
高效访问纹理数据,持续优化整体性能
Unity 里的像素处理像素是纹理最基本的组成单位,而 Unity 有多种用 C# 脚本读写像素数据的方法。这样就可以实现复制、更新纹理等多种功能,比如给玩家的头像加上装饰、读取地图的纹理来决定物体的摆放位置等。像素数据的读写有很多途径,需要根据数据处理方式和项目性能要求来选择最佳的方法。这篇文章及配套的示例项目旨在帮助开发者熟悉现有的 API 和常见的纹理相关性能优化方式。CPU 与 GPU 的
·
Unity 里的像素处理
像素是纹理最基本的组成单位,而 Unity 有多种用 C# 脚本读写像素数据的方法。这样就可以实现复制、更新纹理等多种功能,比如给玩家的头像加上装饰、读取地图的纹理来决定物体的摆放位置等。
像素数据的读写有很多途径,需要根据数据处理方式和项目性能要求来选择最佳的方法。这篇文章及配套的示例项目旨在帮助开发者熟悉现有的 API 和常见的纹理相关性能优化方式。
CPU 与 GPU 的像素副本
对于大部分纹理, Unity 会保存两份像素数据的副本 :一份在 GPU 内存里,是渲染所需的数据;另一份则在 CPU 内存中,属于可选数据,用于读取、写入和控制 CPU 上的像素数据。在 CPU 内存里存有像素数据副本的纹理被称为可读纹理。需要注意的是 RenderTexture 仅存于 GPU 内存中。
CPU与GPU的不同
内存
大部分硬件的 CPU 内存都不同于 GPU 内存。当然现在有些设备具有部分共享内存的形式,但本文只讨论传统的 PC 配置,即 CPU 只能直接访问插在主板上的 RAM,GPU 只能依赖于 VRAM,两个环境间任何数据传输都需要经过 PCI 总线,速度会比同一内存里的相互传输慢很多,所以会对每帧传输的数据量造成限制。
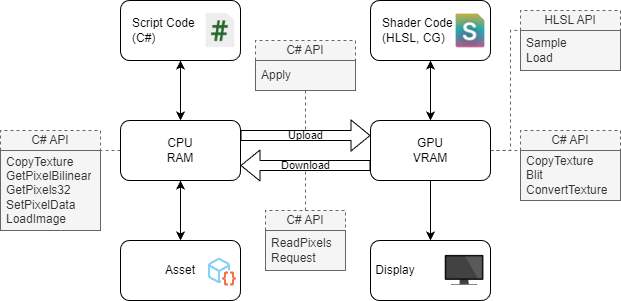
图注:CPU 和 GPU 内存间关系的可视化,以及两者相交的 API
数据处理
在着色器里采集纹理样本是最常见的 GPU 像素数据处理操作。要想修改这段数据,可以复制修改后的纹理,或用着色器把修改渲染到一张纹理上。
有些情况下,在 CPU 上调控纹理数据更合适,访问数据的方式会更灵活。CPU 的处理操作只会作用于 CPU 上的副本,所以纹理必须是可读的。 如想在着色器里采集更新后的像素数据,必须先调用 Apply 把数据从 CPU 复制到 GPU 。视纹理和操作复杂程度的不同,坚持用 CPU 操作应该会让整个过程更快、更轻松(比如把几张 2D 纹理复制到一个 Texture2DArray 资产)。
Unity API 包含有几种方法来访问或处理纹理数据。倘若同时存在有 GPU 和 CPU 副本,部分操作会同时作用于两者。因此,纹理可读与否会影响这些方法的性能。同样的结果可以用不同的方法实现,但每种方法都有自己的性能和易用性特征。
可以回答以下问题,以找出最佳的解决方案:
1. GPU 运算是否比 CPU 快?
-
纹理缓存上的流程会造成什么样的压力?(比如,不用mipmap采集高分辨率纹理很可能会减缓GPU速度。)
-
流程是否需要 随机写入纹理 ,或能否输出一份颜色或深度附件?(写入纹理上的随机像素要求经常清理缓存,这会减缓整个流程。)
2. 项目是否受GPU瓶颈限制?就算GPU执行进程的速度远快于CPU,它能否继续承担更多作业且不超出帧预算?
-
如果GPU和CPU主线程的帧耗时都接近了极限,那流程较慢的部分也许能由CPU工作线程执行
3. 有多少数据需要上传到 GPU 或从 GPU 下载才能计算或处理结果?
-
着色器或C#作业能否把数据打包成更小的格式来减少需要的带宽?
-
RenderTexture 能否精简采样成分辨率更低的纹理用于下载?
4. 流程能否批量执行?(如果有大量数据需要同时处理,GPU有可能会内存不足)
5. 结果是否急迫要用?运算或数据传输能否异步进行或随后处理?(如果单张帧需要执行过多的工作,GPU可能会没有足够的时间来渲染实际的帧图像)
可读与不可读纹理
默认导入到项目里的纹理资产是不可读的,而从脚本创建的纹理是可读的。可读纹理所占用的内存是不可读纹理的两倍,因为 CPU 的 RAM 里也需要一份像素数据的副本。所以建议 只在必要时让纹理可读 , 在 CPU 上完成数据编辑后再把它变回不可读 。
要查看项目里的纹理资产是否可读,或进行编辑,请使用 Texture Import Settings 的 Read/Write Enabled 选项或 TextureImporter.isReadable API。
要将纹理设为不可读,可调用 Apply 方法,把 makeNoLongerReable 参数设为“true”(比如 Texture2D.Apply 或 Cubemap.Apply)。不可读的纹理没法反向变回可读状态。
所有纹理在编辑器的 Edit 和 Play 模式下都是可读的 。调用 Apply 将纹理设为不可读会更新 isReadable 的值,并阻止访问 CPU 数据。然而也有例外情况,有时在此进程仍会把纹理看作可读的,因为内部 CPU 数据仍然存在。
GitHub上的Texture Access API示例

图注:在CPU上每帧生成的纹理
不同的纹理数据访问方式有着极大的性能差距,特别是在 CPU 上(低分辨率时的差距会小一点)。GitHub 上的 Unity Texture Access API 示例仓库包含了一系列例子来展示不同API在访问或操纵纹理数据上的性能差距。本项目的 UI 会展示主线程的 CPU 耗时。部分例子还使用了 Burst 和 Job System 等 DOTS 特性来优化性能。
以下是GitHub仓库里的示例清单:
-
SimpleCopy:将一张纹理的所有像素复制到另一张
-
PlasmaTexture:一张在CPU上每帧更新的离子体纹理
-
TransferGPUTexture:转移(复制到另一张大小或格式不同的纹理)GPU上的所有像素到RenderTexture
下方性能测量结果取自GitHub上的示例。这些数据是随后推荐方法的数据基础。这些结果源自一个搭载3.7 GHz 8核Xeon® W-2145 CPU和RTX 2080的系统。
SimpleCopy示例
这些是SimpleCopy.UpdateTestCase处理大小为2048的纹理所产生的CPU耗时中位数。注意,Graphics方法只负责将工作推送给RenderThread,这一步由GPU稍后执行,所以在主线程上能瞬间完成。这些结果会在下一帧准备就绪时进行渲染。
测试结果
-
1,326 ms – foreach(mip) for(x in width) for(y in height) SetPixel(x, y, GetPixel(x, y, mip), mip)
-
32.14 ms – foreach(mip) SetPixels(source.GetPixels(mip), mip)
-
6.96 ms – foreach(mip) SetPixels32(source.GetPixels32(mip), mip)
-
6.74 ms – LoadRawTextureData(source.GetRawTextureData())
-
3.54 ms – Graphics.CopyTexture(readableSource, readableTarget)
-
2.87 ms – foreach(mip) SetPixelData<byte>(mip, GetPixelData<byte>(mip))
-
2.87 ms – LoadRawTextureData(source.GetRawTextureData<byte>())
-
0.00 ms – Graphics.ConvertTexture(source, target)
-
0.00 ms – Graphics.CopyTexture(nonReadableSource, target)
PlasmaTexture示例
这些是PlasmaTexture.UpdateTest处理大小为512的纹理所产生的CPU耗时中位数。
可以看到SetPixels32出乎意料地要比SetPixels慢。这是因为系统需要获取运算得出的Color浮点值,将其转换成基于字节的Color32结构。SetPixels32NoConversion可以跳过这种转换,为Color32输出组指定一个默认值,其性能要强于SetPixels。为了克服SetPixels的性能问题及Unity底层的颜色转换,必须改写运算方法,直接输出Color32值。采用SetPixelData的效果几乎一定会比仔细的SetPixels和XetPixels32方法来得更好。
测试结果
-
126.95 ms – SetPixel
-
113.16 ms – SetPixels32
-
88.96 ms – SetPixels
-
86.30 ms – SetPixels32NoConversion
-
16.91 ms – SetPixelDataBurst
-
4.27 ms – SetPixelDataBurstParallel
TransferGPUTexture示例
这些是TransferGPUTexture.UpdateTestCase在处理大小为8196的纹理时所产生的编辑器GPU耗时:
-
Blit – 1.584 ms
-
CopyTexture – 0.882 ms
方法及 API 推荐
访问像素数据的方法繁多。同一方法针对每种格式、纹理类型或用法都会有不同的执行成本。本节将介绍其中部分方法。
CopyTexture
CopyTexture 是把 GPU 数据转移到另一张纹理的最快方法 ,它不会执行任何格式转换。如果两张纹理都是可读的,则复制操作会在 CPU 数据上完成,此时该方法的总体成本会非常接近 SePixelData 在 CPU 上的复制,结果则等同于用 GetPixelData 复制源纹理。
Blit
Blit 可以用着色器把 GPU 数据快速转移到一张 RenderTexture 上。实际使用中,Blit 必须设立图形管线 API 的状态才能渲染到目标 RenderTexture。相比于 CopyTexture,它会有一些与分辨率无关的启动成本。默认方法的 Blit 着色器会接受一张输入纹理,将其渲染到目标 RenderTexture 上。如若制定自己的材质或着色器,就可以实现“纹理到纹理”的渲染过程。
GetPixelData 与 SetPixelData
如果只涉及 CPU 数据,GetPixelData 与 SetPixelData(以及 GetRawTextureData)就是最快的方法 。两种方法都接收一个结构(struct)类用于重新解释数据的模板参数。方法本身只需要这个结构来派生出正确的尺寸,倘若不想采用自定义结构来表示纹理的格式,可以直接用 byte。
访问单个像素时,可以定义一套自定义结构与方法。比如,用 ushort 数据类和 get/set 方法获取单条通道上的字节数据,形成 R5G5B5A1 格式的结构。
public
struct
FormatR5G5B5A1
{
public
ushort
data
;
const
ushort
redOffset
=
11
;
const
ushort
greenOffset
=
6
;
const
ushort
blueOffset
=
1
;
const
ushort
alphaOffset
=
0
;
const
ushort
redMask
=
31
<<
redOffset
;
const
ushort
greenMask
=
31
<<
greenOffset
;
const
ushort
blueMask
=
31
<<
blueOffset
;
const
ushort
alphaMask
=
1
;
public
byte
red
{
get
{
return
(
byte
)
(
(
data
&
redMask
)
>>
redOffset
)
;
}
}
public
byte
green
{
get
{
return
(
byte
)
(
(
data
&
greenMask
)
>>
greenOffset
)
;
}
}
public
byte
blue
{
get
{
return
(
byte
)
(
(
data
&
blueMask
)
>>
blueOffset
)
;
}
}
public
byte
alpha
{
get
{
return
(
byte
)
(
(
data
&
alphaMask
)
>>
alphaOffset
)
;
}
}
}
以上代码以 R5G5B5A5A1 格式表示了一个像素数据(省略了相应的属性设定字段)。
SetPixelData 可以把整个 mip 级别的数据复制到一张目标纹理上。GetPixelData 所返回的 NativeArray 会指向 Unity 内部 CPU 纹理数据的一个 mip 级别,实现 不必复制任何像素就能直接读写数据 。
缺点在于,GetPixelData 返回的 NativeArray 只能保证在调用 GetPixelData 的用户代码将控制权返回给 Unity 之前有效,比如 MonoBehaviour.Update 返回时,无法在帧之间存储 GetPixelData 的结果,而必须从 GetPixelData 为要从中访问此数据的每个帧获取正确的 NativeArray。
Apply
Apply 方法会在数据上传至 GPU 后返回结果。makeNoLongerReadable 参数应当尽可能保留为“true”,以方便结束上传后释放出 CPU 的内存。
RequestIntoNativeArray 和 RequestIntoNativeSlice
RequestIntoNativeArray 和 RequestIntoNativeSlice 方法可以异步下载某张纹理的GPU数据到用户指定的(部分)NativeArray。
这些方法会返回一个 request handle 用于检查数据是否完成了下载。它们仅支持有限几种格式,请使用 SystemInfo.IsFormatSupported 和 FormatUsage.ReadPixels 来查看支持的格式。 AsyncGPUReadback 类同样有一个 Request 方法,可以分配 NativeArray。如果需要重复操作,你可以重复使用NativeArray来提高整体性能。
需要小心使用的方法
还有几种特殊方法由于可能会对性能产生重大影响,所以需要谨慎使用:
带底层数据转换的像素访问方法
这类方法能在不同程度上执行像素格式转换。Pixels32 变体是这里边性能最好的,但是如果纹理的底层格式不能完美匹配 Color32 结构,这些方法也会执行格式转换。在使用以下方法时,需要注意像素数量的增长,它们的性能影响会以不同程度显着增加:
快速数据访问方法
GetRawTextureData 和 LoadRawTextureData 是两种只用于 Texure2D 的方法,可处理包含所有 mip 等级原始像素数据的数据组,并将 mip 按从大到小的顺序排序,每个 mip 带有“高度”数量的“宽度”像素值。
虽然能快速让 CPU 访问数据,但GetRawTextureData 有一个操作难点,就是不按模板写的派生方法会返回数据的副本。这种方式不仅更慢,还不能直接操纵Unity管理的底层缓冲区。GetPixelData没有这种特点,它只会返回指向底层缓冲区的NativeArray,该缓冲区在用户代码将控制权返回给 Unity 之前一直有效。
ConvertTexture
ConvertTexture 是一种将纹理的 GPU 数据转移至另一张纹理的途径,源纹理和目标纹理不一定需要有同样的大小或格式。这种转换流程在各个情况下都会发挥最大效率,但它并不便宜。整个内部转换流程是:
-
分配一张匹配目标纹理的临时 RenderTexture。
-
将源纹理 Blit 到临时 RenderTexture。
-
复制临时 RenderTexture 上的转移结果到目标纹理。
以下问题能帮你决定该方法是否适合你的用例:
我需要进行转换吗?
-
我能否保证在导入时能以目标平台需要的大小/格式创建源纹理?
-
我能否在流程里一直使用同一张纹理,把结果直接用作其他流程的输入?
我能否把RenderTexture作为目标纹理?
-
这样转换流程只需一次Blit就能产出目标RenderTexture了。
ReadPixels
ReadPixels 方法会从激活的 RenderTexture (RenderTexture.active) 同步下载 GPU 数据到 CPU 上的 Texture2D。可以用它来保存或处理某次渲染运算的输出。它支持少数几种格式,请用 SystemInfo.IsFormatSupported 和 FormatUsage.ReadPixels 来检查格式支持。
从 GPU 下载数据是一个繁琐的流程。在下载开始前,ReadPixels 必须等待 GPU 完成之前的工作,并只会在请求的数据可用后返回,从而拖累性能。不论从可用性还是性能上说,前边的 AsynGPUReadback 方法都要更好。
转换图片文件格式的方法
ImageConversion 类包含了几种转换图片格式的方法。LoadImage可以将JPG、PNG、EXR(从2023.1开始)加载成Texture2D并把数据上传至GPU。加载好的像素数据视Texture2D原格式可以在运行期间进行压缩。其他方法可以把Texture2D或像素数据组转换成一组JPG、PNG、TGA或EXR数据。
这些方法并不是很快,但可用于在项目里以常见图片格式传输像素数据。常见用法包括从磁盘加载用户头像,与网络上的其他玩家分享。
关键知识点及更多高级资源
Unity图形优化、相关主题及最佳做法有很多的学习资源。文档里的 图形性能与分析 一节就是个很好的起点。
下边我们来总结下需要记住的关键点:
-
在操纵纹理时,第一步是判断出哪种GPU运算能带来最优的性能。关键的考虑因素包括已有CPU/GPU工作负荷以及输入/输出数据的大小。
-
用GetRawTextureData等低级函数在必要时实施特定的转换流程,相比于那些复制(经常没这个必要)并转换数据的便利方法来说要更为高效。
-
更复杂的运算,比如大型Readback和像素计算,只有在异步或并行执行时才在CPU上是可行的。Burst 及 Job System 能让 C# 高效执行一些原本只能在 GPU 上运行的运算。
-
经常进行性能分析:游戏开发经常会出现很多坑,从意想不到的多余到等待其他流程执行造成的停滞。有些性能问题只会在游戏逐渐变大、代码任务变得繁重时显现。在示例项目里,看似细微的纹理分辨率增加就让部分API变成了性能障碍。

分享前沿Unity技术干货和开发经验,精彩的Unity活动和社区相关信息
更多推荐

 0
0 0
0- 0



 已为社区贡献740条内容
已为社区贡献740条内容

所有评论(0)