 demo 也有了最新的升级版,它是一个开源的工程,大家可以在 github Unity 仓库中找到。
第二个视频是游戏公司使用 DOTS 开发的一款游戏,这款游戏已经上线了。它的特点是里面做了非常多僵尸角色的仿真,有数万个 3D 角色,也是使用了 DOTS 并行计算的架构开发的。相对来说,这个游戏的场景比较简单,但是里面的动态角色是非常复杂的。
简单介绍一下为什么 DOTS 可以做到这样的效果。过去这么多年,CPU 其实已经遇到了一个瓶颈。最近 10 年 CPU 的单核性能其实已经没有太多提升了,不管是英特尔还是 AMD,它的 CPU 性能提升都是通过增加核的数量。现在我们已经能看到 32 核、64 核的 CPU,但是传统的 3D 引擎是很难把这么多核进行利用的。我们常见的引擎可能有主线程、渲染线程,再加一些 worker thread,最多利用十个核之内,无法利用特别多核的数量。DOTS 就能用来解决这个问题,方便我们开发并行计算的代码。
另外,过去这么多年 CPU 都是提供了单指令多数据的向量指令集,但对普通的引擎来讲,非常难把普通的代码进行这种向量化,可能有一部分代码可以向量化,但是向量化的程度并不高,没有把 CPU 里面 SIMD 指令集充分利用起来。DOTS 在这方面也提供了配套的工具。

我们来看一下什么是 DOTS。下方是简单的示意图,最上层蓝色的横条代表我们用 Unity 开发的 3D 程序或游戏。在应用的下层我们提供 ECS(Entity Component System)的框架,基于面向数据的思维设计,方便我们开发面向数据的应用程序。
在 ECS 框架之下有 Job System,它是方便我们把代码进行 Job 化来进行并行计算的工具。右侧有一个粉红色的方块,叫做 Burst 编译器,这个编译器是帮助我们把 Unity 里面开发者写的 C# 代码进行向量化的指令集。
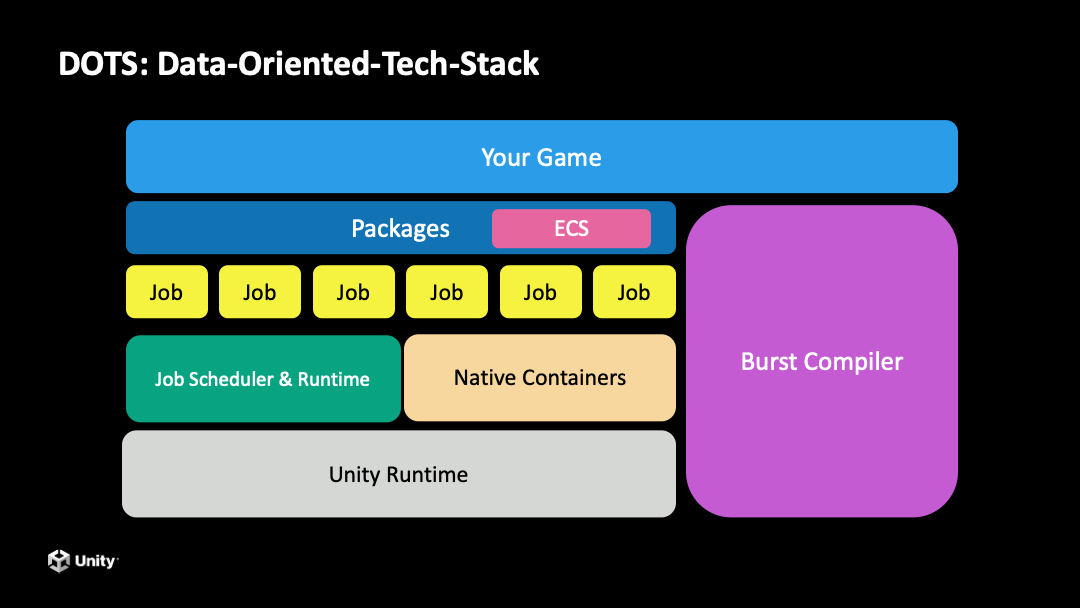
接下来分别介绍一下这三个部分。
首先是 ECS(Entity Component System),它是 DOTS 的一个基础框架。在讲 ECS 之前,首先讲一下 Data Layout 为什么是很重要的。大家应该都知道,CPU 里面是有 Cache 的,CPU 代码执行的时候,一般首次去拿到数据是要在 CPU 的 Cache 进行访问。

当代码去访问一个数据的时候,首先会在 Cache 里面寻找有没有这个数据,如果在 Cache 中没有找到,这就叫做 Cache Miss。
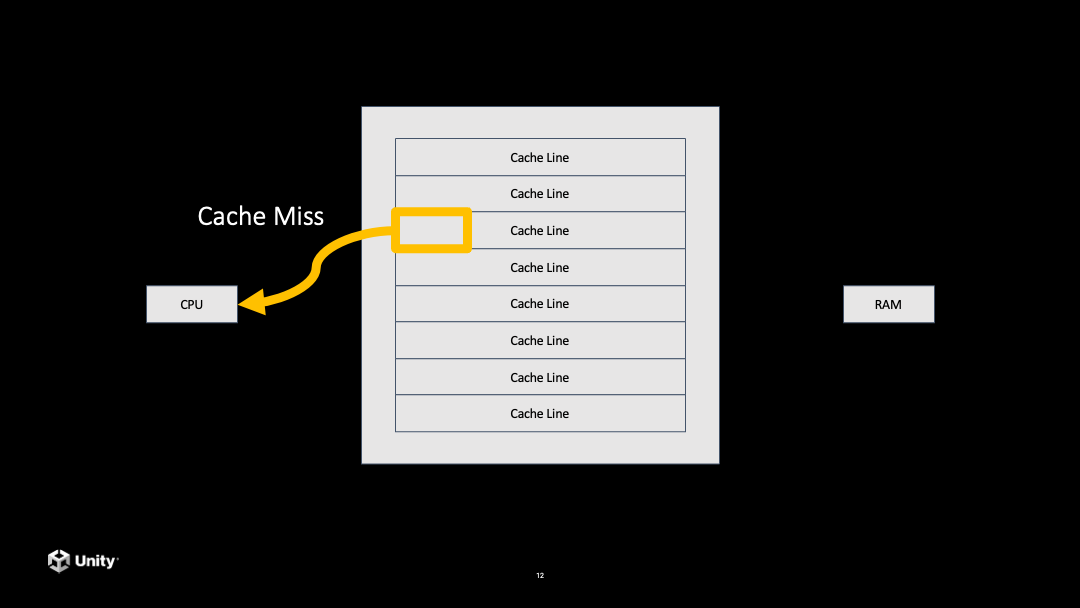
接下来它就要到内存里面拷贝一个数据到 CPU 的 Cache 里面,但是这个步骤是非常慢的。当从内存拷贝到 CPU 的 Cache 之后,再从 Cache 里访问这个数据就会非常快。后面再去访问这一条 Cache line 中的数据都会是非常快的。
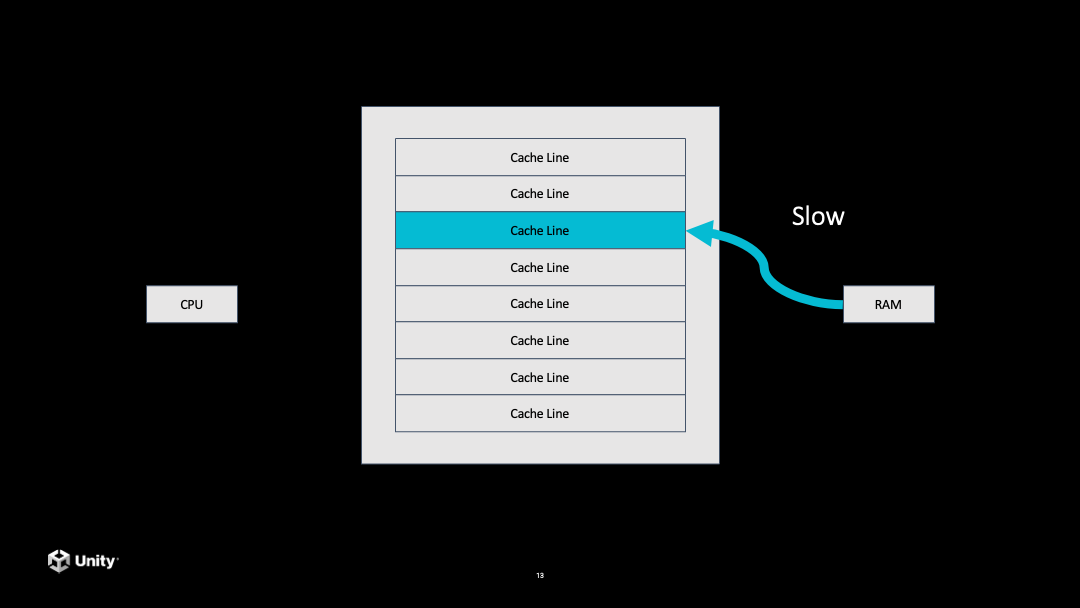
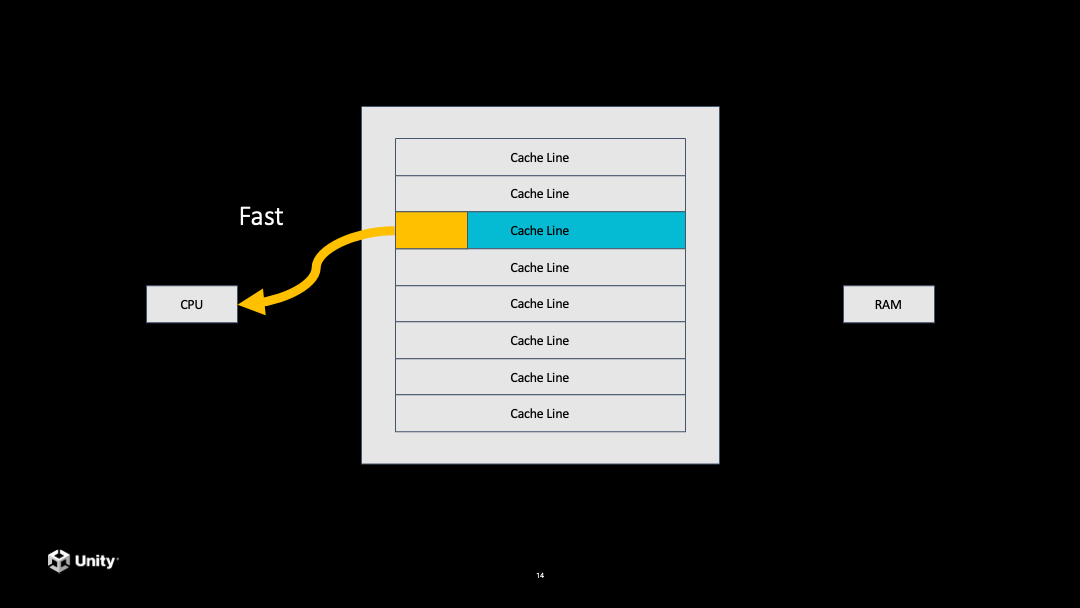
如果后面继续访问数据,发现到了上次拷贝过的数据没有覆盖的另一条 Cache line,就又会发生一次 Cache miss,又会比较慢,需要再去内存拷贝数据。
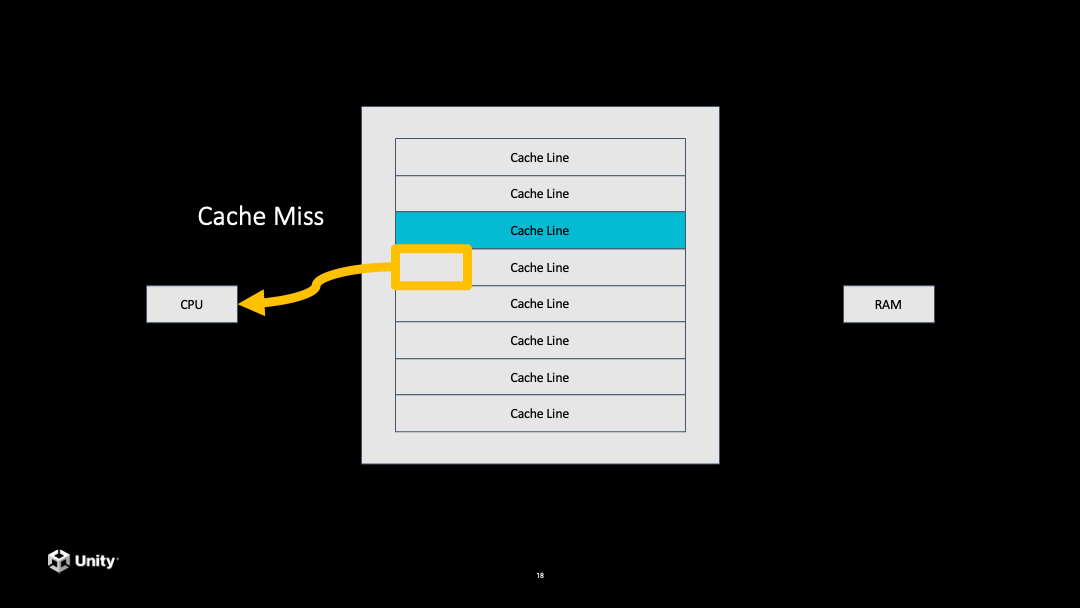
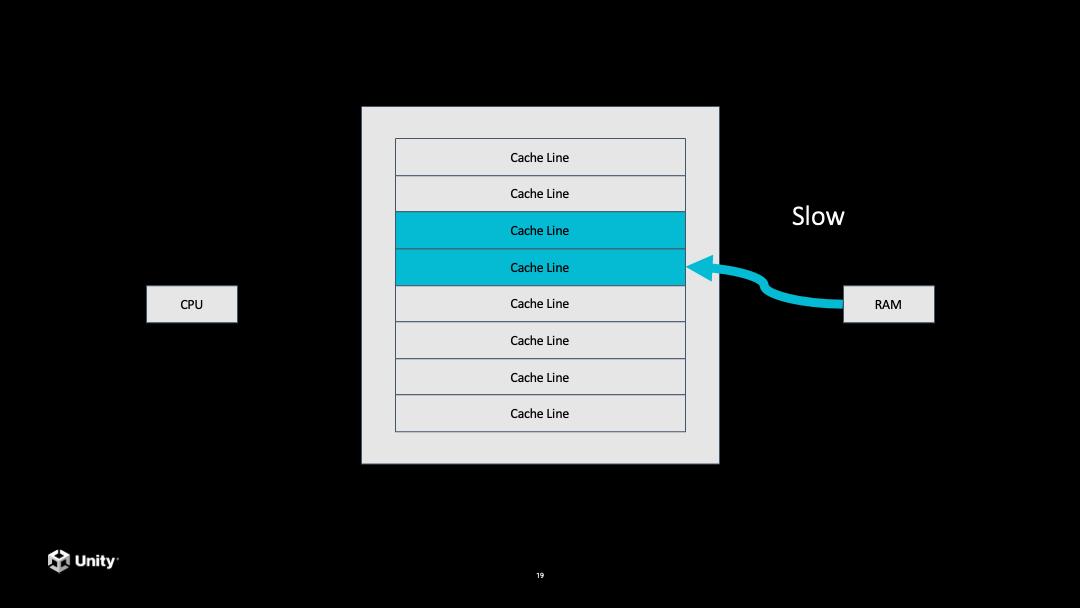
过去我们开发普通的程序就经常会遇到这个问题,内存是随机分配的,代码去访问内存的时候会随机访问内存里面的地址,导致需要不停从内存拷贝数据到 CPU,造成性能降低。
DOTS 希望解决的是尽量把数据在内存里面连续存储,把接下来想要处理的一整块数据全部拷贝到 Cache,再去执行这些代码的时候,执行效率就会非常高。
下图是 Unity 老的基于 GameObject 引擎的内存布局。它是一个面向对象编程的设计思想,里面有很多对象,每个对象都有自己不同的数据布局和逻辑代码,都会挂一个自己的脚本,处理自己的数据。因为不同的对象是随机分配的,内存地址就会访问非常慢。

DOTS 使用了一个全新的设计,引入了 ECS(Entity Component System)的三个概念。Entity 本身里面是没有任何数据的,它只是一个用来标记对象的 ID。Component 是用来存储数据的容器,每一个颜色的方块都是一个 Component。System 是用来处理所有数据的逻辑代码。Unity 会把数据以一个对 CPU 非常友好的格式存储。
还有一个概念叫做 Archetype,如果有很多的 Entity,有些 Entity 可能有四种 Component,这些 Entity 就是一种 Archetype。另外一些 Entity 可能有 6 种 Component,就会组成另外一种 Archetype。当然不同 Archetype 之间可能会共享一些 Component 数据结构,可以去利用这一点来加速计算。

有了 DOTS 的这种数据格式之后,实际去执行代码的时候会有一个操作叫做 Query,来 Query 需要的数据对象进行处理。
举个例子,可能有 10 种 Archetype,其中可能有 5 种 Archetype 都有 position 这种 Component。当想要处理所有 position 这些数据计算的时候,首先执行 Query,查询所有有 position Component 的这些 Entity,可以把它查询出来,并且连续放在内存里面。
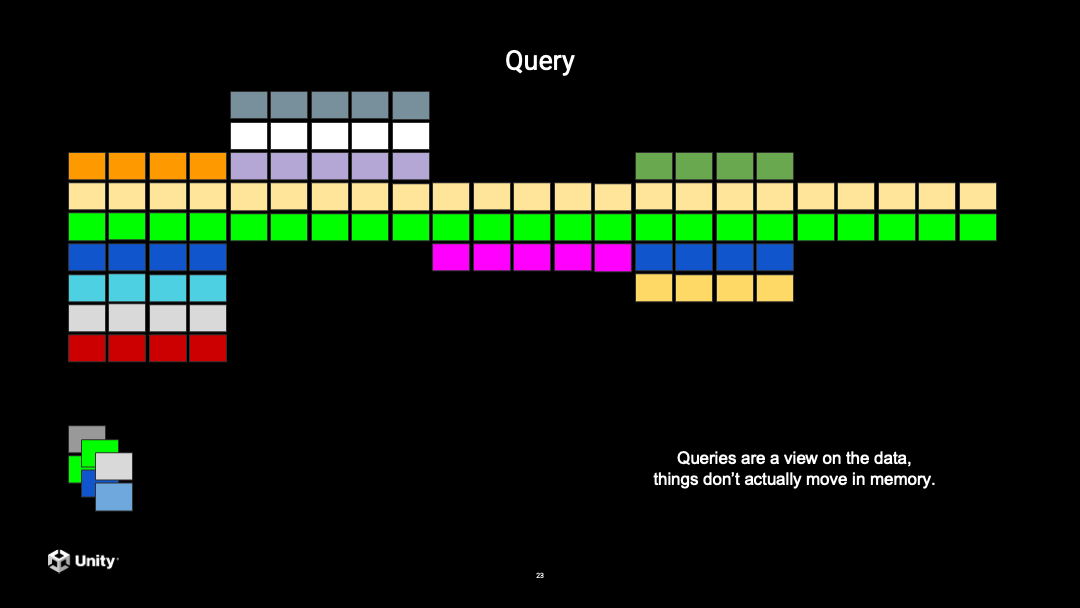
Query 结束之后,下一步就是执行 System 里面的代码,会顺序处理所有的数据。因为这些数据都是连续存储的,会非常快速地拷贝到 CPU 的 Cache 里面,数据计算就会非常迅速。
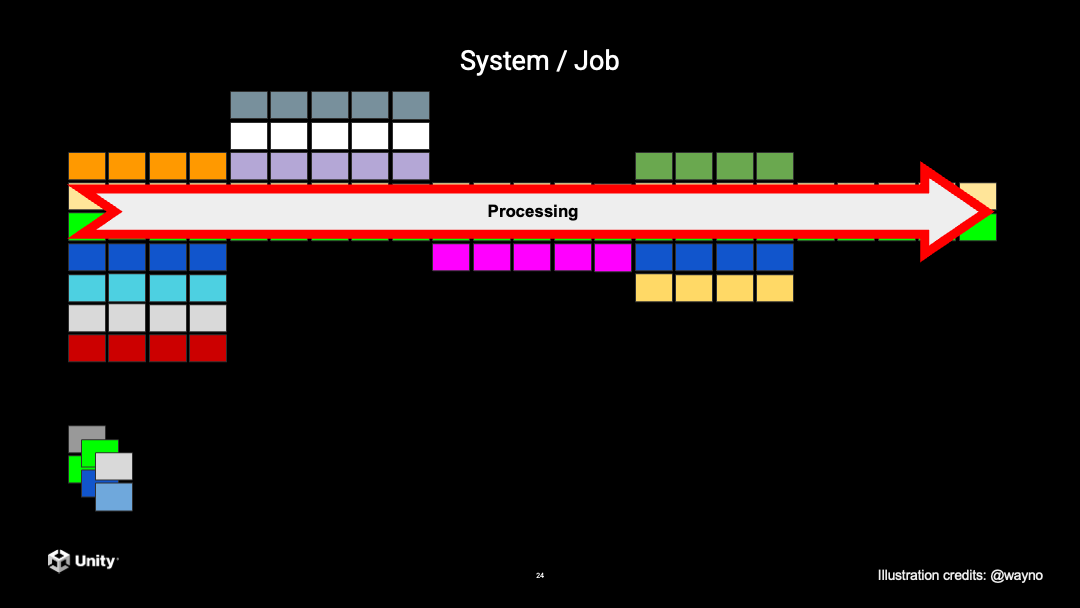
这里其实有几个注意点。首先,Entity 里面是没有数据的,它和老的 GameObject 是不一样的。GameObject 每一个对象里面存储了自己的数据,有自己的脚本,去处理自己的业务逻辑,但是到了 ECS 之后,Entity 是没有数据的,所有的数据放在 Component 里面。System 里面的代码先做 Query,Query 出来需要的数据之后再对它进行处理。

接下来讲我们 DOTS 里面的第二个技术,Burst 编译器。
刚才提到,我们老的引擎没有充分利用 SIMD 指令集,Burst 就是用来解决这个问题。
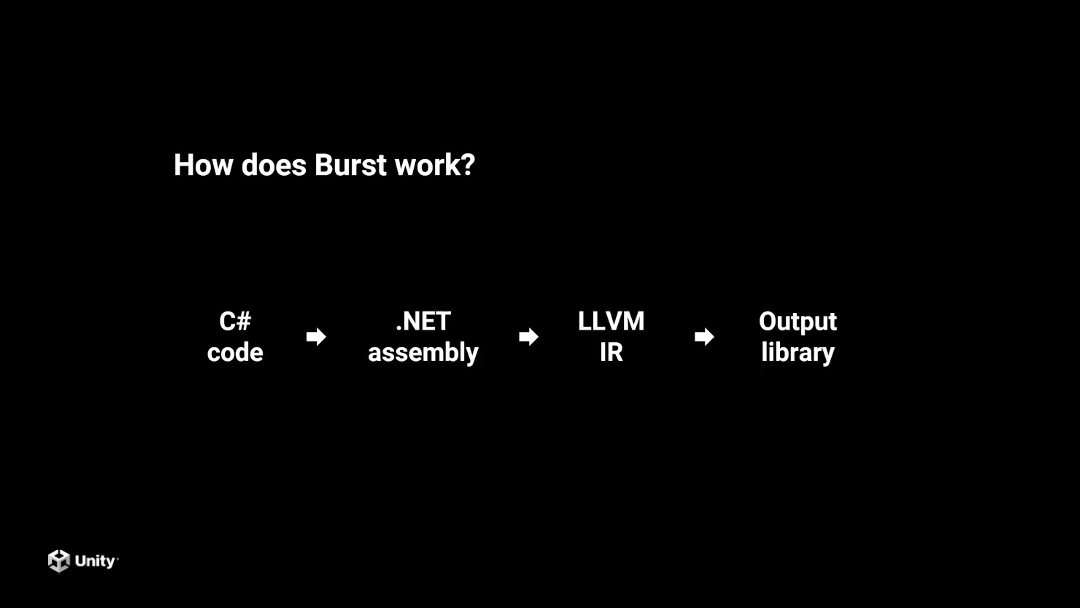
Burst 简单来说是把 C# 的代码编译成最终的 Native 代码,编译的过程中它会使用专用的指令集进行优化,它底层是基于 LLVM 的一套虚拟机以及它的编译工具链。
Burst 是专门配合 ECS DOTS 技术进行设计的和开发的编译器,它并不是一个通用的编译器,不能用它来编译 Unity ECS 之外的代码,因为为了高性能它是有一些限制的。当然 Burst 也支持 Unity 支持的所有 20 多个平台。

为什么 Burst 可以让我们写的 C# 代码性能非常高?因为做面向数据编程的话,里面的数据大量是向量、矩阵,这种数据是特别适合进行用这种向量指令集进行计算的。其次 Burst 编译器是知道 Unity 内部数据结构的,所以它非常方便做这种数据上的优化。
另外 Unity 还提供了专门的数学库,不管是做向量计算还是矩阵计算,所有数学计算是专门用这种向量指令集进行优化过的,它也会让 Burst 更方便执行。

Burst 整个执行过程非常简单,其实就是把 C# 先编译成 .NET 程序集,然后再编译成 LLVM 的中间码,再变成最终的目标平台代码。
Burst 的使用非常简单,只需要在 Job System 代码前面加一个 attribute 表明这段代码是使用 Burst 编译器进行编译的就可以了。

当然它是有些限制的,首先 Burst 只能编译 Job System 里面的代码,过去的 Monobehaviour 等那些代码是不能编译的。另外在这些代码里面必须使用值类型的数据,里面的数据结构是 Unity 提供的 NativeContainer、NativeArray 等,需要使用我们专用的数据结构,另外不支持一些引用类型的数据。我们把它叫做 high performance 的 C#,相当于是一个删减版。

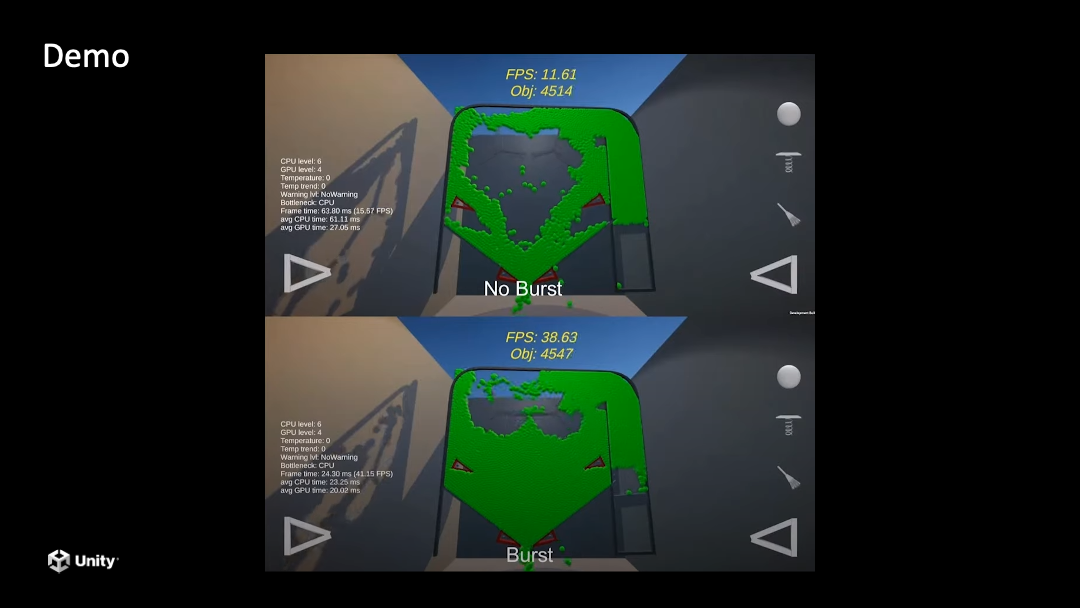
我们的自己内部做过一些测试,下面是 Burst 优化过的,上面是没有优化过的。单纯就这一个功能是可以让它的帧率有成倍的提升。
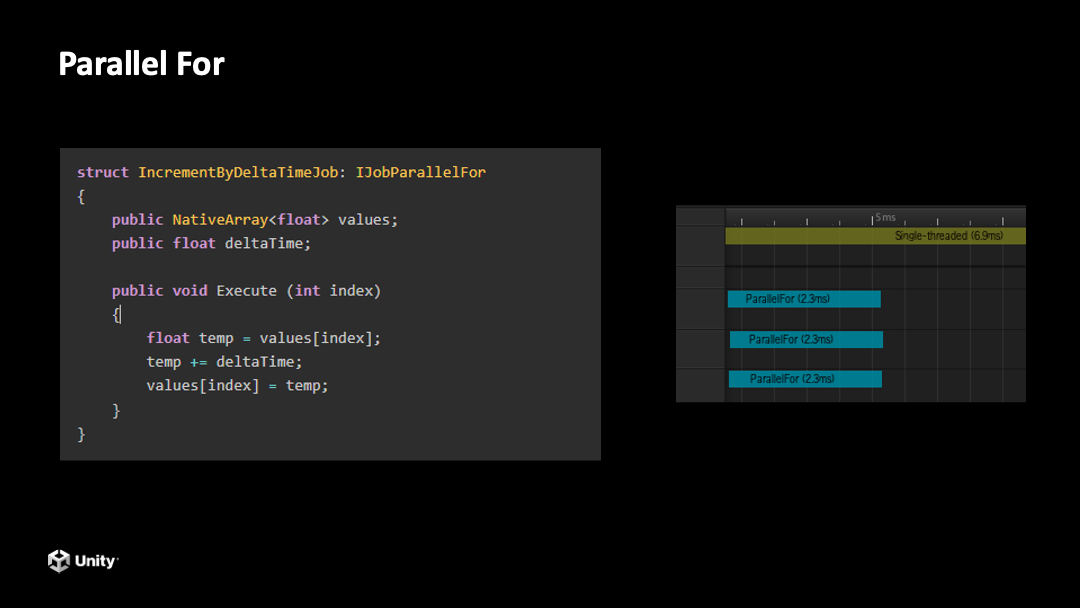
最后简单说一下 DOTS 技术栈里面最后一个技术 Job System。它是帮助我们做并行计算的工具,里面也提供了一些方便写代码的如 Parallel For 等便于开发的语法糖等。
讲完了什么是 DOTS,接下来讲一下我们今年刚刚发布的 DOTS1.0。DOTS1.0 的正式版的会在今年晚些时间发布,预览版已在 Unity2022 版本中提供支持。
我们过去 5 年一直在迭代这个技术。之前是面向对象的编程,如今是 Entity Component System,设计思想发生变化,导致我们整个编辑器工具和 DOTS 是不完全兼容的。所以过去 5 年时间,我们有很大一部分工作量是面向 DOTS 开发新的编辑器,在 1.0 里面已经提供了 DOTS 相关的编辑器工具,如下图列表。

虽然我们的整个开发环境都发生变化了,但我们现在提供的方案是让开发者在编辑场景阶段还可以使用老的编辑器 GameObject 方式进行编辑,编辑完之后有一个转换的过程,可以把它转换成 ECS 格式的数据存储。所以 DOTS 是兼容我们老的编辑器的。
在 DOTS1.0 里面我们提供了网络同步的 package,方便开发多人联网游戏,用来做大量玩家的数据同步。使用 DOTS 之后网络游戏玩家数量的规模就可以做得更大。传统 Unity 引擎的一些网络工具可能可以做 16 或 32 人同步的网络游戏,有了 DOTS 之后,我们可以做数百人甚至上千人规模的网络同步。

DOTS1.0 里面包含了 DOTS 的物理引擎——Unity 现在全新开发了面向数据的一套物理引擎。另外我们也集成了微软 Havok 的物理引擎,也是以 DOTS 的接口集成到 DOTS 引擎里面的。

像刚刚展示的 Megacity 这样的游戏对整个程序的性能有了多方面的要求。除了渲染之外,未来的元宇宙或游戏可能是上百 G 甚至是上 T 的数据量,不可能全部放在本地硬件上面,需要提供 On-demand Streaming 的能力,动态从云端下载需要的 3D 资源。所以,DOTS 也提供了诸如本地动态加载、云端数据 Streaming,大规模渲染等能力。

最后再介绍一下 DOTS 接下来的开发计划。
上文提到 DOTS 已经替换了引擎的一些基础底层能力以及模块,长远来看,DOTS 需要把整个引擎进行重写。DOTS 有两个层面,一个是要让整个引擎的底层变成面向数据开发的,这样能让整个引擎底层性能非常高;另一个是面向开发者开放出来的一层框架,让开发者开发的代码也可以面向数据,提高代码的性能。
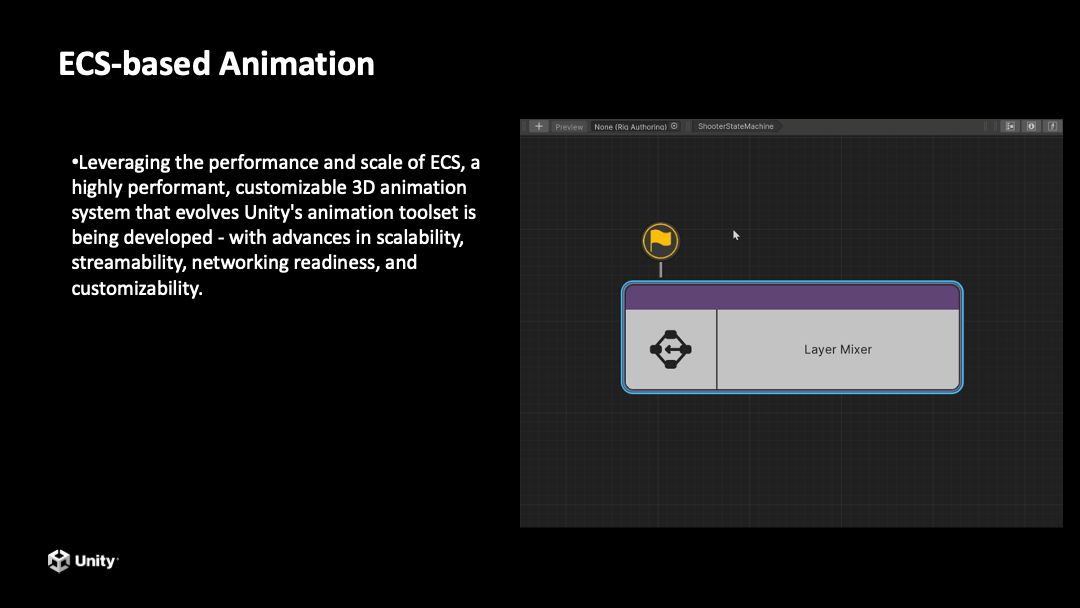
Unity 底层功能模块的面向数据的改造现在完成了一半,接下来我们还会改造更多的模块。动画系统已经在改造的过程中,预计明年会有一个全新的面向 DOTS 的动画工具,它包含了新的动画编辑器以及新的动画 runtime 模块。
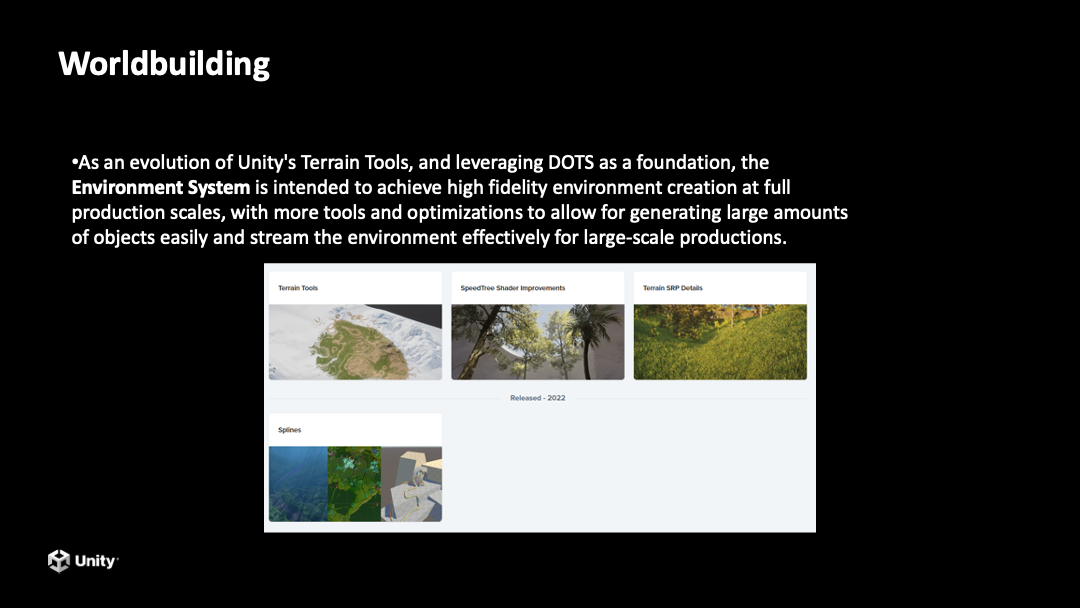
另外我们也会面向 DOTS 提供一些新的 3D 场景构建工具,包括新的地形工具,Speedtree 也会和 DOTS 有更好的整合来做树的建模,以及更多场景相关的编辑功能。
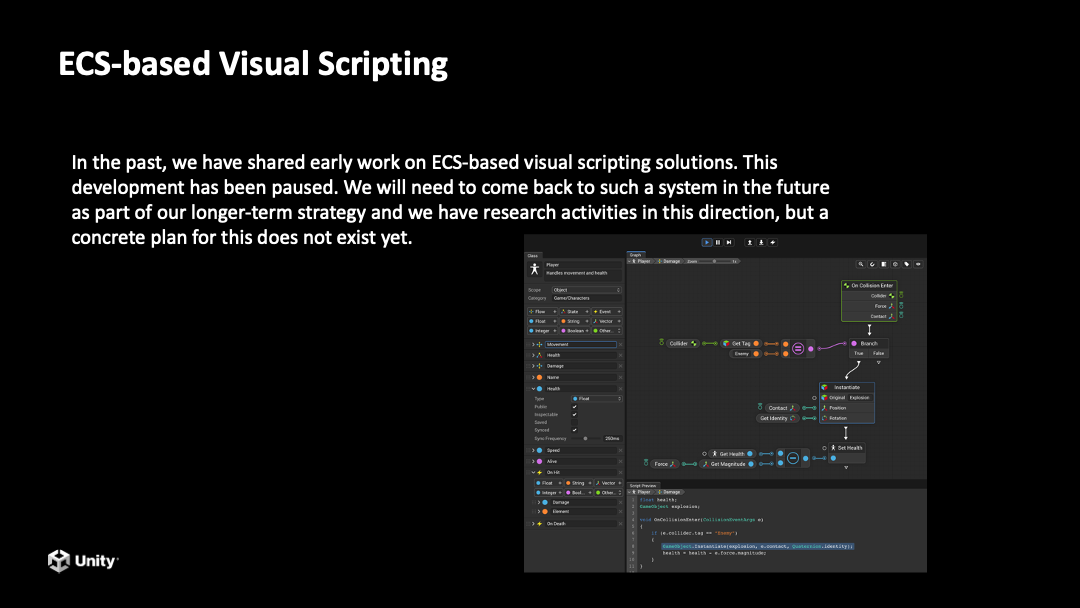
DOTS 是从面向对象到面向数据的一个非常大的改变,过去已经有很多开发者试用了 DOTS 给出反馈,认为想去掌握 DOTS 这套思想转变还是比较难的。接下来 Unity 也会开发节点式编程工具,主要面向非技术使用者。开发者可以简单拖动节点实现 DOTS 开发。
刚才提到,Megacity 已经做了上万个音源的案例,这个功能当时只是做了一个初期原型,后面我们也会开发一个 DOTS 声音系统,支持非常多的音源播放。

还有其他很多模块 Unity 都是需要重写的,比如导航系统。当场景里有了几十万个角色,每一个都要有独立的导航,过去的导航系统肯定性能是不够的,我们也会开发 DOTS 新的导航系统,包括各种方便开发者开发的 Debug 工具等等。


总结一下,Unity DOTS 主要面向高性能计算提供了最新版的引擎,今年已经发布了 1.0 版本,我们鼓励开发者把它用到实际的商业项目中。未来几年我们也会对整个引擎做更深度的改造,让 DOTS 覆盖的功能模块更多,让最终的应用程序在性能上得到更大提升。
谢谢大家。

分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐

 0
0 0
0- 0



 已为社区贡献718条内容
已为社区贡献718条内容

所有评论(0)